English translation
I Tested Gemini-3.5 Against DeepSeek-V4 and GPT-5.5. The Result Was Unexpected
AI Field Note Decision Snapshot
Turn the test result into evidence quality, workflow, model/API, and buying-risk checks.
Use this snapshot to decide whether the field note supports a tool shortlist, a benchmark follow-up, an API comparison, or a security review before spending budget.
Evidence quality
Separate what was tested directly from what still needs vendor docs, benchmark data, pricing checks, or source verification.
Workflow transfer
Decide whether the field note applies to coding, search, research, support, content, document review, or internal automation.
Model and API implication
Map the result to model quality, latency, context window, multimodal fit, tool calling, or API reliability questions.
Buying risk
Check pricing, privacy, integration effort, data retention, security controls, and re-test triggers before turning evidence into spend.
Hi, I am Guozhen.
After nearly half a year, Gemini upgraded from version 3 to version 3.5.
This time, only Gemini 3.5 Flash was released, and it claims to have surpassed Gemini's own 3.1 Pro.
So I ran a hands-on comparison test.
1. Gemini 3.5 Flash
First, look at the model card scores.
For coding, its Terminal-bench 2.1 score reached 76.2%, close to GPT-5.5's 78.2%, and clearly above Gemini 3 Flash and Gemini 3.1 Pro.
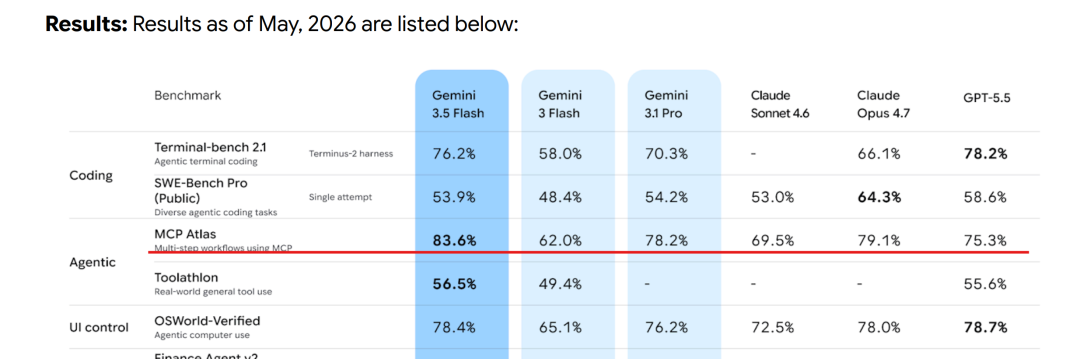
More importantly, its agent capability looks strong.
MCP Atlas reached 83.6%, higher than GPT-5.5 and Claude Opus 4.7.
Toolathlon reached 56.5%, suggesting strong performance in MCP, multi-tool calling, and real task flows.
UI operation is also not weak. OSWorld-Verified reached 78.4%, almost touching GPT-5.5's 78.7%.
Based on these scores, Gemini 3.5 Flash has become a very competitive mainstream model for agents, MCP, and real tool-use scenarios.
2. Comparison test
The test idea was to define a fixed environment, choose the models to compare, then send each result to Gemini-3.1-Pro as a judge.
The test task was a small agent task:
I will upload an Excel file. Please read and analyze the data.
