黑客帝国要来!只要一张图,就能生成长达1分钟的游戏视频,谷歌最新AI模型相当惊艳
今日谷歌DeepMind发布Genie2,下面是我对此模型的一个基本分析。
这个模型如何玩呢?比较简单,我们只需要输入:
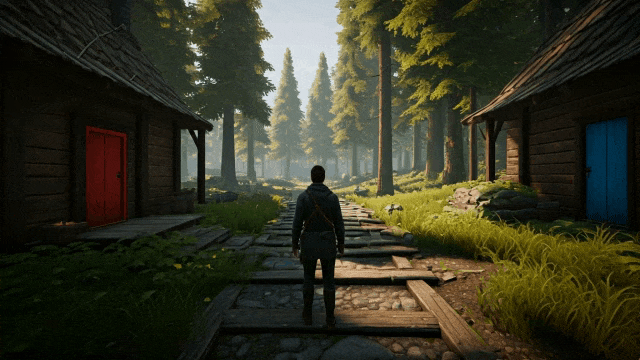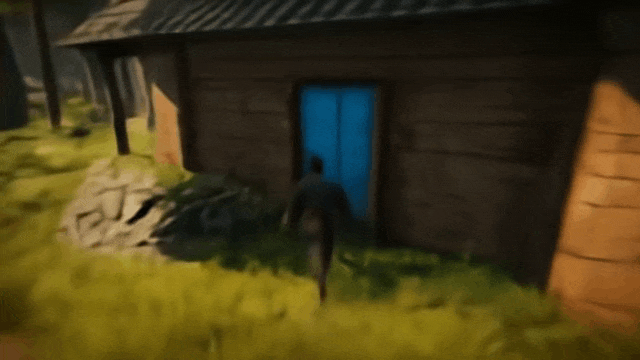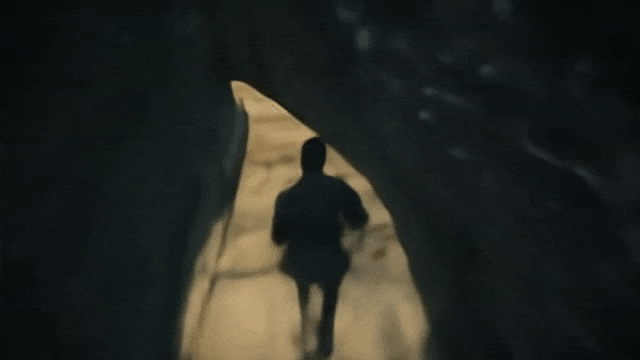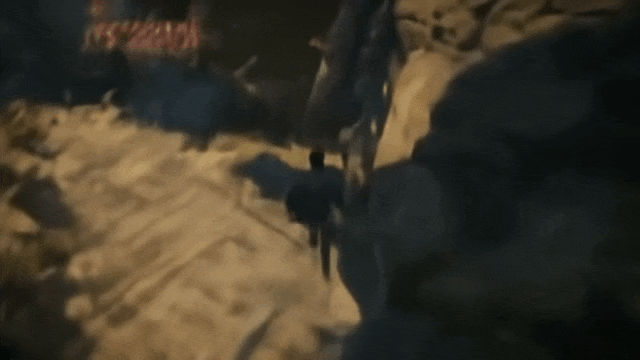
下面一张图+下面一段提示词:

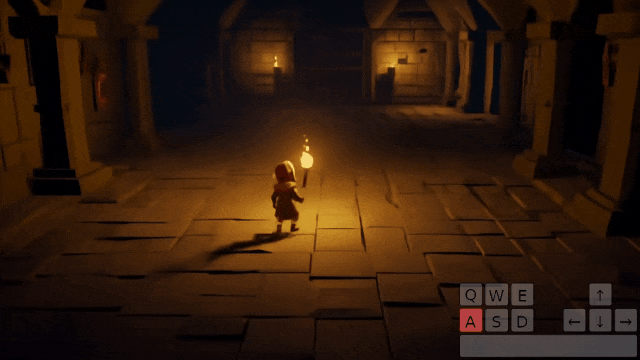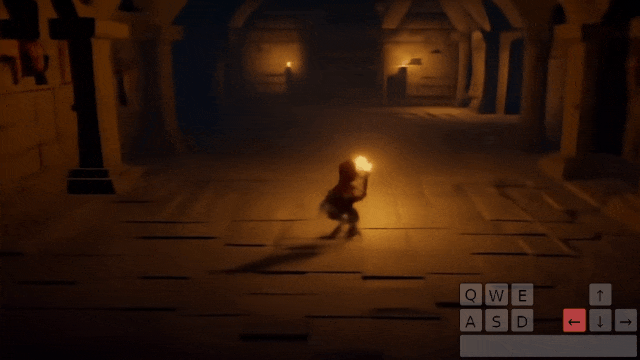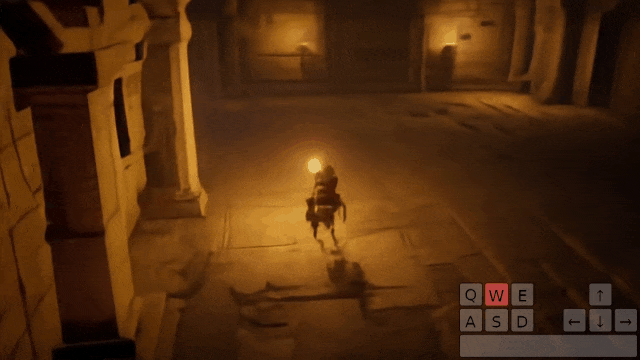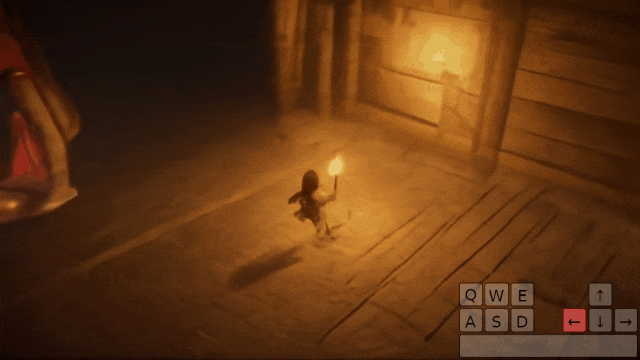
提示词:一个电脑游戏场景,展示了一个粗犷的石洞或矿洞内部。画面采用第三人称视角,镜头从主角后方稍高处俯视。主角是一名手持长剑的骑士,站在三座石砌的拱门前。第一座拱门后,可以看到隧道内生长着散发着荧光的绿色奇异植物,给人一种梦幻的感觉。第二座拱门通向一条长廊,洞壁上布满铆接的铁板,远处隐约透出一种不安的光芒。第三座拱门内是一段粗糙的石阶,蜿蜒向上通往未知的高处,增添了探索的神秘感。
然后模型就会输出下面三段交互视频,注意看:
很有意思!
