在上一篇中,我们介绍了如何安装和配置 LangChain 以及项目的基本结构。本篇将深入探索 LangChain 的基本语法和结构,以便为你在下一篇中编写你的第一个 LangChain 程序打下基础。
LangChain 的基本概念
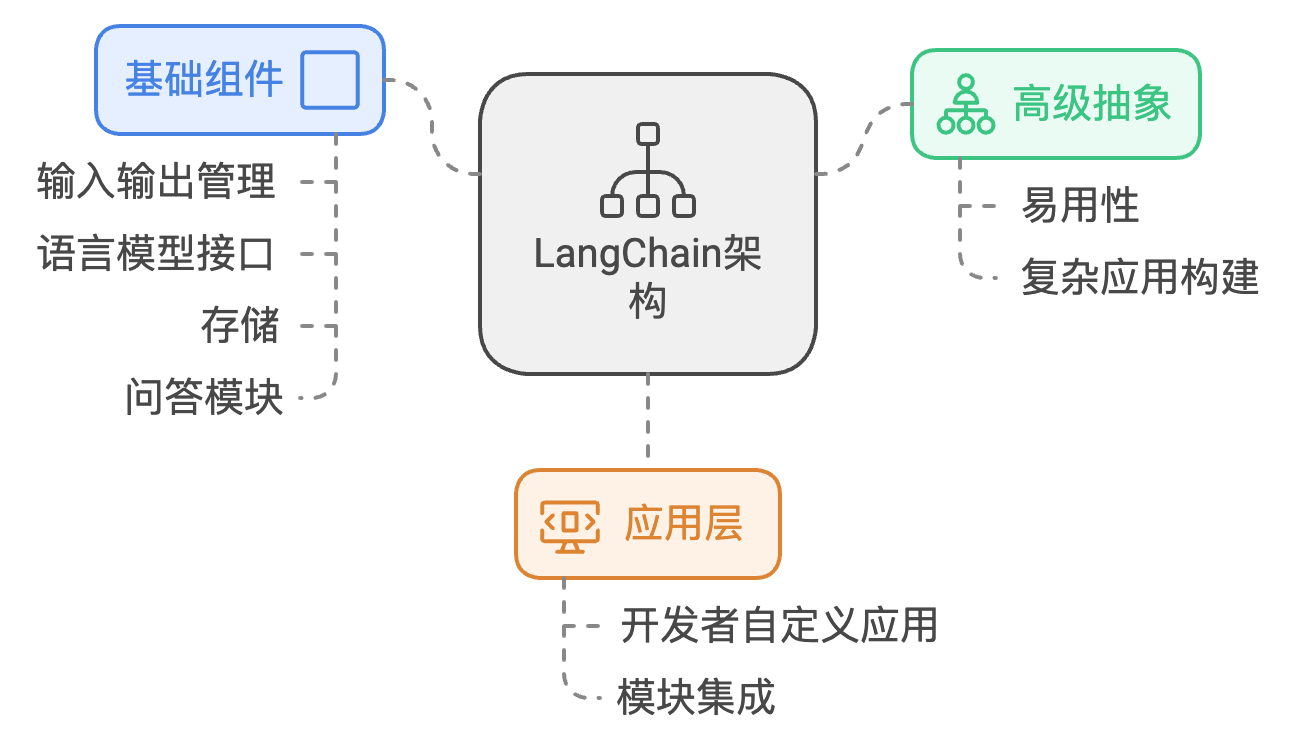
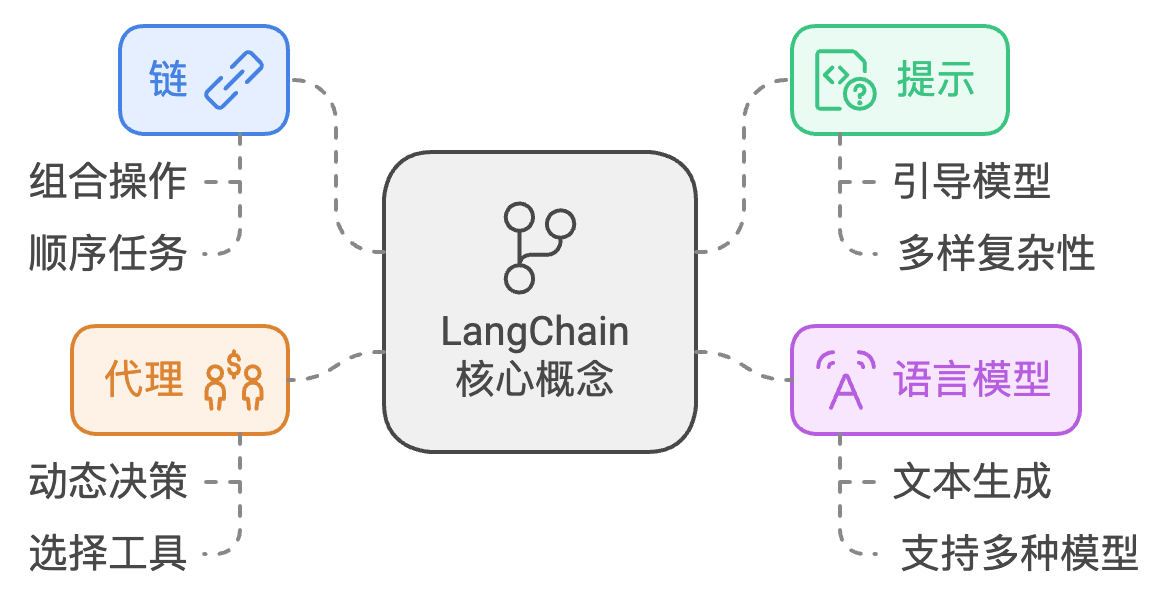
LangChain 是一个用于构建与语言模型交互的框架,它提供了许多工具和组件,使得开发者能够轻松高效地构建强大的自然语言处理应用。以下是一些核心概念:
Chain:链是 LangChain 的核心构建块,它结合了不同的操作或组件,可以按顺序执行一系列任务。
Prompt:提示是指引语言模型生成文本的指令,可以是简单的指令,也可以是复杂的模板。
LLM (Language Model):语言模型是进行文本生成或理解的基础,LangChain 支持多种语言模型。
Agent:代理是一种能够动态决策并选择合适工具以完成任务的组件。
基本语法 在使用 LangChain 时,你会频繁接触到以下几种基本语法结构:
1. 导入库和模块 首先,你需要导入 LangChain 的基本模块,以下是一个例子:
1 2 3 from langchain.llms import OpenAIfrom langchain.prompts import PromptTemplatefrom langchain.chains import SimpleChain
