English translation
Integrating DeepSeek with a Personal Knowledge Base Using a Custom Algorithm Framework
AI Article Decision Snapshot
Turn the lesson into workflow, model, budget, and security checks before choosing tools.
Use this quick snapshot before leaving the article. It keeps the next search tied to practical AI software, model/API, cost, privacy, and implementation questions.
Workflow fit
Identify the real job behind the article: coding, research, document review, support, analytics, content, or internal automation.
Model or tool decision
Decide whether the next step is a software shortlist, an AI tool comparison, an API platform choice, or a model benchmark.
Budget and usage signal
Estimate seats, API calls, prompt volume, retries, review time, and fallback work before assuming the workflow is cheap.
Security and privacy review
Check whether source code, customer data, private documents, prompts, logs, or embeddings will enter the AI workflow.

In-house algorithm frameworks are most vulnerable when “in-house development” becomes an end in itself—leading to unnecessary complexity. What truly merits custom implementation is where off-the-shelf solutions fall short in handling your specific document structure, access-control policies, or answer validation criteria. First, clearly define the problem—then decide precisely which components require bespoke implementation.
Start by sketching a data flow diagram: How do documents enter the system? How are they chunked? How are relevant chunks retrieved? How is context passed to the LLM? And how is the final answer evaluated? If this diagram is clear and logically coherent, your subsequent code architecture will naturally remain modular and maintainable.
Over the past several weeks, we’ve focused intensely on improving RAG (Retrieval-Augmented Generation) accuracy for DeepSeek-integrated personal knowledge base software. As of today, our in-house hybrid RAG algorithm is essentially complete—and we’re sharing progress updates and core algorithmic design details with you right away.
1 DeepSeek Knowledge Base Software
Some readers may be encountering this for the first time—so here’s a quick overview.
We’ve been developing a DeepSeek-powered personal knowledge base application that performs entirely local file analysis, eliminating concerns about data leakage. Since it runs exclusively on your own machine, there are no limits on number of files, file size, or upload frequency. Leveraging DeepSeek’s strong reasoning capabilities, this tool enables you to gradually build an AI assistant that deeply understands the contents of your local files—an approach that proves highly practical.
Integrating personal knowledge bases with large language models (LLMs) relies primarily on RAG (Retrieval-Augmented Generation), which synergizes information retrieval with LLM generation to deliver superior summarization and Q&A over personal documents.
Yet retrieving the most semantically relevant fragments from several gigabytes of personal documents—while ensuring both high precision and low latency—is notoriously difficult. Add the constraint that all computation must run 100% locally on a personal computer (many of which lack GPUs), and the challenge intensifies dramatically due to severely limited compute resources.
That’s why most mainstream LLM knowledge base tools—even with just a dozen documents in the corpus—often take minutes to return a response to a simple query. We tested multiple such tools; all exhibited similarly sluggish performance. Slow responses alone would be tolerable—but layer on top complex configuration steps, mandatory vector database installations, and further resource overhead… and many users simply abandon the effort.
Over recent weeks, we’ve systematically tackled these pain points: cumbersome setup, poor usability, and unacceptable latency. Today, our full technical stack has matured.
Preliminary benchmarking on an Apple M1 Mac (CPU-only, no GPU) shows that—while maintaining high answer accuracy—query response times have reached sub-second latency, representing over a 20× speedup versus prior approaches.
