English translation
DeepSeek-V3.1 Released: Claims Top Spot Among Open-Source LLMs (Hands-On Review)
AI Article Decision Snapshot
Turn the lesson into workflow, model, budget, and security checks before choosing tools.
Use this quick snapshot before leaving the article. It keeps the next search tied to practical AI software, model/API, cost, privacy, and implementation questions.
Workflow fit
Identify the real job behind the article: coding, research, document review, support, analytics, content, or internal automation.
Model or tool decision
Decide whether the next step is a software shortlist, an AI tool comparison, an API platform choice, or a model benchmark.
Budget and usage signal
Estimate seats, API calls, prompt volume, retries, review time, and fallback work before assuming the workflow is cheap.
Security and privacy review
Check whether source code, customer data, private documents, prompts, logs, or embeddings will enter the AI workflow.
Hello, I’m Guo Zhen.
DeepSeek has just upgraded to V3.1, achieving a remarkable 76.3% score on the Aider programming benchmark—surpassing Claude 4 Opus.
Among open-source large language models (LLMs), DeepSeek-V3.1 once again claims the top spot in programming capability, making it the best open-source programming LLM available today:
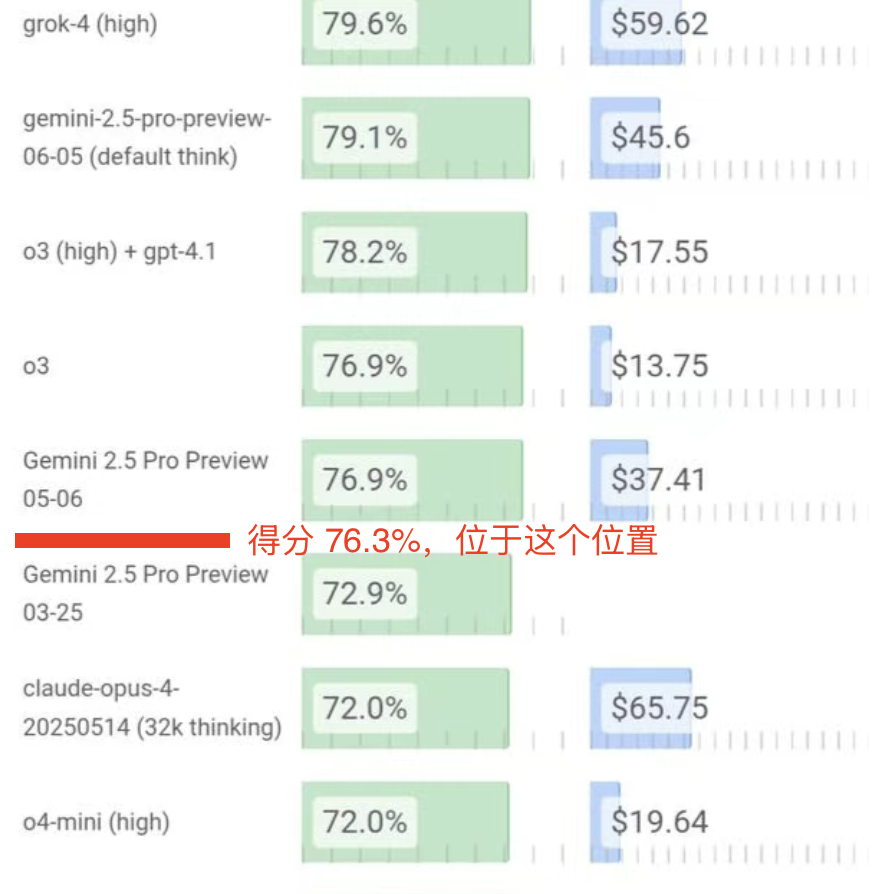
This article offers an accessible summary of how DeepSeek-V3.1 achieved this leap—and includes hands-on testing of its integration into AI agents for programming tasks. If you’re curious, read on.
First, head over to the DeepSeek official website and complete identity verification:

Its responses are clear and precise.
By contrast, when asked “Are you GPT-5?”, GPT-4o replies “Yes”—a clearly incorrect answer:

Accurately identifying itself—especially after multiple model iterations—is surprisingly difficult for LLMs. This self-awareness is foundational for reliable agent behavior.
Evaluating an LLM’s agent capability shouldn’t rely on flashy one-off demonstrations. A more robust approach is to run it through a fixed set of standardized tasks—checking whether it can consistently call tools, maintain context across steps, handle failures gracefully, and explain outcomes transparently.