通过键盘和鼠标我们可以操控游戏玩家通往哪个门:
比如通往第三座拱门:
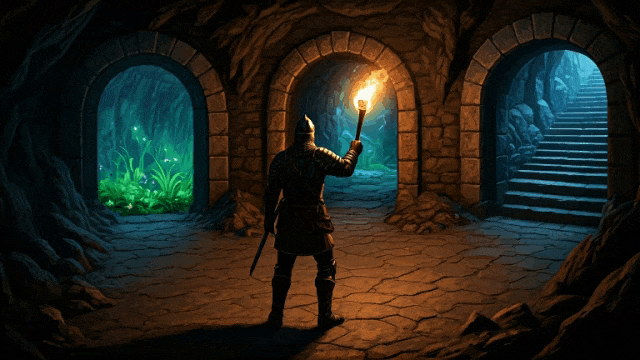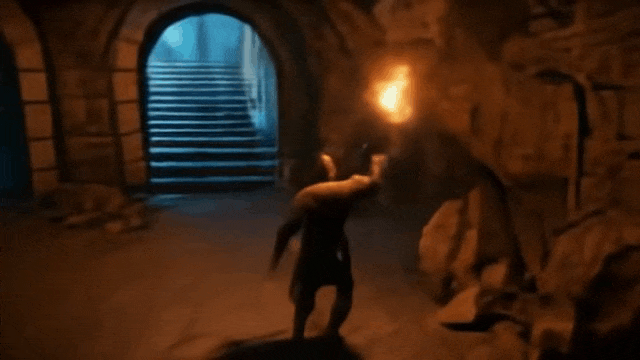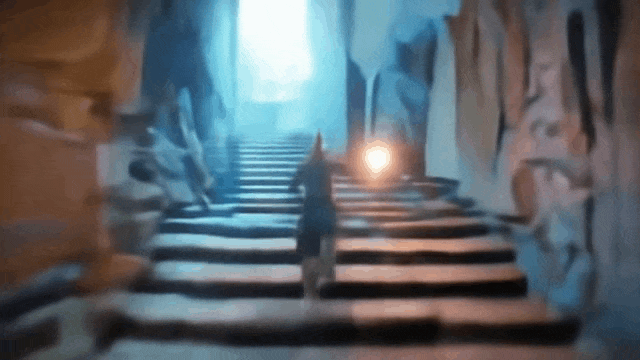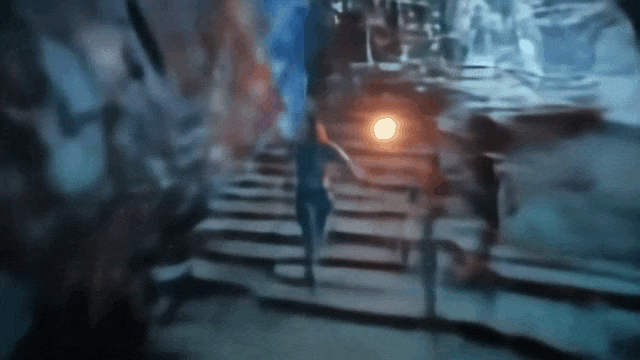
操控玩家进入第一座拱门:
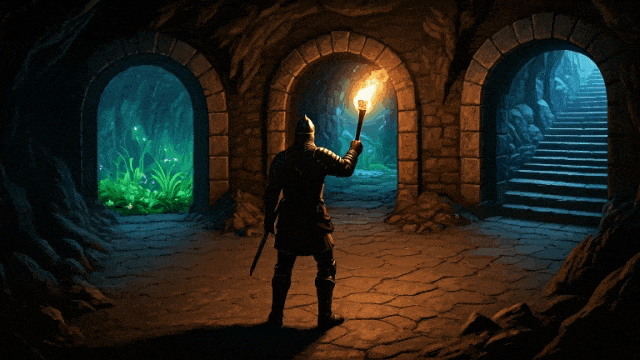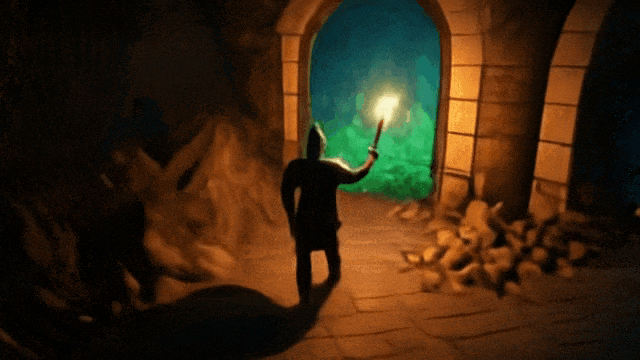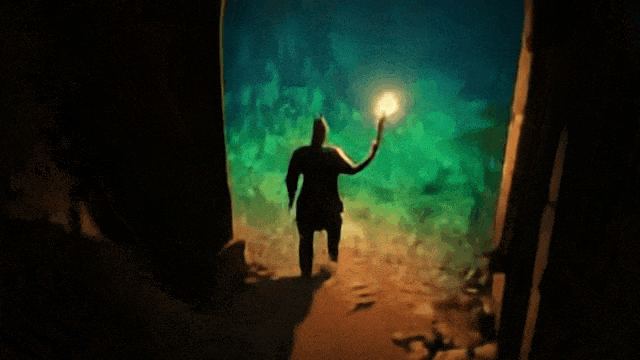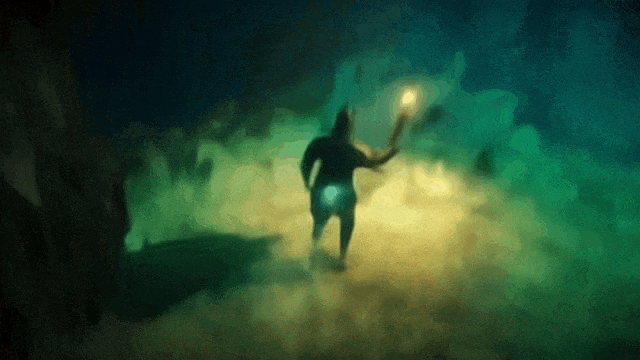
操控玩家进入第二座拱门:

是的,太神奇了,要知道,只需要输入一张图+一段提示词,就能玩到这个高度!
不得不惊叹,这样多种交互效果。
那么,Genie2是个啥样子模型呢?
Genie2 是 Google DeepMind 开发的先进AI模型,能够根据文本或图像提示生成可交互的 3D 虚拟世界。
接下来初步总结Genie2的最大三个特点:
第一,Genie2作为世界模型,能够多视角模拟物理世界。
证明它能够模拟物理世界,几个视频:
1)模拟不同角色、不同姿态的飞行:

2)模拟物理世界的重力效果,仔细看,这效果确实够逼真:

再看这个视频,模拟马起跳又受到重力下降的画面,真的足够逼真了:

模拟物理世界的光源,注意看右下角,代表不同视角看世界:
第二,Genie2不光能够生成视频,更加激动人心的是,它可以和人类交互,这个简直不能再友好了!
再上证据。如下所示,输入:打开每扇门的指令,使用Genie 2生成了一个包含两扇门(蓝色和红色)的3D环境。
接下来它就开始表演了,我们能通过键盘和鼠标来控制游戏角色,而Genie 2负责实时生成游戏画面:
哪些视频可以证明其交互能力?
接着看。
能够通过箭头键,控制移动机器人,这个看起来容易,但是背后实现难度不小,模型需要计算出移动角色,而不是金字塔,

也不是移动树木,而是通过箭头键移动角色:

第三个最大特点,推断并生成一致的潜在动作,具备自主学习和环境理解能力。
看看下面的风吹草动:

看看智能体间的相互建模和学习:



以上,对于每个人类与Genie 2互动的demo,模型仅需要单张图片+提示词输入,
然后就生成了上面的交互视频。
在长达一分钟的时间里,Genie 2可以生成一个一致的世界,持续时间直接长达10-20秒!
生成一个一致的世界长达10-20秒,是很有挑战的。
接下来,任何人都可以用文字描述自己想要的世界,选择自己喜欢的图片,
然后进入这个新创建的世界,并且可以使用键盘和鼠标与之互动,
哇,真的amazing!

难怪有网友留言,直呼:黑客帝国要来:
AGI的到来,看来已经并不遥远了。
Genie 2 已经学了超过 20 万小时的未标注互联网视频,这是一个什么概念?
如果一个人每天坚持观看3小时的视频,完成20万小时的观看量,需要约:
183年
183年,我的天呢!Genie 2还真是个机器。
黑客帝国要来!只要一张图,就能生成长达1分钟的游戏视频,谷歌最新AI模型相当惊艳