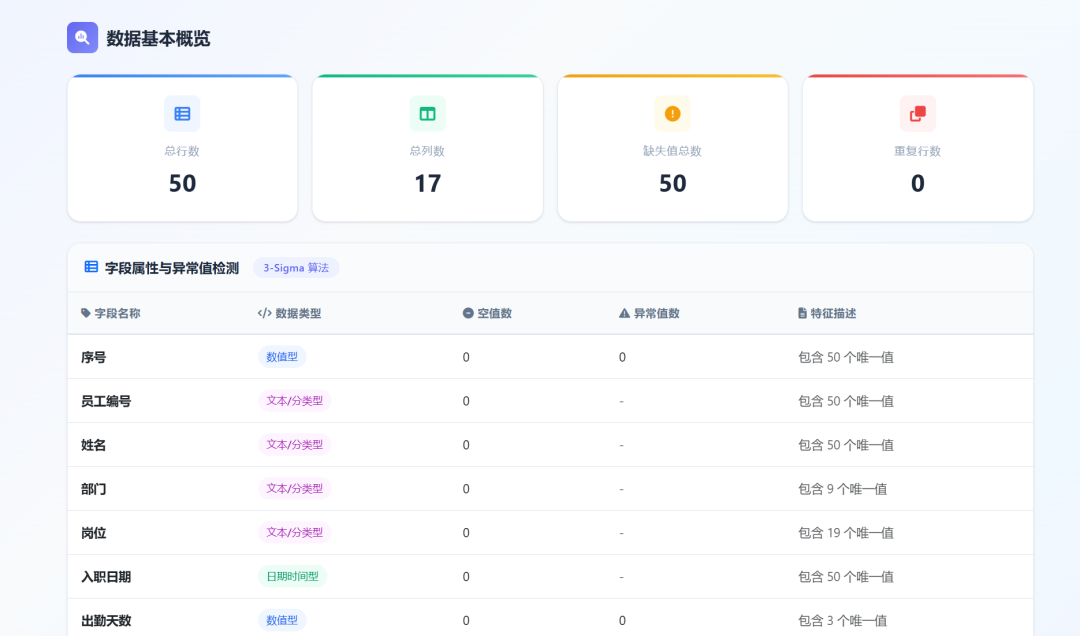
Identify fields, data types, row count, column count, and check empty values, outliers, and duplicate values.
Automatically choose fields suitable for bar charts, line charts, and pie charts.
Only output one directly runnable HTML file containing HTML/CSS/JS.
Use ECharts to draw a bar chart, line chart, and pie chart.
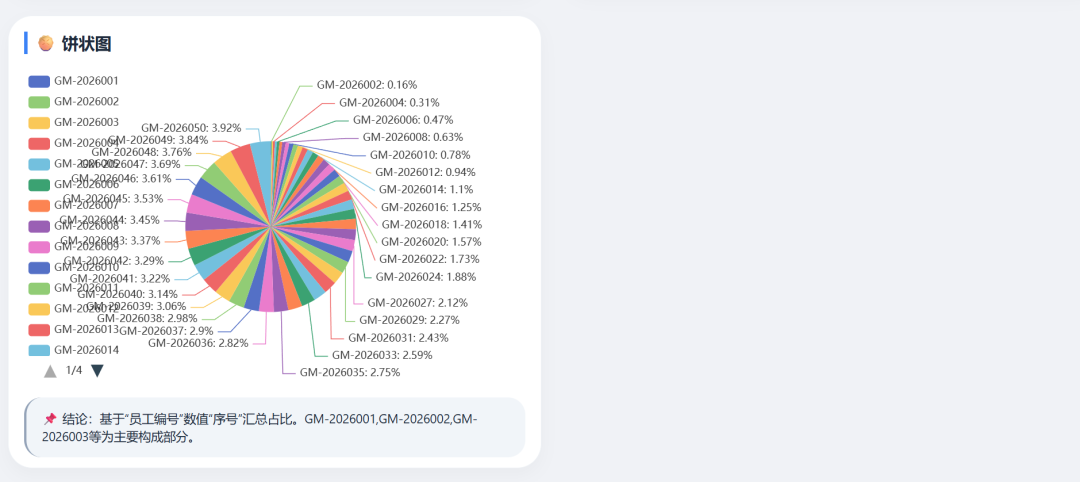
The page should include a data overview, three charts, and a Chinese conclusion for each chart.
Do not invent fields or values that do not exist. All conclusions must come from the Excel file.
If a chart type is not suitable, explain the reason on the page and provide an alternative chart.
The models used were Gemini-3.5-Flash, DeepSeek-V4-Flash, DeepSeek-V4-Pro, and GPT-5.5.
