18 LangChain 进阶应用之性能优化
系列进度
LangChain 入门 · 第 18 / 23 篇
 查看大图
查看大图LangChain 性能问题要先量化。慢可能来自检索、模型、网络、工具调用或解析,不定位就加缓存,容易把错误结果缓存下来。
 查看大图
查看大图我会给每个步骤打耗时日志:retriever、model、tool、parser。超过预期的步骤才值得优化。
在 LangChain 的使用中,性能优化是一个至关重要的主题,尤其在处理大规模数据或进行复杂推理时。上一篇我们探讨了数据处理管道的案例研究,现在我们将深入了解如何通过不同的策略来优化 LangChain 的应用性能。接下来,我们将分享一些实践中的技巧和案例,以确保我们的 LangChain 项目在性能上能达到最佳效果。
1. 理解性能瓶颈
在进行性能优化之前,首先要识别应用中的性能瓶颈。这些瓶颈可能出现在多个地方,包括但不限于:
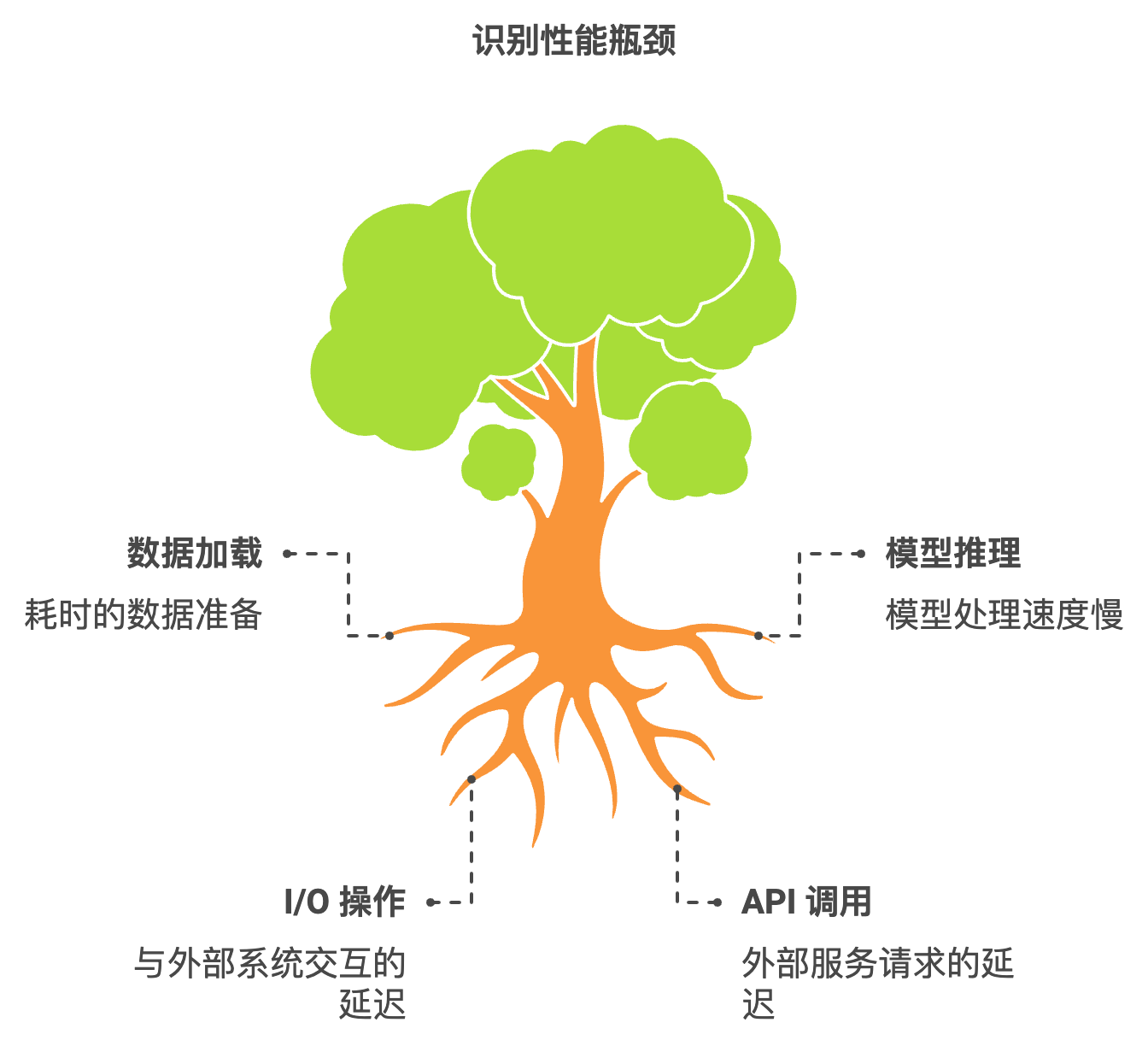 查看大图
查看大图- 数据加载:数据集的加载和预处理可能耗时很长。
- 模型推理:模型的推理速度。
- I/O 操作:与外部系统(如数据库或API)的交互。
- API 调用:调用外部服务的延迟。
案例:性能瓶颈识别
假设我们有一个 LangChain 应用,它从数据库中加载用户数据,然后使用某个机器学习模型进行分类。为了寻找性能瓶颈,我们可以在应用中进行日志记录,捕获每个关键步骤的执行时间:
import time
import logging
def load_data():
start_time = time.time()
# 加载数据的逻辑
end_time = time.time()
logging.info(f"Data loading took {end_time - start_time:.2f} seconds")
def perform_inference(data):
start_time = time.time()
# 模型推理逻辑
end_time = time.time()
logging.info(f"Inference took {end_time - start_time:.2f} seconds")
2. 优化数据处理
当我们识别出数据加载是性能瓶颈时,我们可以通过以下措施来优化它:
使用批量处理
批量处理可以减少数据库查询次数,从而显著提升数据加载效率。例如,使用批量查询技术可以一次性加载更多数据:
def load_data_batch(batch_size=100):
# 假设我们从数据库加载数据
query = f"SELECT * FROM users LIMIT {batch_size}"
# 执行查询并返回结果
缓存
引入缓存机制可以利用已加载的数据来减少重复请求。可以使用内存或磁盘缓存来存储常用数据。例如,使用 functools.lru_cache 实现简单的内存缓存:
from functools import lru_cache
@lru_cache(maxsize=1024)
def get_user_data(user_id):
# 从数据库获取用户数据
pass
3. 优化模型推理