I break down agent-model evaluation into three categories:
- Pure reasoning tasks (e.g., logic puzzles, math problems),
- Tool-use tasks (e.g., calling APIs, reading files, executing commands),
- Long-horizon tasks (e.g., multi-step debugging, iterative code refinement).
Strong performance in only one category doesn’t mean the model is production-ready for agents. Only models that deliver stable, reliable results across all three deserve integration into real-world workflows.

1 Overall Upgrades
According to DeepSeek’s official announcement, V3.1 introduces three major improvements:
- Dual inference modes: “Thinking” mode (for complex reasoning) and “non-thinking” mode (for fast, direct responses);
- Reduced output token count, while maintaining—or even improving—answer quality;
- Significantly enhanced agent capabilities, marking DeepSeek’s first major step into the agent era.
Speed + quality = productivity. This upgrade brings DeepSeek-V3.1’s inference efficiency on par with OpenAI’s models—confirmed by user benchmarks:

Let’s dive deeper into upgrades #2 and #3.
Output Token Reduction — Why It Matters
In “Thinking” mode, V3.1 reduces output tokens by over 20%, yet delivers answers superior to those from its predecessor R1:
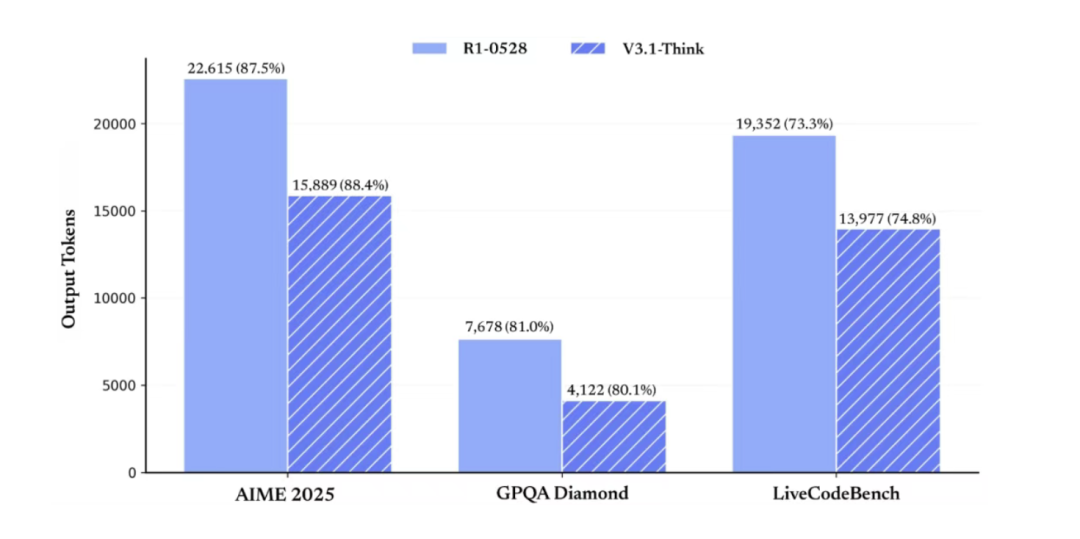
But why does reducing output tokens matter—and how can shorter outputs still be better?
First, clarify: “Fewer tokens” here refers specifically to output tokens—i.e., the final response text—not the internal chain-of-thought (CoT) tokens used during reasoning.
Second, why is generating concise, high-fidelity answers harder? Consider two tasks:
- Task A (original): Write a 500-word movie review—clear thesis, well-supported arguments.
- Task B (compressed): Write a 150-word review conveying equivalent depth and insight.
Clearly, Task B is far more demanding. It requires deeper film understanding, sharper distillation of core ideas, and mastery of economical, precise language—no filler, no redundancy. This tests summarization skill, linguistic fluency, and logical coherence at a higher level.
So how did DeepSeek achieve this? Officially: Chain-of-Thought Compression.
What Is Chain-of-Thought Compression?
Think of it like editing a rough draft into polished prose.
-
Traditional CoT: “John has 5 apples. He eats 2 → 5 − 2 = 3 remain. Then he buys 4 more → 3 + 4 = 7. So the answer is 7.”
-
Compressed CoT (output): “After eating 2, John has 3 left; adding 4 new ones gives him 7 total.”
The training process generates many such compressed reasoning traces, then uses reinforcement learning to jointly optimize for two rewards: ✅ Answer correctness, and ✅ Response conciseness.
This yields outputs that are both accurate and succinct.
But here’s a subtle yet profound point: Why not just reward output brevity directly? Why go through the extra step of compressing the reasoning trace itself?
