被字节起诉的田某,拿下今年AI最佳论文奖,戏剧拉满!附论文分析
你好,我是郭震!
NeurIPS,全球最顶级的AI会议,代表当今最顶尖的AI最新研究技术。
能录得一篇这样级别的会议,难度不小。如果再在其中荣获最佳论文,那就相当于登顶珠穆朗玛峰。
今年NeurIPS的最佳论文属于中国研究者,属于北大、字节,其中第一作者是田某:
他或许对大家有些陌生,不过,一提他在今年攻击了字节大模型,他就变得被人所熟知了。
好吧,搞科学的研究员,要想被被普罗大众所知晓,好像得另辟蹊径,比如像田某走的路子。
玩笑了。千万别学!
前段时间被字节索赔800万:
在顶会,获得最佳论文奖,本来如此美好的事情,却被一时冲动,而变得…,令人唏嘘不已。
可谓戏剧拉满!
此文顺便分析下这篇最佳论文,其最大创新在哪里?high-level idea是什么?
光看摘要的前半部分,就知道这篇论文不一般,它提出了一种新的图像生成范式,VAR
VAR是自回归生图模型,通过“下一尺度预测”,这种多尺度的生成方式更贴合人类感知图像的层次性。
而传统的扩散模型都基于“下一像素预测”,进行图像生成。
光凭这点,就知道此论文不一般,具有开创意义,基于下一尺度预测的VAR带来了哪些图像生成效果的优势呢?
优势同样无比明显,可以说相当amazing! 基于ImageNet,低像素向上生成高像素的图像,是有难度的,但VAR生图的清晰度优秀:
优势1:在ImageNet 256×256数据集上的实验显示,VAR的FID达到1.73,远好于基线模型,将近11倍的提升,相当惊艳。
优势2:VAR展示了类似于大模型的Scaling Laws,Zero-shot的泛化能力。如此霸气的泛化能力,所带来的好处也显而易见,为图像修复、扩展和编辑等多任务,带来飞跃。如下,能对图像一顿魔改:
文本:LLM;视觉:VAR,做到与LLM平起平坐,足够见得VAR的举足轻重。
优势3:VAR通过并行生成显著降低了时间复杂度,相比传统自回归模型,生成速度提升了约20倍,也是相当amazing!
能拿到这样的大结果,基于的灵感,也是简单朴素:
不再逐像素预测,
而是逐尺度预测!
如下论文的用词,next-scale prediction 或者 next-resolution prediction:
总结来说:
论文的核心idea,一个词:从粗到细(coarse to fine)
为什么从粗到细,就能取得这样好的结果???
想想人类在感知或创作图像时,是怎样的?
通常是,先把握整体结构(粗略尺度),然后再填充细节(精细尺度)。
VAR就是效仿了这个特点,通过从低分辨率到高分辨率逐步生成图像,与这一感知过程一致,从而提升了生成的自然性和一致性。
先生成整体布局,再在局部进行细化。如下图所示,r1,r2,r3,像素粗糙到看不出是什么,直到细化到rk:
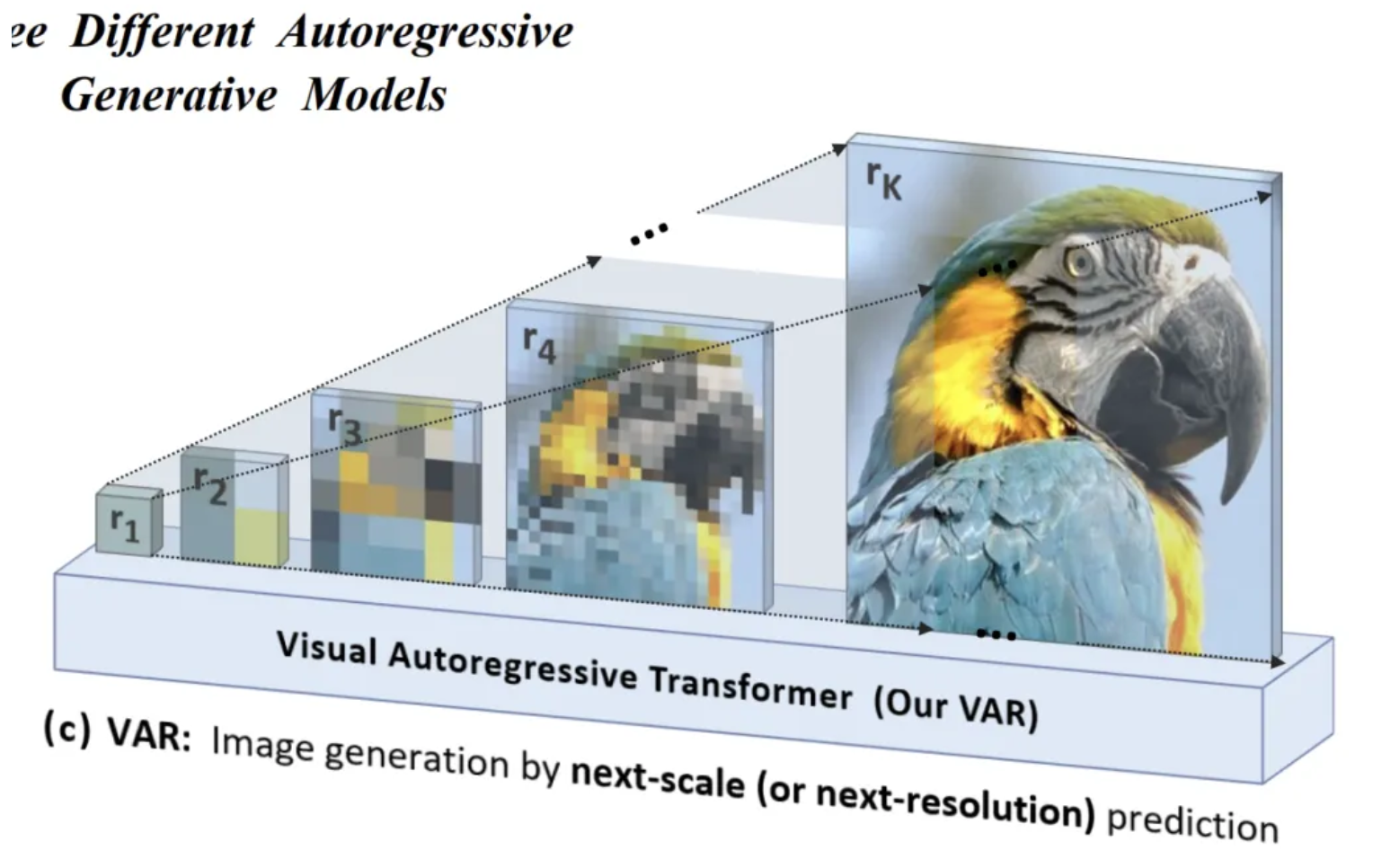
这种是明显区别于(b) AR,下一图像token的自回归方式:
论文展示了VAR 的 scaling laws,如下一共9个子块,每个子块的最右下角块学习的最充分,所以图像最清晰。比如,中间正弦波子块,最右小角的正弦波图像最清晰:
原因就是每个子块的x维度是训练阶段(代表模型训练阶段),y维度是训练层数(代表模型复杂程度,16层,30层等等)
另一个VAR的重要优势,类似于大模型的zero-shot泛化能力,在其身上也能看到展示:
泛化能力强大了后,图像修改起来就易如反掌,可以一顿魔改:
继续一顿魔改:
结论:本是人才,可一个魔改后,成了鬼才!
被字节起诉的田某,拿下今年AI最佳论文奖,戏剧拉满!附论文分析