如果模型推理时间过长,可以考虑以下几种优化策略:
模型剪枝与蒸馏
通过模型剪枝和蒸馏,可以减少模型的复杂性,从而加快推理速度。剪枝是去除不重要的权重,而蒸馏则是使用一个大模型训练一个小模型。这一过程通常需要专业知识,但能显著改善性能。
使用异步调用
对于需要调用多个模型的场景,使用异步调用可以优化性能。例如,使用 asyncio 库实现异步推理:
import asyncio
async def async_inference(model, data):
# 异步推理逻辑
return await model.predict(data)
async def main(data_list):
tasks = [async_inference(model, data) for data in data_list]
results = await asyncio.gather(*tasks)
4. 减少 I/O 开销
优化 I/O 操作可以显著提升应用的整体性能。
 查看大图
查看大图学习《LangChain 进阶应用之性能优化》不必一口气吃完所有细节。先挑一个能动手验证的小问题,再顺着图和正文补齐概念。
使用连接池
在与数据库或API交互时,使用连接池可以减少连接建立的开销。例如,使用 sqlalchemy 的连接池:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///example.db', pool_size=10, max_overflow=20)
增量更新
在处理数据时,尽量使用增量更新策略,避免全量更新的数据操作。例如,只更新自上次操作以来发生变化的数据。
5. 性能测试与监控
最后,性能优化是一个持续的过程。在进行任何优化后,都需要测试应用的性能,并做好监控。
基准测试
使用基准测试工具可以定期评估应用的性能。例如,使用 timeit 模块来衡量某段代码的执行时间:
import timeit
execution_time = timeit.timeit('perform_inference(data)', globals=globals(), number=100)
print(f"Executed inference in {execution_time:.4f} seconds")
监控工具
可以使用如 Prometheus 和 Grafana 等监控工具来追踪应用的性能指标,实时监控内存使用、响应时间等。
 查看大图
查看大图学完《LangChain 进阶应用之性能优化》后,不妨换一个自己的场景试一次,重点观察输入、处理和输出是否能对应起来。
 查看大图
查看大图如果想把《LangChain 进阶应用之性能优化》用到自己的任务里,可以先缩小场景,只验证一个最关键的判断点。
结语
在 LangChain 的使用过程中,通过识别性能瓶颈、优化数据处理、减少 I/O 开销,以及进行有效的测试与监控,我们能够显著提升应用的性能。这不仅有助于提升用户体验,还能提高开发效率,为后续的错误处理与调试打下良好的基础。接下来,我们将在下一篇文章中深入探讨 LangChain 在错误处理与调试方面的最佳实践。
相关教程
相关页面
延伸教程
AI 教程列表



相关内容