Because CoT compression is smarter, more stable, and more effective than direct brevity optimization—it avoids the fundamental pitfalls of “reward hacking,” where models learn to cut corners or omit critical reasoning steps just to shorten output.
Let’s verify this in practice. On the official demo site, ask a question without enabling DeepThink mode. The response is fully complete—and notably more concise:

As highlighted in red below, the final summary reads naturally—human-like, not robotic:

Now enable DeepThink mode, and observe how its internal reasoning chain becomes dramatically leaner:
2 Stronger Agent Capabilities
DeepSeek’s focus on agent functionality confirms a broader industry shift: the next frontier of AIGC is agentic intelligence.
In coding-agent benchmarks, DeepSeek-V3.1 decisively outperforms its own predecessors—R1 and V3—achieving a comprehensive self-upgrade:
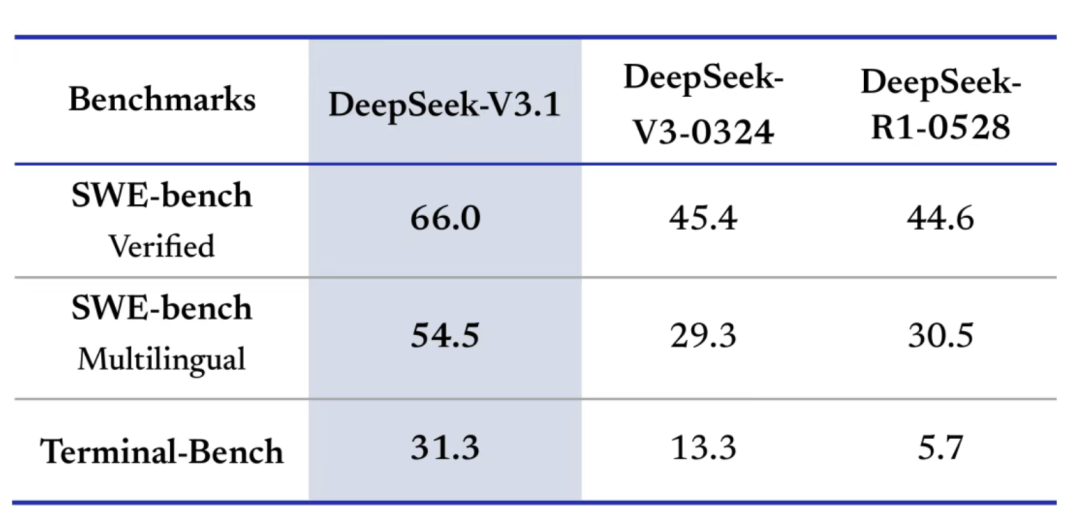
A quick note on these benchmarks:
- SWE (Software Engineering Agent Benchmark) evaluates how well an agent completes end-to-end software development tasks—from understanding requirements to writing, testing, and debugging code.
- TerminalBench assesses programming ability in command-line environments—e.g., interpreting error logs, navigating file systems, running shell commands.
V3.1 also shows massive gains in search-agent capability, excelling at web-based information retrieval and synthesis.
So—what does this actually mean for users and developers?
When an LLM serves as the “brain” of an agent, improved reasoning, tool use, and contextual awareness make the entire agent system more capable. DeepSeek-V3.1 empowers developers to build agents that are: 🔹 More powerful (handle harder tasks), 🔹 More reliable (fewer hallucinations, better error recovery), 🔹 More intelligent (maintain state, reason stepwise, explain decisions).
Concretely: V3.1 reduces tedious back-and-forth confirmation loops between user and agent. It grasps intent faster, diagnoses issues more accurately, and proposes correct solutions earlier—streamlining the entire interaction.
3 Hands-On Agent Experience
Let’s now experience DeepSeek-V3.1’s agent capabilities firsthand. As announced, it integrates seamlessly with Claude Code, Anthropic’s open-source coding agent framework. Here’s the full walkthrough.