To substantiate this claim, here’s a log excerpt pulled directly from the backend, showing timestamps and processing stages:
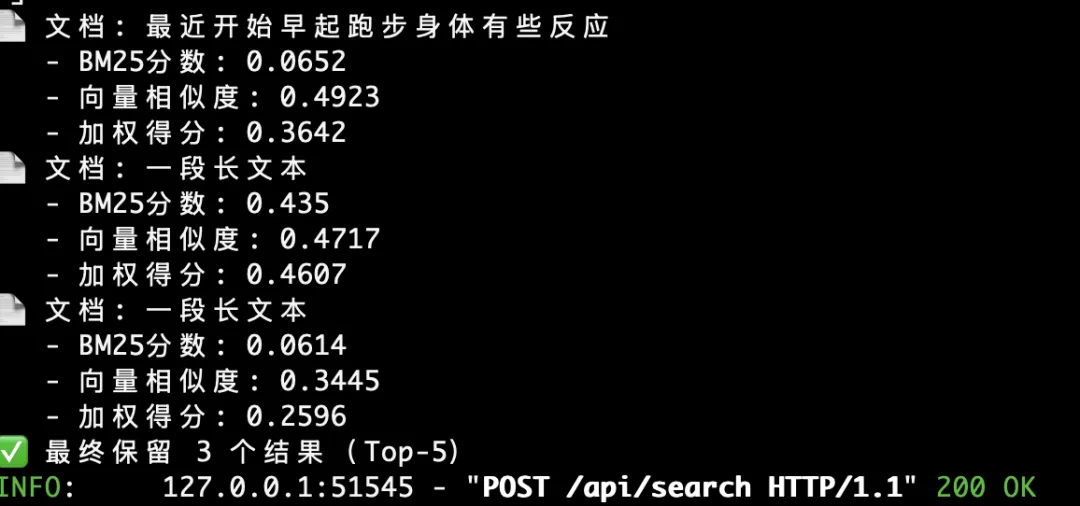
This week, we’ll release v0.6 as a one-click installer: ready-to-run, fully open-source, and completely free.
2 DeepSeekMine Algorithm Framework
Our DeepSeek + personal knowledge base software is branded DeepSeekMine. Many readers have asked about its underlying algorithms—so for clarity, we refer collectively to its retrieval logic as the In-House Hybrid RAG Algorithm.
Below is a detailed walkthrough. From a business logic perspective, the algorithm pipeline comprises two parallel tracks:
- Document ingestion & preprocessing
- User query processing
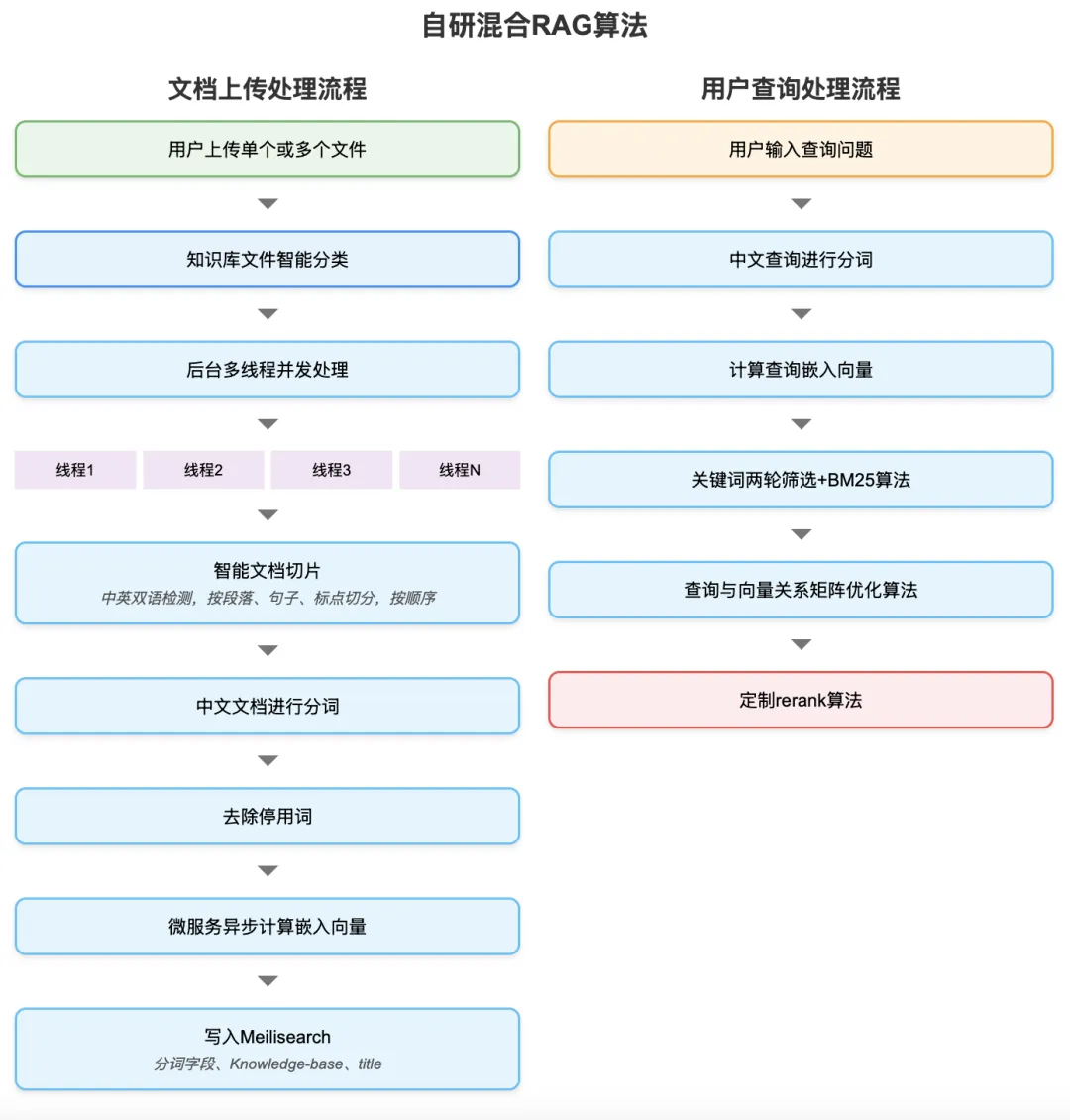
Let’s begin with the document ingestion pipeline—illustrated separately for clarity:
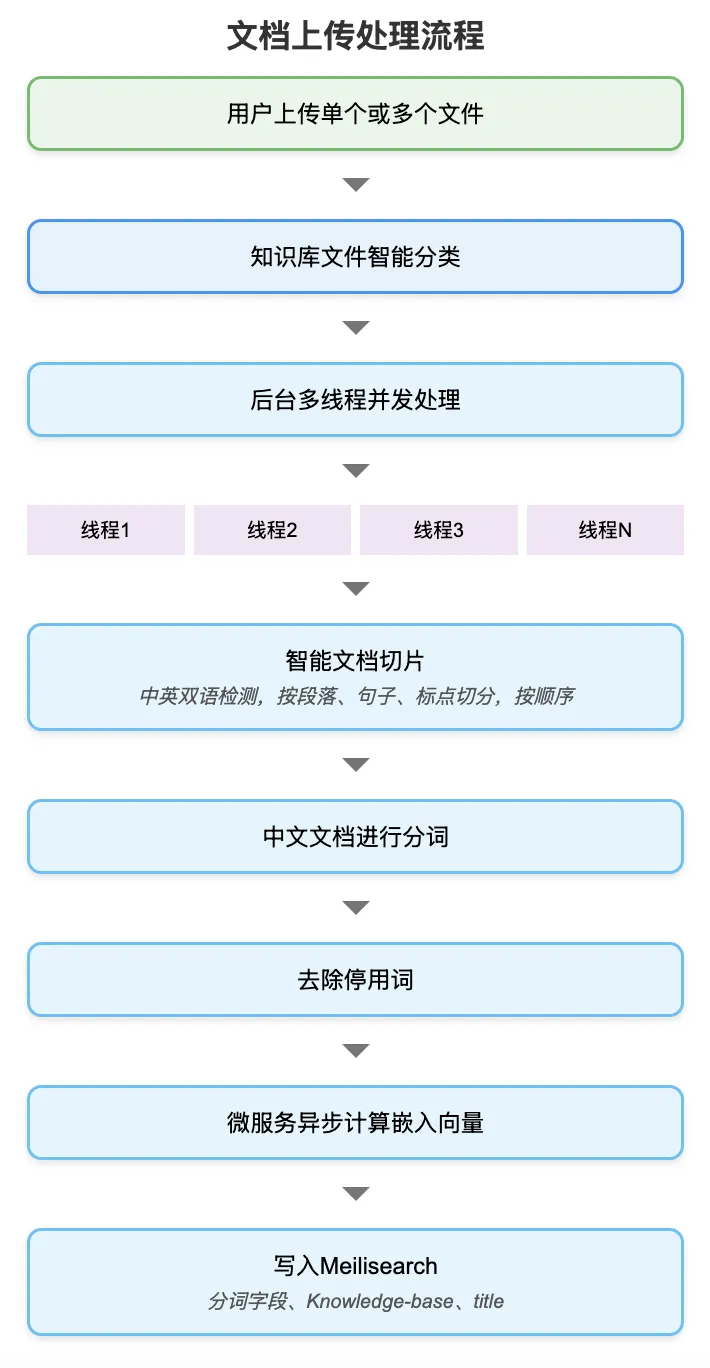
At its core, every computational problem reduces to optimizing time and space complexity. DeepSeekMine v0.6 supports batch uploads of multiple files—and expands support across additional file formats, as shown below:

After uploading multiple documents, intelligent document classification becomes critical—it significantly boosts downstream retrieval efficiency. To accelerate file I/O, we employ multi-threaded concurrent processing. Next, the intelligent chunking module adapts dynamically to Chinese and English text, automatically segmenting documents into semantic units using paragraph boundaries, punctuation, and other linguistic cues—preparing inputs for subsequent embedding computation.
To enable fast keyword-based matching during querying, each document chunk undergoes tokenization, stopword removal, and asynchronous embedding vector computation—before being indexed into Meilisearch, a lightweight, high-performance local search engine. Embedding vectors are generated using a dedicated embedding model (supervised fine-tuning is not yet integrated in this version but is planned for future releases).
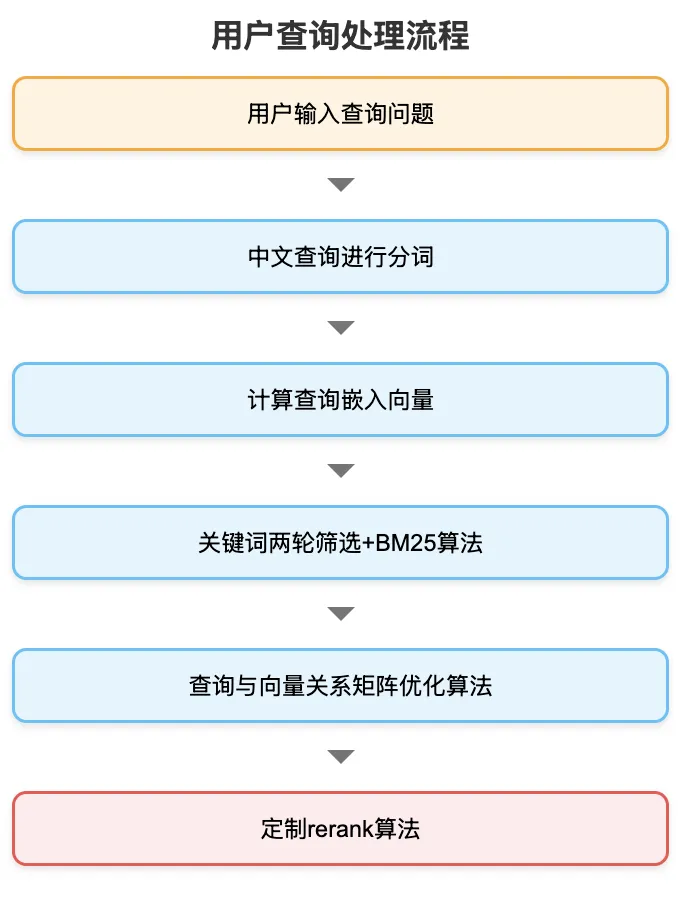
Once files and associated metadata are fully persisted into Meilisearch, preprocessing is complete—and the system enters query mode. To guarantee both high precision and sub-second responsiveness, we deploy three key optimization techniques:
- Two-stage keyword filtering + BM25 ranking,
- Query–vector relationship matrix optimization, and
- Custom re-ranking algorithm,
as illustrated below:
The result is real-time identification of the most semantically relevant document fragments—here, three top-matching segments are returned:
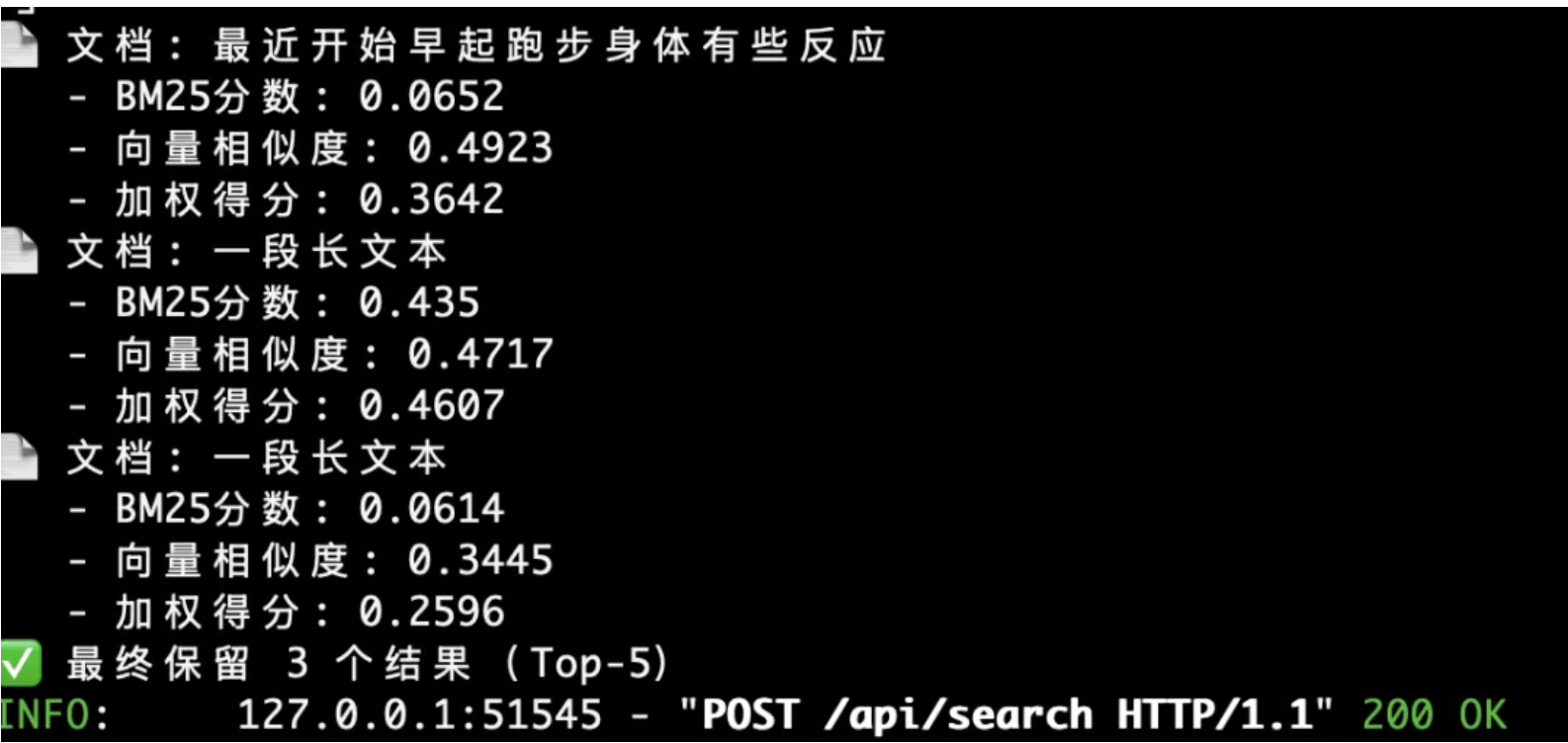
Finally, at the LLM response stage, prompt engineering serves as the decisive “final touch”—a crucial step. Contextual fragments and metadata are fused via carefully designed prompts before being injected into the LLM to generate the final RAG answer:
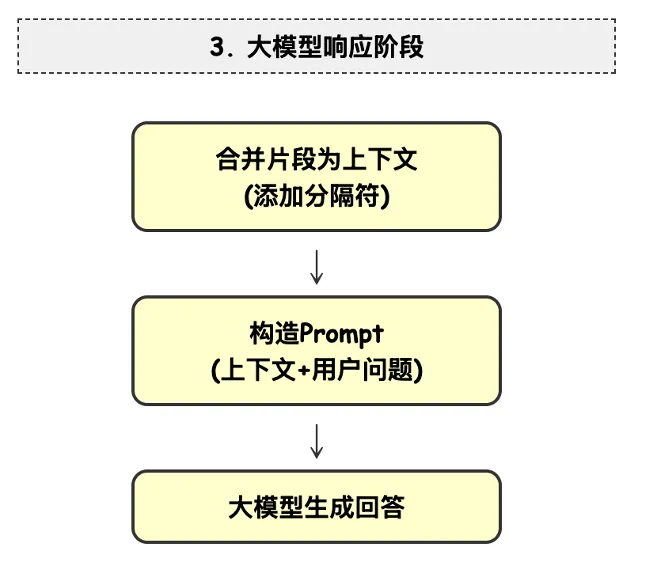
The core prompt template follows this structural outline:

3 Key Differentiators of DeepSeekMine
Based on the framework described above, how does DeepSeekMine compare with alternatives like Tencent’s ima? Here’s a concise summary.
First, ima stores and processes all personal documents in the cloud, whereas DeepSeekMine operates entirely locally. Users unconcerned about privacy may opt for cloud-based tools—but those handling sensitive personal or enterprise documents will prefer DeepSeekMine’s zero-data-exfiltration guarantee.