这里我们导入了 OpenAI 的语言模型、提示模板以及简单链。
2. 创建提示模板 使用 PromptTemplate 可以创建一个可以重复使用的提示模板。例如:
1 2 3 4 prompt_template = PromptTemplate( input_variables=["name" ], template="Hello, {name}! How can I assist you today?" )
在这个例子中,我们定义了一个模板,它会插入一个变量 name。
3. 定义链 使用 SimpleChain 可以定义一个简单的处理流程。例如,如果我们要定义一个链,把提示发送给模型并获取响应:
1 2 llm = OpenAI(temperature=0.5 ) simple_chain = SimpleChain(llm=llm, prompt=prompt_template)
SimpleChain创建了一个链,使用了刚才定义的提示模板和语言模型,是将语言模型(llm)和输入模板(prompt_template)连接起来的一个简单链条。
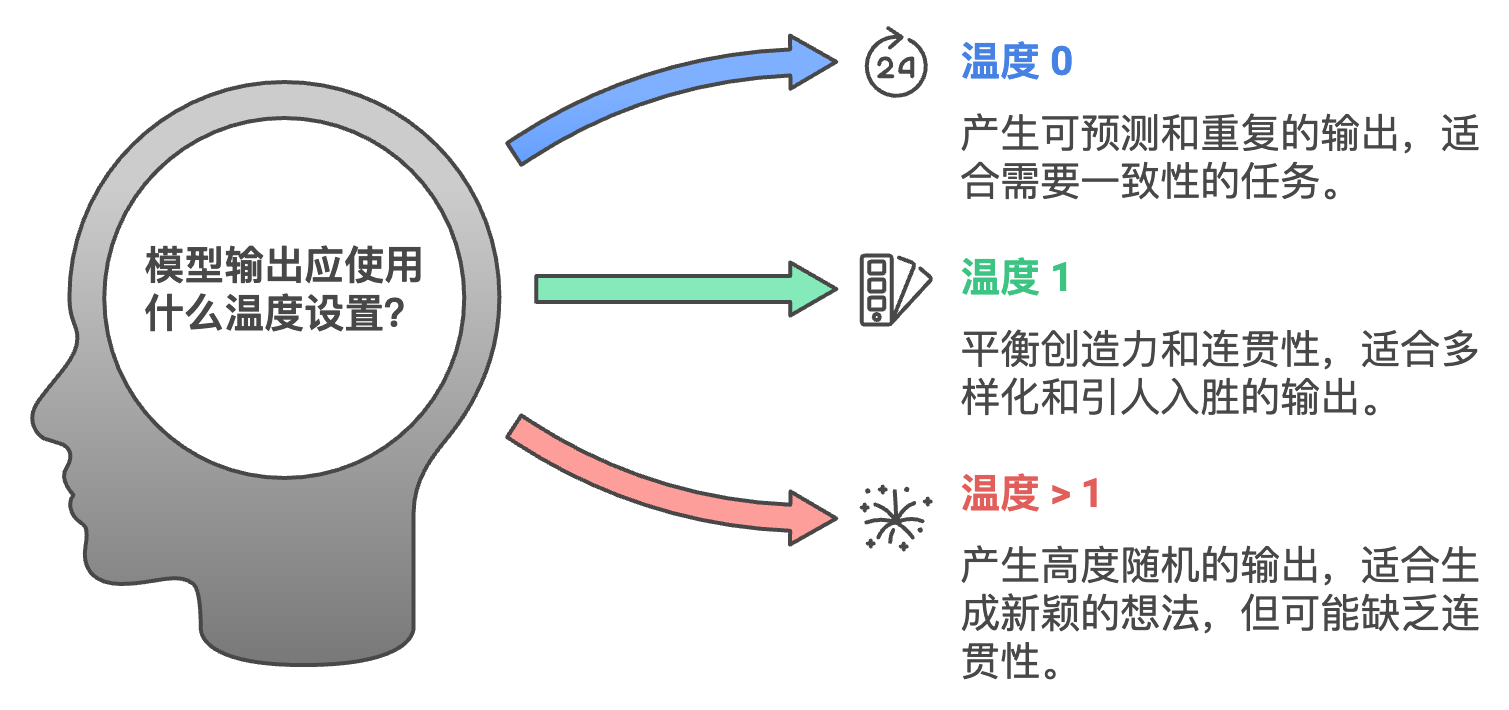
在语言模型(如OpenAI的GPT)中,temperature(温度) 是一个控制模型生成文本时随机性的参数。
温度的作用:
低温度(例如 0.1 到 0.3):模型的输出变得更加 可预测 和 保守。它倾向于选择概率最高的词汇,生成的回答更为确定和一致。这通常会导致输出更正式、准确,甚至有点重复。