Step 1: Install Claude Code globally
Open your terminal (macOS/Linux) or Command Prompt/PowerShell (Windows), then run:
npm install -g @anthropic-ai/claude-code
Step 2: Configure environment variables
Set up DeepSeek as the backend provider:
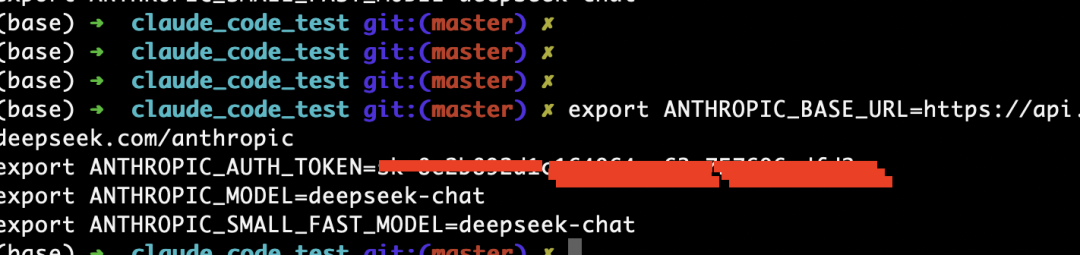
Run these commands (replace DEEPSEEK_API_KEY with your actual API key):
export ANTHROPIC_BASE_URL=https://api.deepseek.com/anthropic
export ANTHROPIC_AUTH_TOKEN=DEEPSEEK_API_KEY
export ANTHROPIC_MODEL=deepseek-chat
export ANTHROPIC_SMALL_FAST_MODEL=deepseek-chat
💡 On Windows PowerShell, use
$env:instead ofexport.
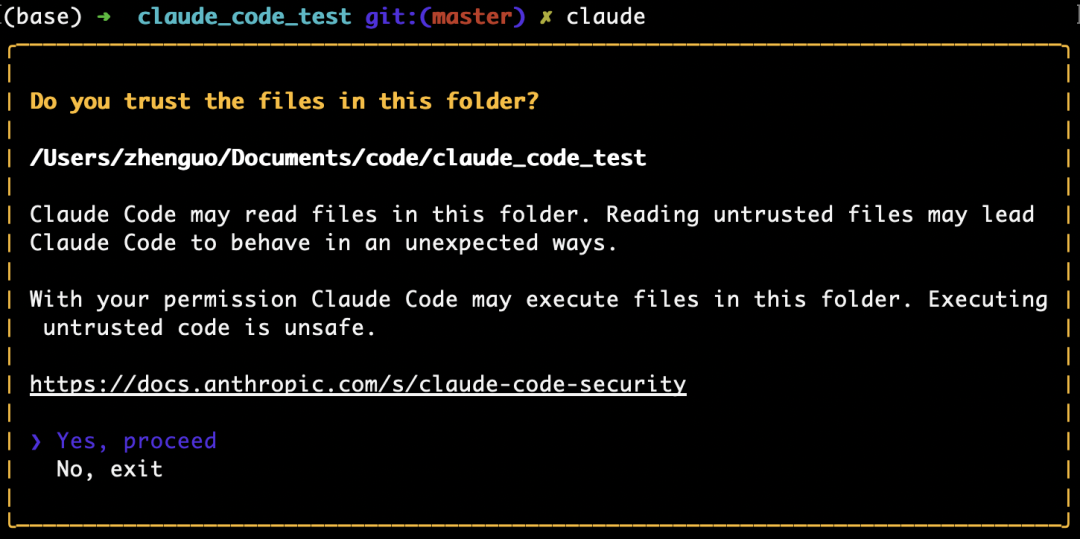
Step 3: Launch the agent
Navigate to your project directory and run:
claude
Now ask it to analyze a buggy Python file. Initially, you may see an error:

This occurs if your API key contains stray {} characters—simply remove them and retry.
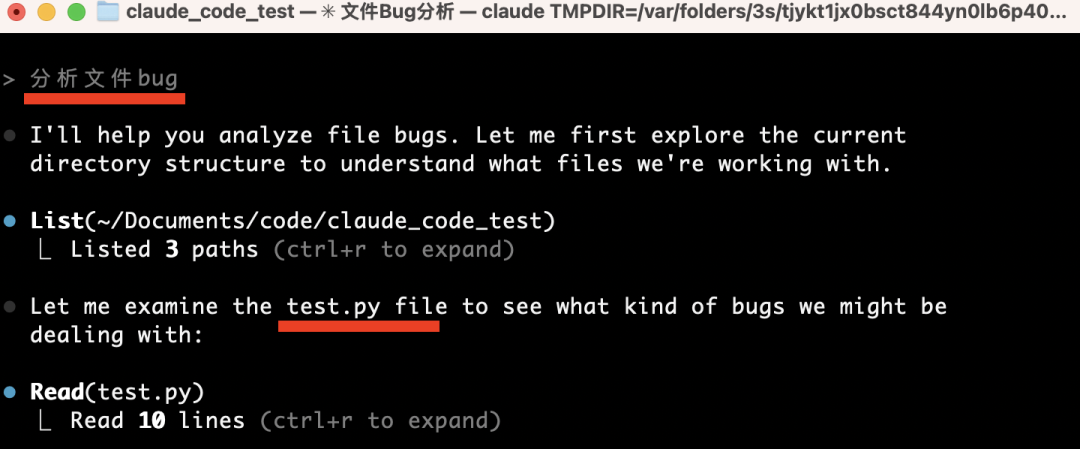
Next, prompt: “Analyze the bug in test.py.”