Second, ima imposes strict file-size limits—for example, capped at 2 GB per file. By contrast, DeepSeekMine performs 100% local analysis, meaning no restrictions whatsoever on number of files, individual file size, or total knowledge base volume.
Third—as noted at the outset—DeepSeekMine was explicitly designed to solve the twin problems plaguing similar tools: minute-scale response latency and complex, error-prone deployment. The upcoming v0.6 delivers real-time, sub-second responses, with zero external dependencies—no vector database installation, no manual configuration.
Lastly, DeepSeekMine is completely free, with no hidden costs or premium tiers.
This article totals 2,398 words and 8 figures. Building robust, user-centric software is no small feat. If you find DeepSeekMine valuable, please consider following us—and giving this post a triple boost: Like, Share, and “Read Original” (View in Feed). Bonus points if you also drop us a ⭐️ on GitHub! Thank you for reading—and see you in the next installment.
Apply This Lesson
Turn this article into AI software, model, API, and security decisions.
English Article FAQ
Use this article as evidence before choosing AI tools
How should I use this AI Tutorials article?
Use it as the implementation or learning layer, then connect the idea to AI software buyer guides, tool comparisons, benchmarks, API choices, and security checks before making a production decision.
Is this English article different from the Chinese original?
The English edition is localized for global AI readers while preserving the original diagrams, screenshots, prompts, code examples, and source context from the Chinese article.
What should I read after Integrating DeepSeek with a Personal Knowledge Base Using a Custom Algorithm Framework?
Continue with AI Software Buyer Guides, AI Tools Workbench, Best AI Coding Agents, AI Model Benchmarks, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
Can this article alone choose an AI product or model?
No. Treat the article as evidence and context, then validate fit with pricing, privacy requirements, integration effort, benchmark results, workflow tests, and fallback planning.
Continue