高温度(例如 0.7 到 1.0):模型生成的输出变得更加 创意十足 和 多样化。在高温度下,模型更有可能选择较不可能的词汇,从而使输出更加多样化,尽管有时会导致输出的连贯性较差。
温度如何影响输出:
温度 = 0:模型将始终选择概率最高的词汇,这会导致输出非常可预测和重复。
温度 = 1:模型的输出基于真实的概率分布,输出变得更加多样和富有创意。
温度 > 1:这会导致输出更加随机,连贯性较差,因为模型更有可能选择不太可能的词汇。
低温度示例(0.2):
高温度示例(0.8):
1 2 提示: “法国的首都” 回应: “巴黎,尽管有些人可能会认为它是爱情之城,因其艺术、历史和文化而闻名。”
低温度 = 更加可预测、安全的回答。
高温度 = 更加创意、多样化的回答,但不太可预测。
4. 执行链 完成链的定义后,你可以通过调用链的 run 方法来执行它:
1 2 response = simple_chain.run({"name" : "Alice" }) print (response)
run 方法被调用,并传入一个包含 “name”: “Alice” 的字典作为输入。
这个字典中的 “name” 会被用来替换 prompt_template 中的 name 占位符。
在这个示例中,我们传递了一个字典包含了 name 的值为 Alice,语言模型生成的响应将会被打印出来,结果如下所示:
1 "Hello, Alice! How can I assist you today?"