The agent automatically reads the local file and identifies test.py:
It pinpoints the exact bug:
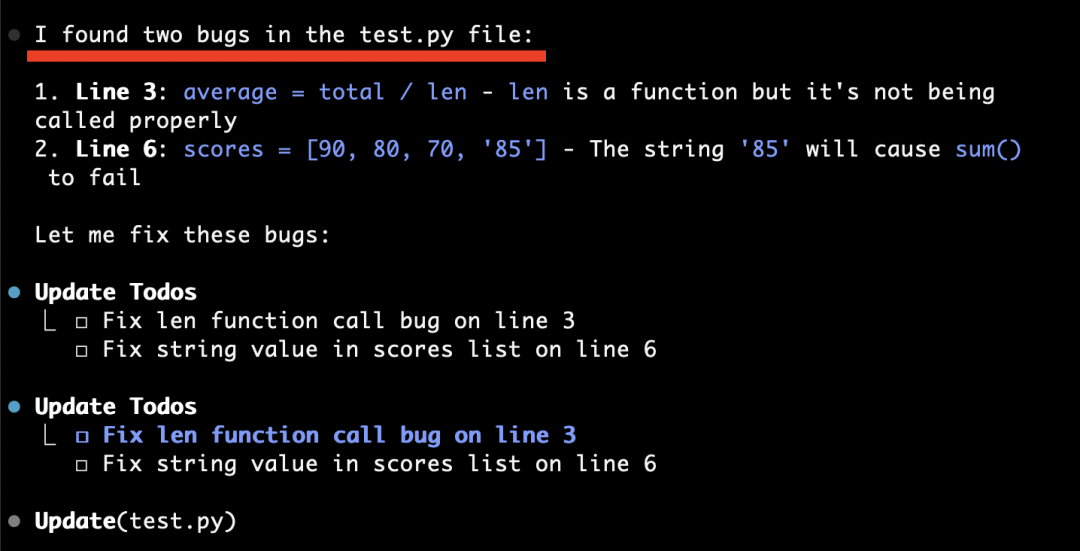
Then locates the faulty line:
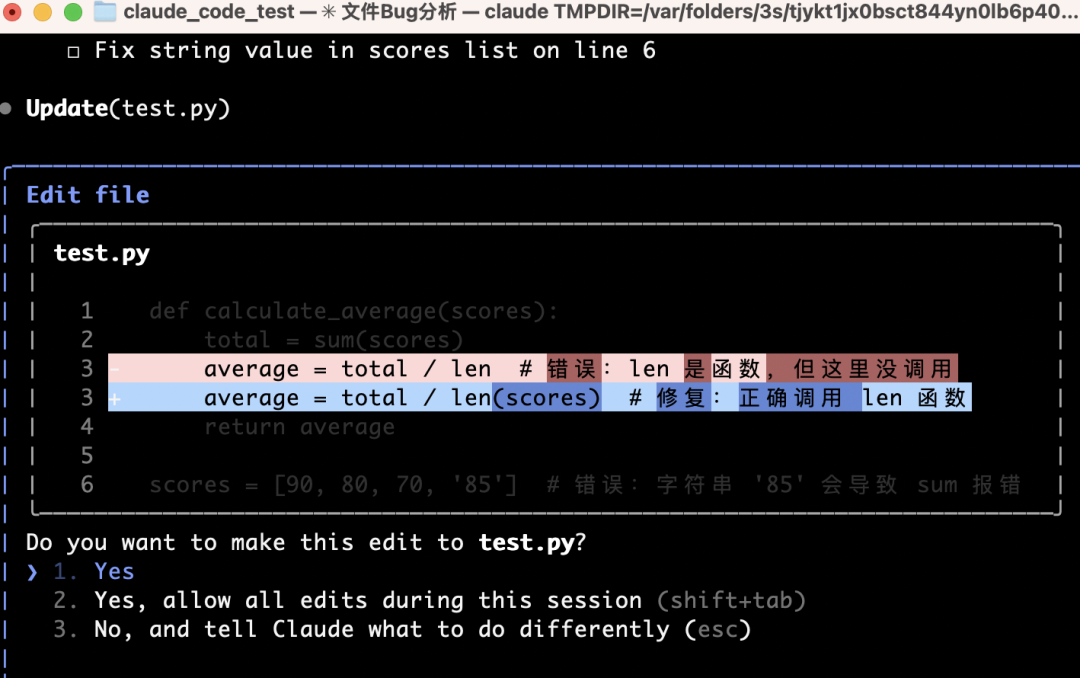
It asks whether you’d like to edit test.py. For now, decline—then request a Chinese explanation:
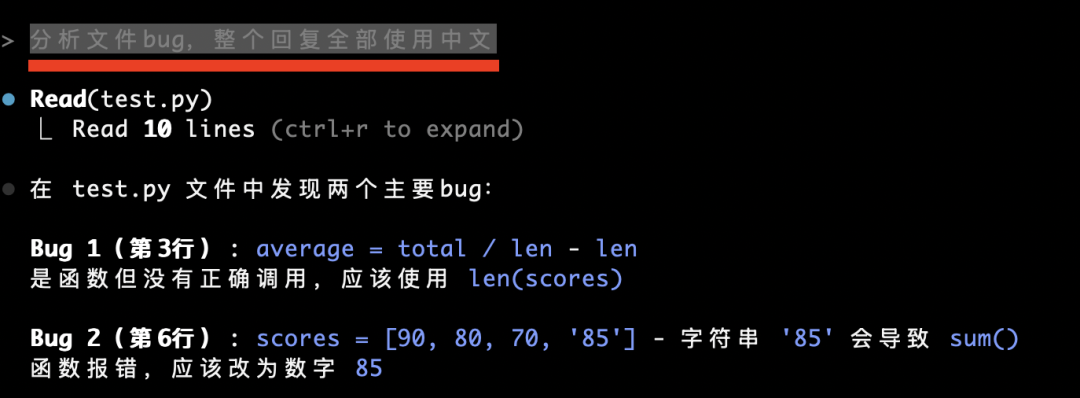
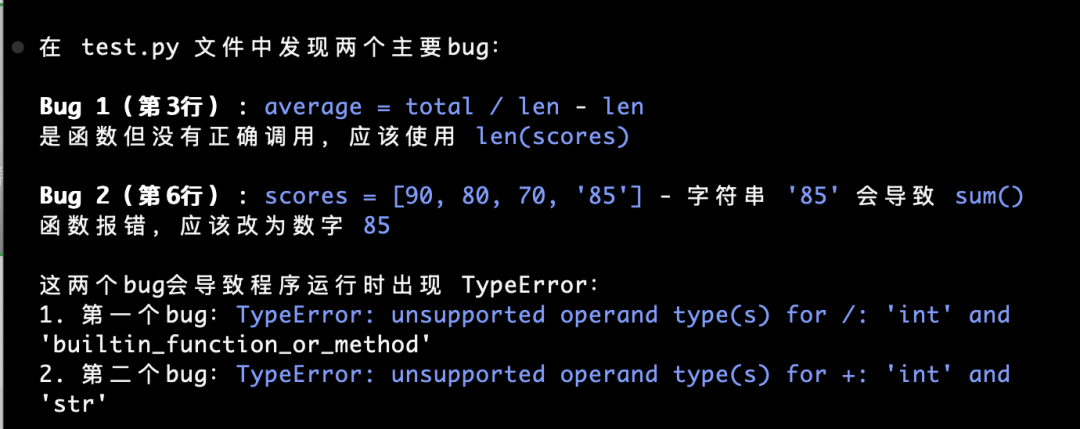
All subsequent replies appear in fluent Chinese:
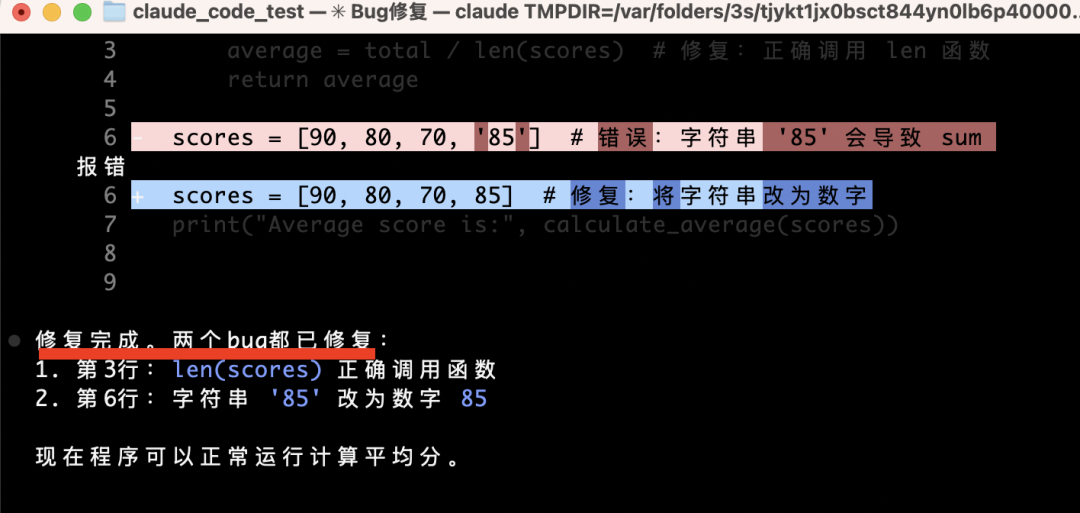
Now ask it to fix the bug:
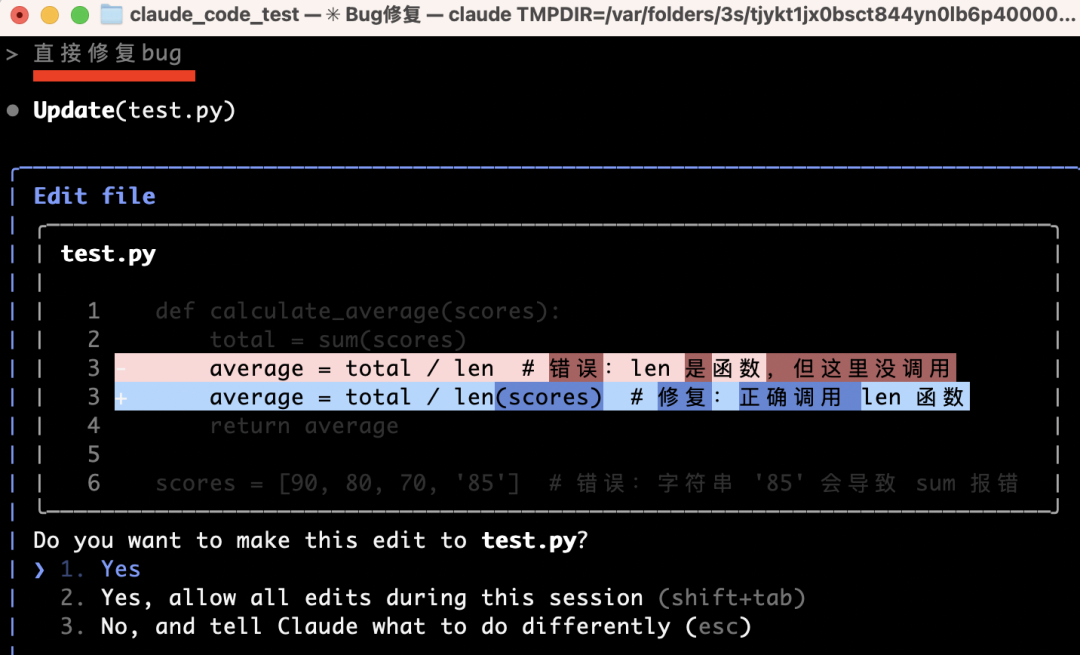
Type 1 (Yes), and it edits the file in place:
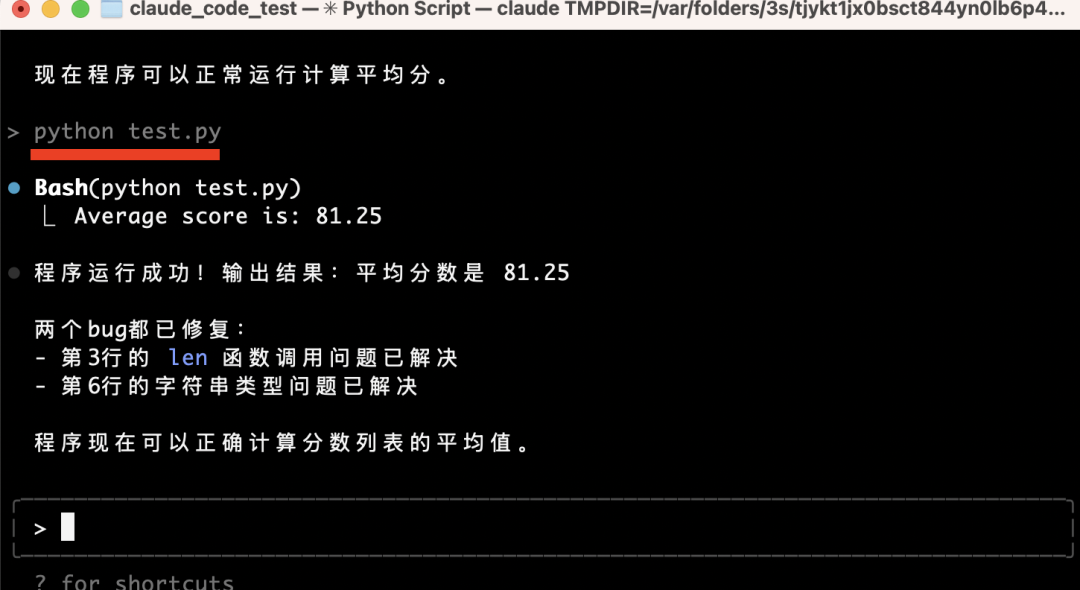
You can even run the script directly inside the agent:
python test.py
Result appears instantly:
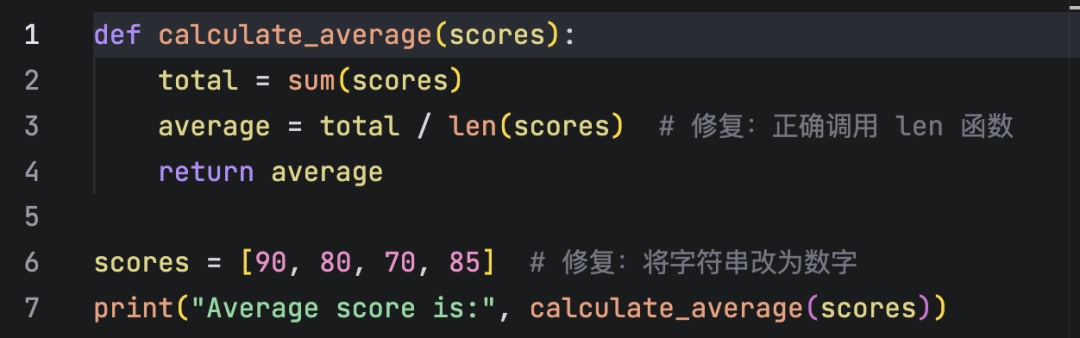
