又一个开源王炸!是个全能AI,语音对话几乎零延时,确实太赞了!
你好,我是郭震
今天检索「实时音视频交互」相关论文时,搜索到了一篇题目叫LongCat-Flash-Omni技术报告的论文,如下图所示:

再仔细一看,来自美团技术团队,因为多年前就关注了美团技术团队,学习过他们团队不少的技术文章。
同时也注意到两个月前他们发布了LongCat-Flash-Chat大模型:
于是学习了他们最新的LongCat-Flash-Omni模型,发现实力杠杠的,是一个有着极致性能的一体化全模态架构,具有大规模、低延迟的音视频交互能力。
网友发帖说美团Omni超越了Gemini-2.5-Pro:

看到这些很兴奋,这篇文章,咱们就来总结分析下美团研发omni大模型「独特优势」,包括一些实际应用案例,感兴趣的粉丝朋友可以继续阅读。
1 LongCat-Flash-Omni 初体验
首先这个最强的全模态omni大模型是开源的,访问地址如下所示:
进入页面首页,如下所示,具有音频输入能力:
点击如上箭头所示的电话按钮:
我首先语音问它:LongCat-Flash-Omni是一个什么模型?
它的回答延时真的极低,并且回复相当自然,下面是一个我和它语音对话的过程,感兴趣的可以听下:
您的浏览器不支持 video 标签
中间再提问它,响应速度真的很快,这点比GPT的反应要快,AI进化的越来越快了。通话结束语音对话的过程全部自动输出为文本,如下所示:

使用LongCat-Flash-Omni,现在给我的感觉就是,交互起来很丝滑,很舒服。
很好奇为啥这么快?怎么做到如此低延时的?咱们接下来分析下它的技术报告。
2 LongCat-Flash-Omni 技术分析
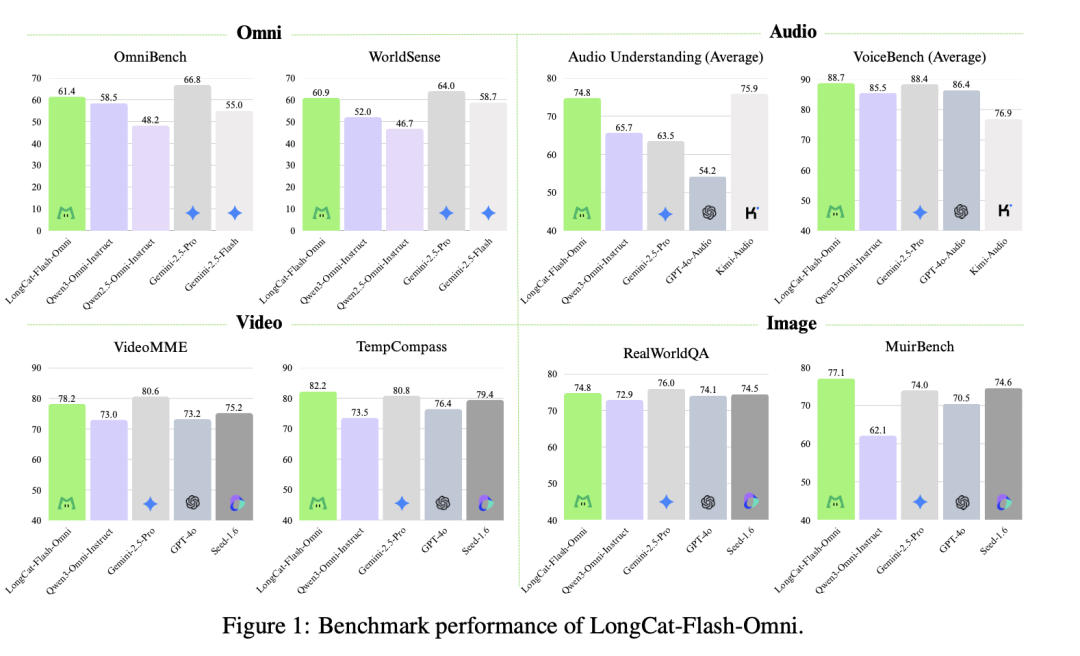
分析下面这个与其他模型对比图,发现LongCat-Flash-Omni,不仅延时低,而且模型性能也很不错,几乎全面碾压了GPT-4o,在音视频多模态方面与Gemini不相上下:
再学习下它的架构,图片,视频,音频,文本,多模态全能AI构架,如下图所示: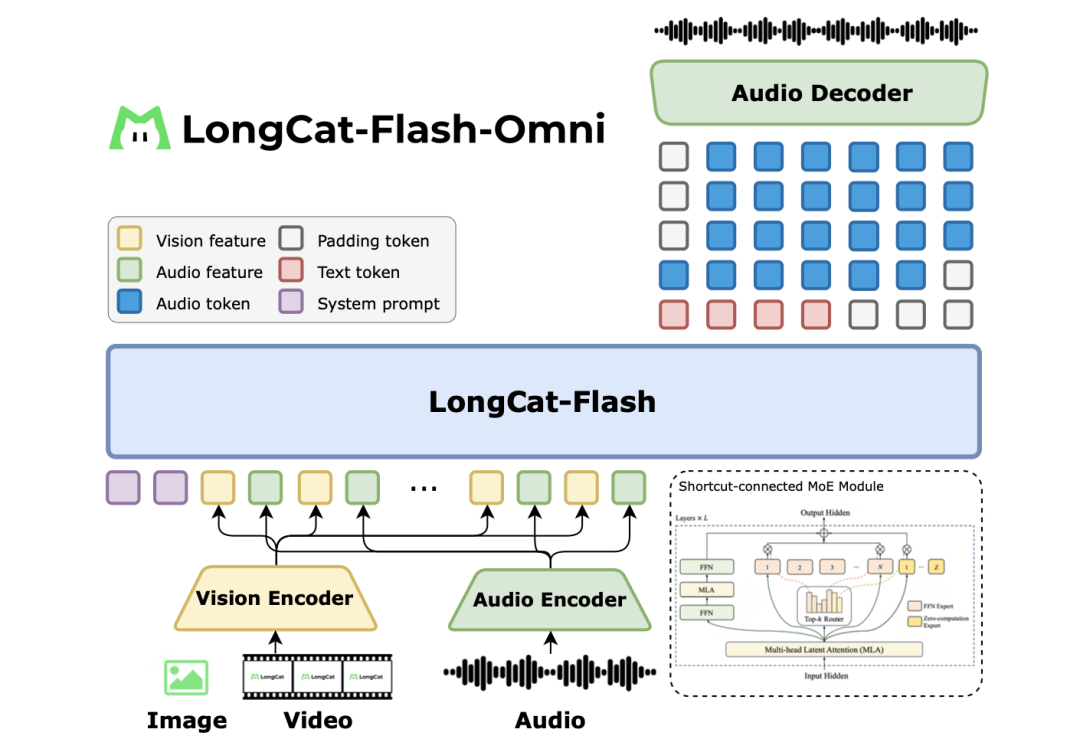 从上图可以看到,该模型采用端到端的多模态架构,以视觉和音频编码器作为统一感知层,由大语言模型直接理解输入并生成文本与语音的 token,再经轻量级音频解码器还原为自然语音,从而实现低延迟的实时多模态交互。
一个全模态模型,能同时做到快,而且还准,真的不容易,大参数规模与低延迟交互常常难以兼顾,那它家这模型到底怎么做到呢?再次灵魂拷问下自己。
在技术报告第4页,找到了答案,如下图所示:
从上图可以看到,该模型采用端到端的多模态架构,以视觉和音频编码器作为统一感知层,由大语言模型直接理解输入并生成文本与语音的 token,再经轻量级音频解码器还原为自然语音,从而实现低延迟的实时多模态交互。
一个全模态模型,能同时做到快,而且还准,真的不容易,大参数规模与低延迟交互常常难以兼顾,那它家这模型到底怎么做到呢?再次灵魂拷问下自己。
在技术报告第4页,找到了答案,如下图所示:
 此模型总参数高达 5600 亿,但真正参与运算的只有 270 亿。它用的是美团 LongCat-Flash 系列的创新架构 ScMoE(稀疏混合专家),其中还引入了“零计算专家”的设计理念。简单来说,就是让模型像一个庞大的专家团队,在不同任务场景下只激活最合适的少数“专家”,既节省算力,又提升效率。
所以,LongCat-Flash-Omni是一个很全面的多模态模型,AI全能选手。
此模型总参数高达 5600 亿,但真正参与运算的只有 270 亿。它用的是美团 LongCat-Flash 系列的创新架构 ScMoE(稀疏混合专家),其中还引入了“零计算专家”的设计理念。简单来说,就是让模型像一个庞大的专家团队,在不同任务场景下只激活最合适的少数“专家”,既节省算力,又提升效率。
所以,LongCat-Flash-Omni是一个很全面的多模态模型,AI全能选手。
3 美团AI技术演进
任何技术路线的成功,都不是一朝一夕的,美团AI技术演化大概也是这样的一个逐步演化的过程。
大概查了下升级过程,路线基本是这样的。他们从最初的 LongCat-Flash-Chat 到后来的 LongCat-Thinking、再到LongCat-Video,每一次迭代都在拓展模型的边界,让 AI 从“能对话”“会思考”,一步步走向“能理解并生成真实世界的动态。
最感兴趣的是它家的LongCat-Video模型,可以一次生成长达近5分钟的视频,效果如下所示:
您的浏览器不支持 video 标签
整体画面连贯、运动自然,几乎没有常见的色彩漂移或帧间抖动等问题。
如果再为画面配上一段合适的背景音乐,效果如下:
您的浏览器不支持 video 标签
整体的沉浸感就更强了,整个视频长达4分多钟,完整看过后发现,视频没有任何抖动,没有出现动作断裂问题。
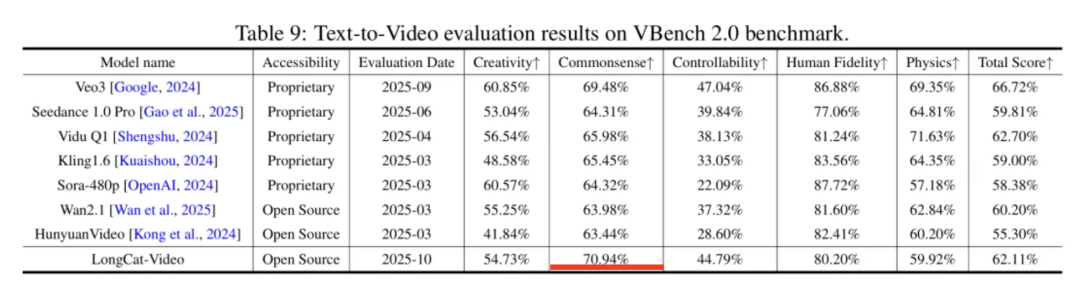
LongCat-Video 在 VBench:
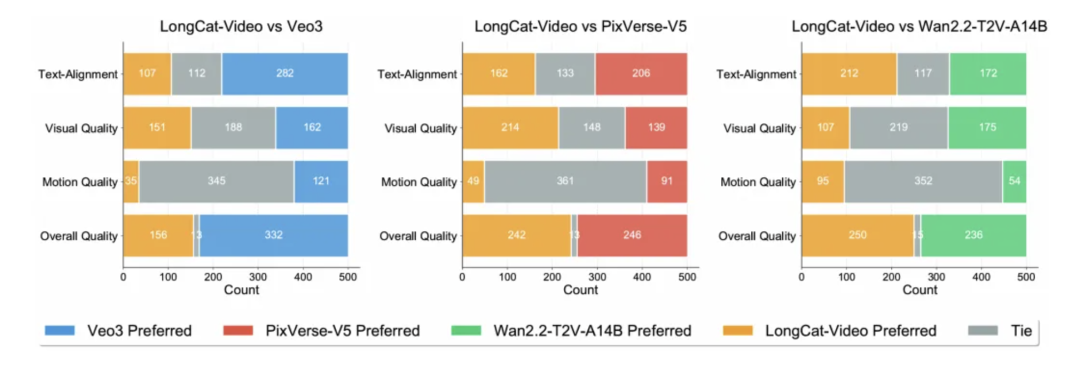
Text-to-Video、Image-to-Video 等多个公开基准上全面领先,综合性能达到开源 SOTA 水平,如下图所示:
如下LongCat-Video生成的切草莓视频,“切草莓”场景是视频生成中最具挑战的任务之一:
您的浏览器不支持 video 标签