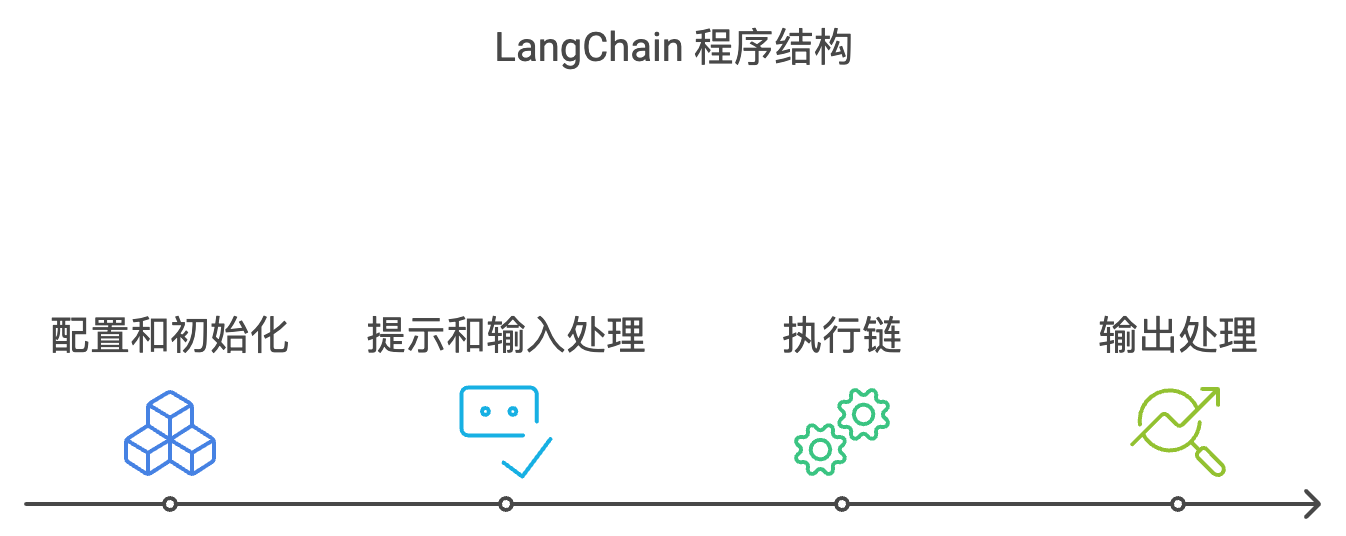
结构理解 LangChain 的结构可以使你易于理解和扩展。
一般来说,一个 LangChain 程序结构如下:
配置和初始化:导入所需模块,初始化模型和链的结构。
提示和输入处理:使用 PromptTemplate 生成提示,接受用户输入。
执行链:通过调用链的 run 方法,执行预定义操作。
输出处理:处理和输出生成结果。
总结 本文介绍了 LangChain 的基本语法和结构,包括如何导入库、创建提示模板、定义和执行链等基本操作。
这些知识将为你在下一篇中编写你的第一个 LangChain 程序奠定坚实的基础。
掌握这些概念后,你将能更自信地使用 LangChain 来构建各种自然语言处理应用。
在接下来的教程中,我们将结合具体案例,引导你创建第一个 LangChain 程序。
敬请期待!