你好,我是郭震
今天教程关于在自己电脑搭建大模型,支持开源的大模型,像主流的通义千问2.5,Llama3,教程还包括如何使用这些大模型做接口调用,实现自动化输出。
如下图所示,这是我自己的电脑安装的两个AI大模型,一个是qwen 7b尺寸,另一个是llama3 8b尺寸:

本地部署大模型有哪些好处呢?
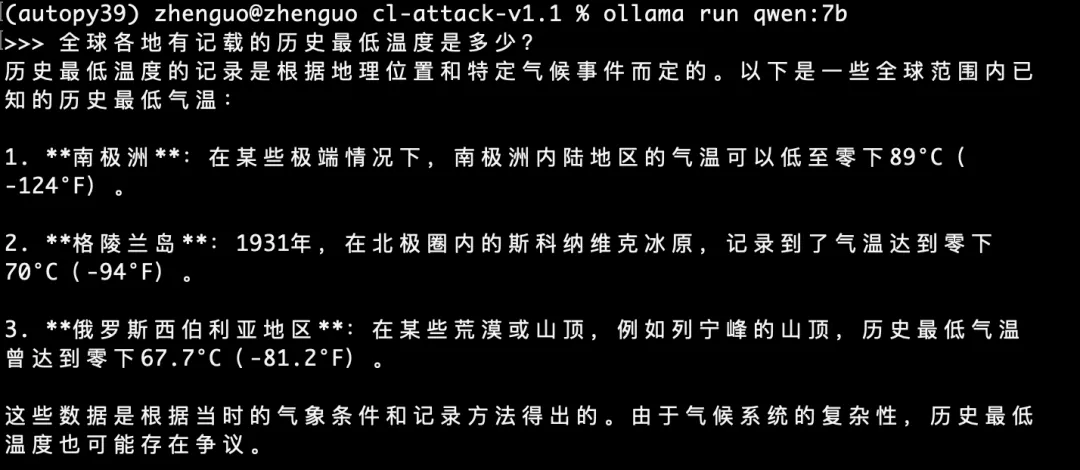
首先,因为这些大模型都是开源的,安装在自己的电脑上也是免费使用的,如下图所示启动qwen7b后,我可以直接在命令窗口提问它,全球各地有记载的历史最低温度是多少?,后面是qwen的回复:
其次,安装大模型在自己电脑除了我们可以直接免费使用它外,还有一个很大的好处,就是我们可以结合自己的私有文件系统,打造一个大模型+个人知识库的AI系统,既保护了个人数据隐私,也让AI「更懂你」。
大模型的一些基本知识科普
可能点进来看我这篇文章的朋友,有不同行业、不同专业的,可能对一些大模型的基本概念不太了解,下面就先做一个基本梳理。
其中比较重要的比如qwen7b, llama8b,这里的7b、8b代表什么?
b是英文的billion,意思是十亿,7b就是70亿,8b就是80亿,70亿、80亿是指大模型的神经元参数(权重参数 weight+bias)的总量。目前大模型都是基于Transformer架构,并且是很多层的Transformer结构,最后还有全连接层等,所有参数加起来70亿,80亿,还有的上千亿。
大模型和我们自己基于某个特定数据集(如 ImageNet、20NewsGroup)训练的模型在本质上存在一些重要区别。主要区别之一在于,大模型通常更加通用,这是因为它们基于大量多样化的数据集进行训练,涵盖了不同领域和任务的数据。这种广泛的学习使得大模型具备了较强的知识迁移能力和多任务处理能力,从而展现出“无所不知、无所不晓”的特性。
相比之下,我们基于单一数据集训练的模型通常具有较强的针对性,但其知识范围仅限于该数据集的领域或问题。因此,这类模型的应用范围较为局限,通常只能解决特定领域或单一任务的问题。
Scaling Laws这个词大家可能在很多场合都见到过。它是一个什么法则呢?