Open test.py in your editor—you’ll find the bug fully resolved, without manual intervention:
That’s DeepSeek-V3.1’s agent power in action: seamless, efficient, and deeply integrated. No copy-pasting. No switching windows. Just natural, conversational coding assistance.
With DeepSeek-V3.1 + Claude Code, fixing bugs becomes fully automated: → Auto-detect file → Auto-diagnose issue → Auto-explain in your language → Auto-edit & validate → All without opening the file.
AI agents aren’t coming—they’re already here. And they’re making code accessible to everyone.
Summary
This article covered DeepSeek’s latest milestone: V3.1, now ranked #1 globally among open-source programming LLMs.
We unpacked Chain-of-Thought Compression—a training paradigm that improves output efficiency without sacrificing accuracy, enabling richer reasoning in fewer tokens.
Finally, we demonstrated V3.1’s real-world agent strength—integrated into Claude Code—to perform end-to-end bug analysis and repair, entirely autonomously.
✅ Total word count: 2,729 ✅ Total figures: 21
If you found this useful: 👉 Follow me for more deep dives, 👍 Like, 🔄 Share, and 👀 Subscribe (WeChat “Watch” button), ⭐️ And consider giving this post a star!
Thanks for reading—and see you in the next one.
Apply This Lesson
Turn this article into AI software, model, API, and security decisions.
English Article FAQ
Use this article as evidence before choosing AI tools
How should I use this AI Tutorials article?
Use it as the implementation or learning layer, then connect the idea to AI software buyer guides, tool comparisons, benchmarks, API choices, and security checks before making a production decision.
Is this English article different from the Chinese original?
The English edition is localized for global AI readers while preserving the original diagrams, screenshots, prompts, code examples, and source context from the Chinese article.
What should I read after DeepSeek-V3.1 Released: Claims Top Spot Among Open-Source LLMs (Hands-On Review)?
Continue with AI Software Buyer Guides, AI Tools Workbench, Best AI Coding Agents, AI Model Benchmarks, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
Can this article alone choose an AI product or model?
No. Treat the article as evidence and context, then validate fit with pricing, privacy requirements, integration effort, benchmark results, workflow tests, and fallback planning.
Continue