它同时涉及物体交互、材质形变、遮挡关系与光影反射等复杂物理规律,稍有不稳就会出现刀具穿模、果实错位或光影漂移等问题。
而 LongCat-Video 在这一场景中实现了稳定、自然的表现:刀具与草莓的接触顺畅、受力形变真实、切面纹理与光线反射一致,整段画面无抖动与色彩漂移,充分证明了它在物理一致性与细节建模上的领先能力。
另外,LongCat-Flash-Omni模型已开源,部署步骤如下,首先下载代码:
git clone https://github.com/meituan-longcat/LongCat-Videocd LongCat-Video
安装依赖:
# create conda environmentconda create -n longcat-video python=3.10conda activate longcat-video
# install torch (configure according to your CUDA version)pip install torch==2.6.0+cu124 torchvision==0.21.0+cu124 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
# install flash-attn-2pip install ninja pip install psutil pip install packaging pip install flash_attn==2.7.4.post1
# install other requirementspip install -r requirements.txt
运行文生视频的方法:
# Single-GPU inferencetorchrun run_demo_text_to_video.py --checkpoint_dir=./weights/LongCat-Video --enable_compile
# Multi-GPU inferencetorchrun --nproc_per_node=2 run_demo_text_to_video.py --context_parallel_size=2 --checkpoint_dir=./weights/LongCat-Video --enable_compile
运行图生视频的方法:
# Single-GPU inferencetorchrun run_demo_image_to_video.py --checkpoint_dir=./weights/LongCat-Video --enable_compile
# Multi-GPU inferencetorchrun --nproc_per_node=2 run_demo_image_to_video.py --context_parallel_size=2 --checkpoint_dir=./weights/LongCat-Video --enable_compile
运行视频续写的方法:
# Single-GPU inferencetorchrun run_demo_video_continuation.py --checkpoint_dir=./weights/LongCat-Video --enable_compile
# Multi-GPU inferencetorchrun --nproc_per_node=2 run_demo_video_continuation.py --context_parallel_size=2 --checkpoint_dir=./weights/LongCat-Video --enable_compile
长视频生成的方法:
# Single-GPU inferencetorchrun run_demo_long_video.py --checkpoint_dir=./weights/LongCat-Video --enable_compile
# Multi-GPU inferencetorchrun --nproc_per_node=2 run_demo_long_video.py --context_parallel_size=2 --checkpoint_dir=./weights/LongCat-Video --enable_compile
最后总结一下
美团的AI技术发展路线,LongCat-Flash-Chat、LongCat-Thinking、再到LongCat-Video,再到最新 LongCat-Flash-Omni.
这条技术演进路线,从速度最快的对话交互,到专业深度的多模态理解,再到如今全面融合各类场景的音视频智能。
可以看到, 它家LongCat系每一次升级,都是AI向更强“多模态智能”迈进的一步。AI进化越来越快了,这也挺好,我们的生活也更方便了。
常见问题
又一个开源王炸!是个全能AI,语音对话几乎零延时,确实太…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
又一个开源王炸!是个全能AI,语音对话几乎零延时,确实太…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
又一个开源王炸!是个全能AI,语音对话几乎零延时,确实太…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容