大模型之所以能基于大量多样化的数据集进行训练,并最终“学得好”,核心原因之一是Scaling Laws(扩展规律)的指导和模型自身架构的优势。Scaling Laws指出参数越多,模型学习能力越强;训练数据规模越大、越多元化,模型最后就会越通用;即使包括噪声数据,模型仍能通过扩展规律提取出通用的知识。而Transformer这种架构正好完美做到了Scaling Laws,Transformer就是自然语言处理领域实现扩展规律的最好的网络结构。
知道这些基本知识后,我们回到安装大模型到本地步骤上。一共只需要三步就能做到和大模型在本地会话。
第一步,我使用的是ollama管理各种不同大模型,当然还有其他工具,不过ollama是比较直接、比较干净的,如下所示,一键下载后安装就行了,安装过程基本都是下一步:
不知道去哪里下载的,可以直接在我的公众号后台回复:ollama,下载这个软件,然后装上:

郭震AI
郭震,工作8年后到美读AI博士,努力分享一些最新且有料的AI。
673篇原创内容
公众号
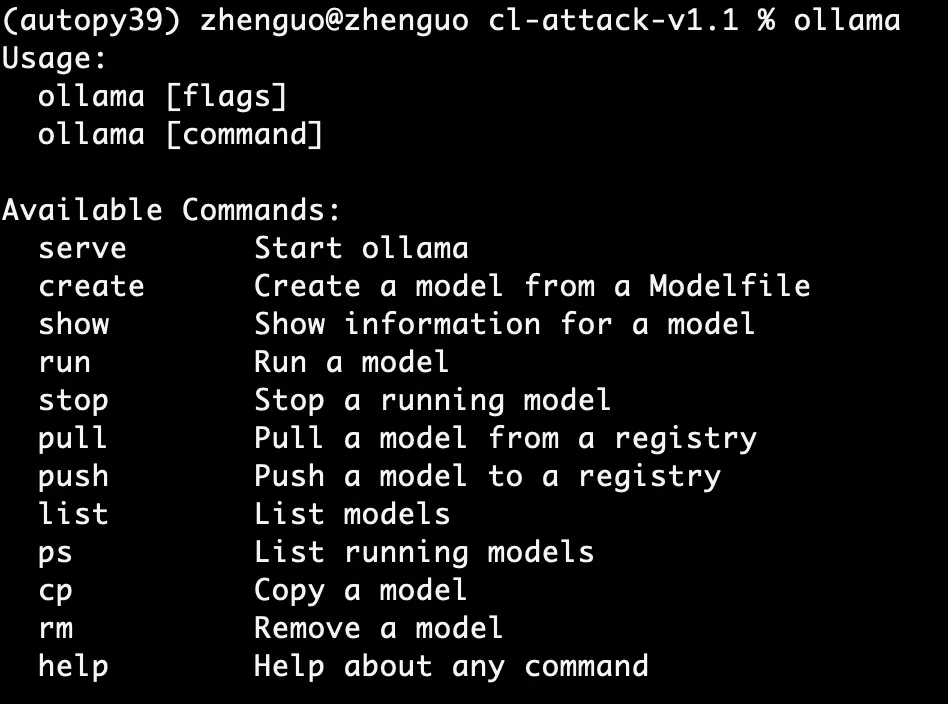
安装后,打开命令窗口,输入ollama,然后就能看到它的相关指令,一共10个左右的命令,就能帮我们管理好不同大模型:
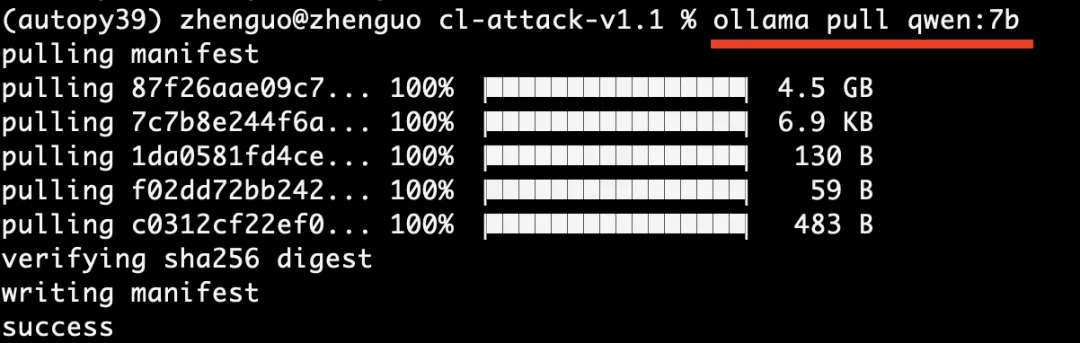
第二步,命令窗口输入:ollama pull qwen:7b,下载大模型qwen7b到我们自己的电脑:
同理,执行 ollama pull llama3:8b,下载大模型llama8b到本地。
ollama list,列举出当前已经安装的大模型:

ollama show qweb:7b,看到模型的基本信息,执行后看到qwen7b模型的基本信息,如下图所示:
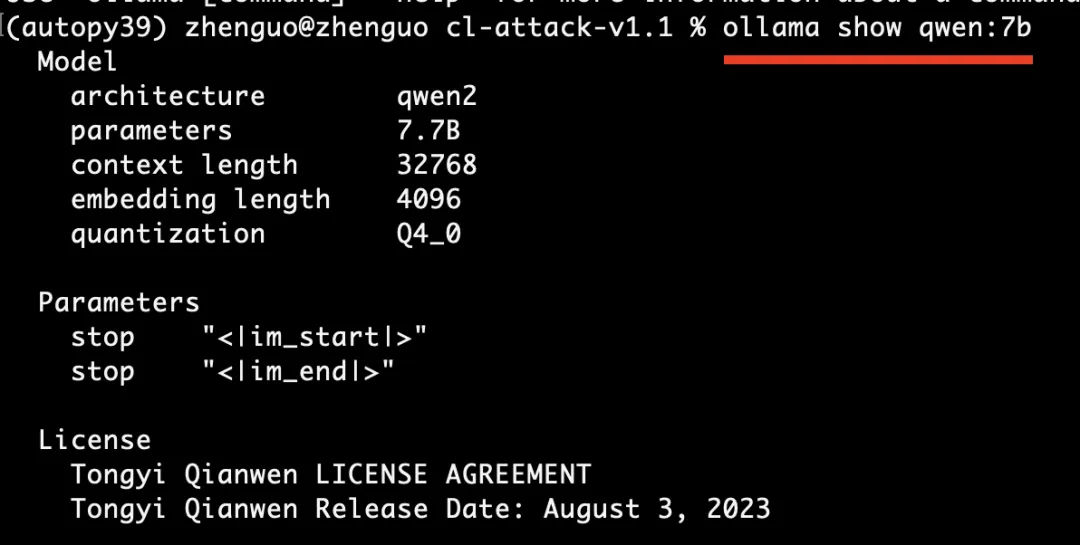
模型的基本信息解释如下:

架构qwen2,7.7b参数,32768的上下文处理长度,4096词向量嵌入维度,Q4_0的四位量化技术。
第三步,ollama run qwen:7b,执行这条命令后,我们就可以和大模型对话了:
如下所示,大模型一般都支持多语言会话:

以上就是本地搭建AI大模型的三个步骤。
接下来,我再介绍一个比较常用的,尤其是想深入一步使用大模型接口做开发的。
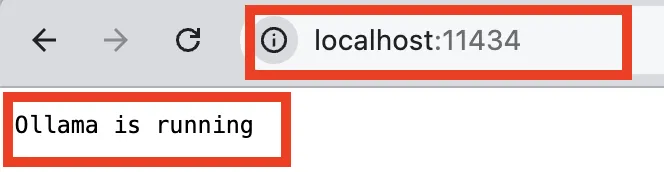
ollama也支持接口开发,它默认的接口是11434,打开浏览器后,输入下面命令,会得到一个字符串输出:ollama is running:
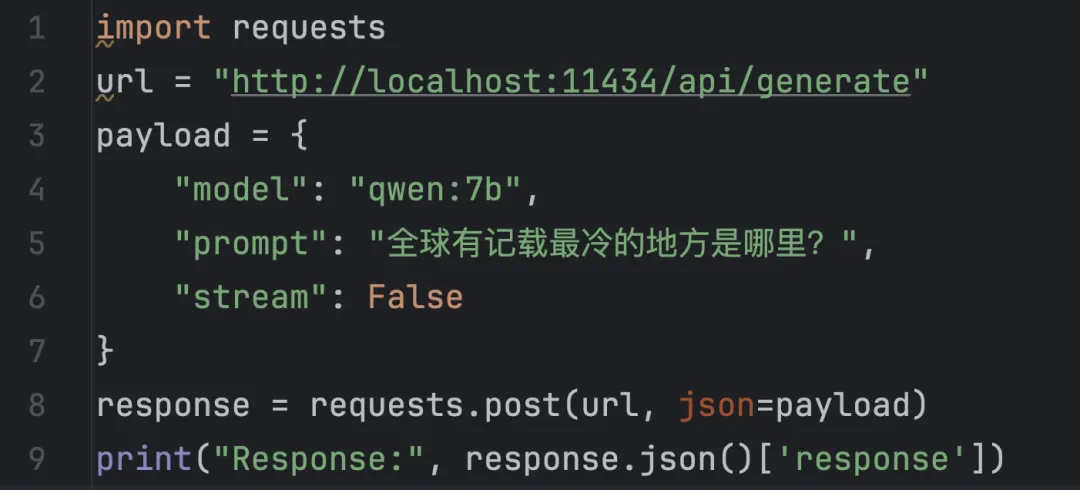
基于上面已经搭建好的ollama+大模型qwen:7b,我们可以编写几行代码,使用ollama的接口,自动执行大模型会话。
非常实用!
具体来说,最精简版代码不到10行,首先pip安装requests包,然后执行下面代码:
自动输出下面的回答:
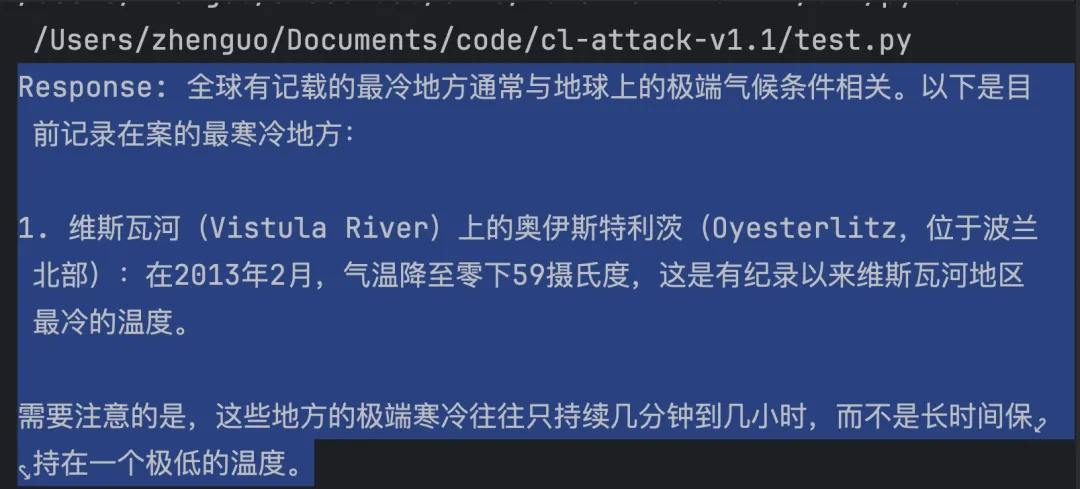
所以,当你有很多任务需要执行时,能通过API调用就会非常省事,自动给你回复,自动给你干活。
上面的url就是API接口的地址,payload是三个必须要传入的参数,使用Python的requests包自动发送请求,然后response得到结果。
以上就是API调用的完整步骤。
总结一下
这篇教程总结了自己电脑搭建大模型的步骤,以及自动调用大模型API的步骤。
最后说一下电脑所需要的配置,一般来说安装上面尺寸的大模型目前电脑都可以,不过大模型回答你的速度会有区别,电脑带有GPU显卡且显存大于等于8G的回答会比较流畅,低于这个配置的就会有些卡顿,但是不至于不能使用。
以上全文2223字,13图。如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个⭐️,谢谢你看我的文章,我们下篇再见!