First, I selected Gemini-3.5-Flash:
Then I sent the small agent task to it:

I saved the generated HTML file:
Gemini-3.5-Flash result:
After uploading an Excel file, the data was displayed:
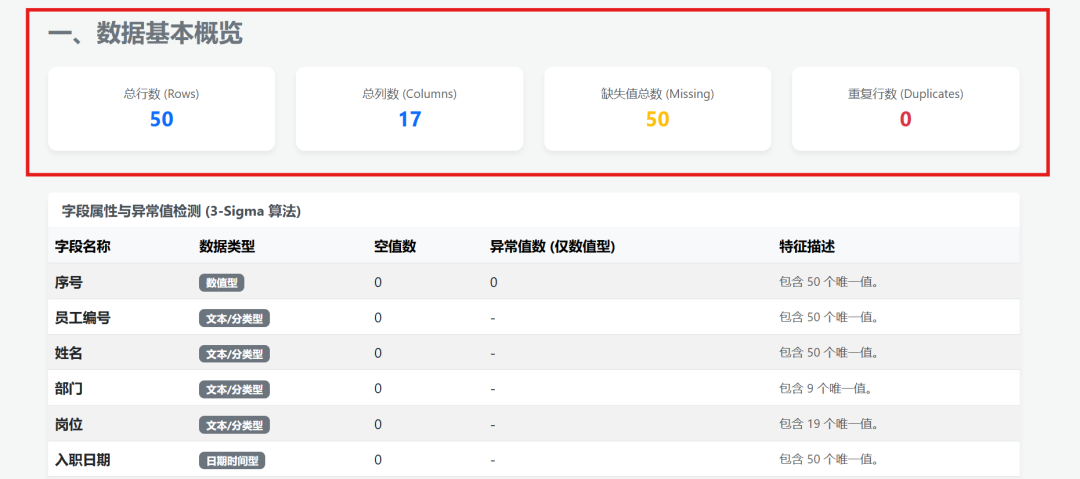
Visualization results:
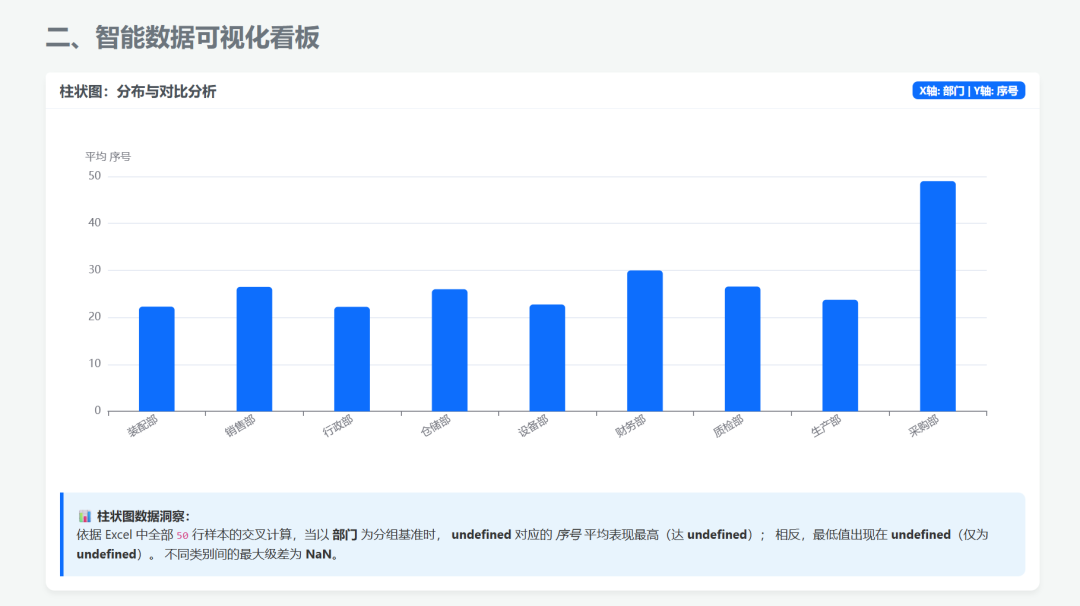
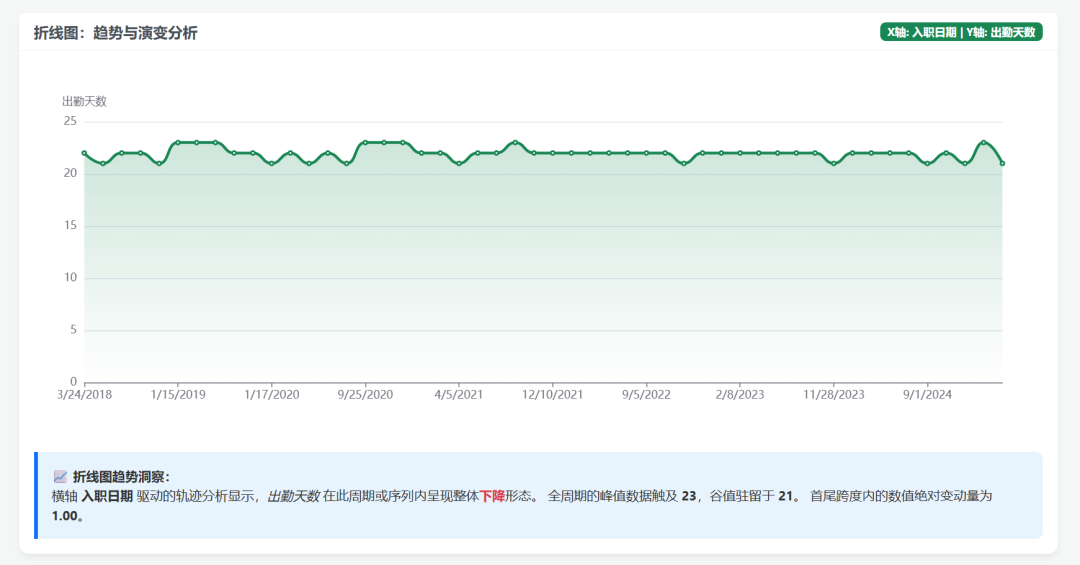
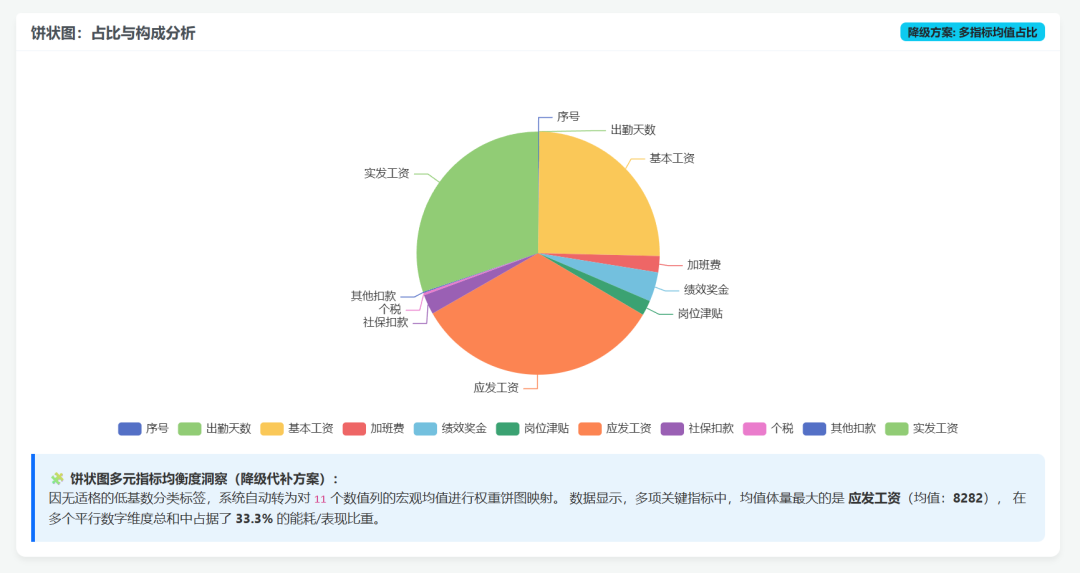
Then I sent the same small agent task to DeepSeek-V4 Flash:
After uploading the same Excel file to DeepSeek-V4 Flash, the result displayed like this:
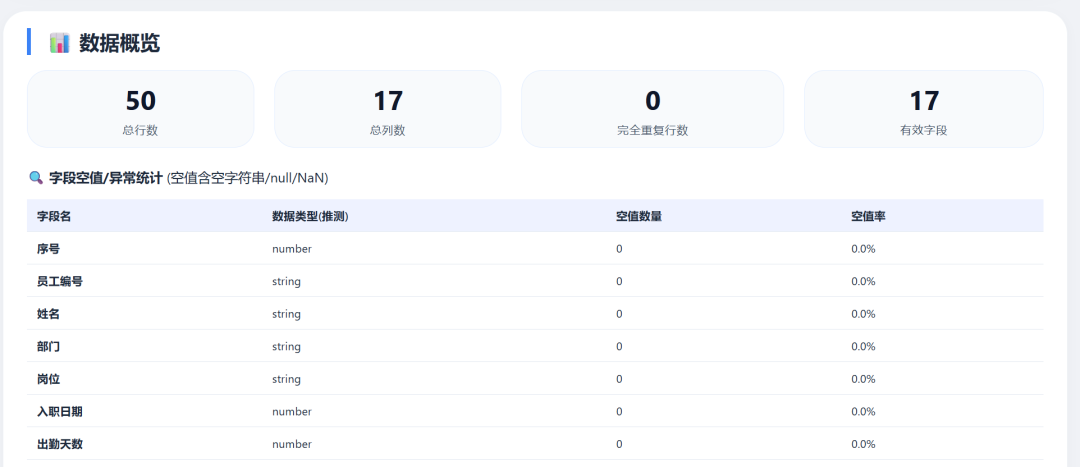
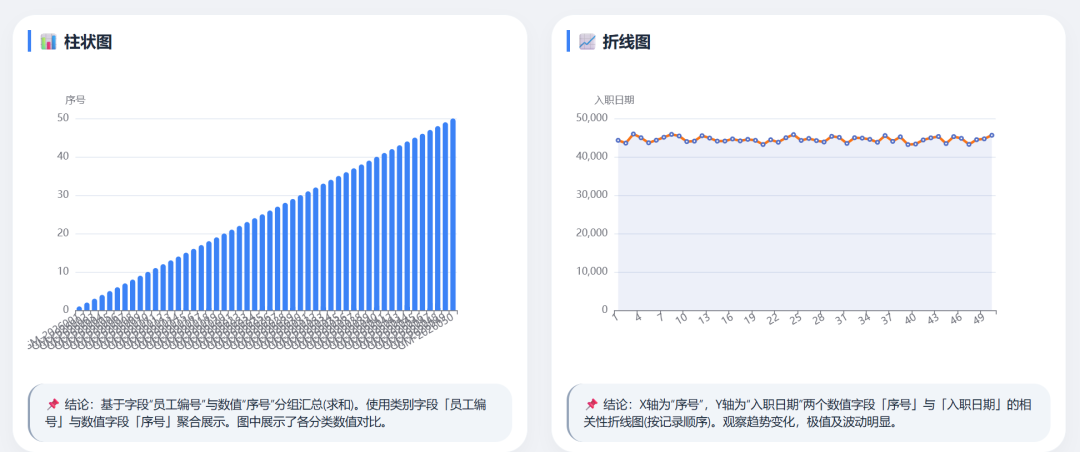
DeepSeek-V4 Flash data visualizations:
Then I sent the same task to DeepSeek-V4-Pro:
DeepSeek-V4-Pro data-analysis visualization:

DeepSeek-V4-Pro data display:
DeepSeek-V4-Pro visualizations:
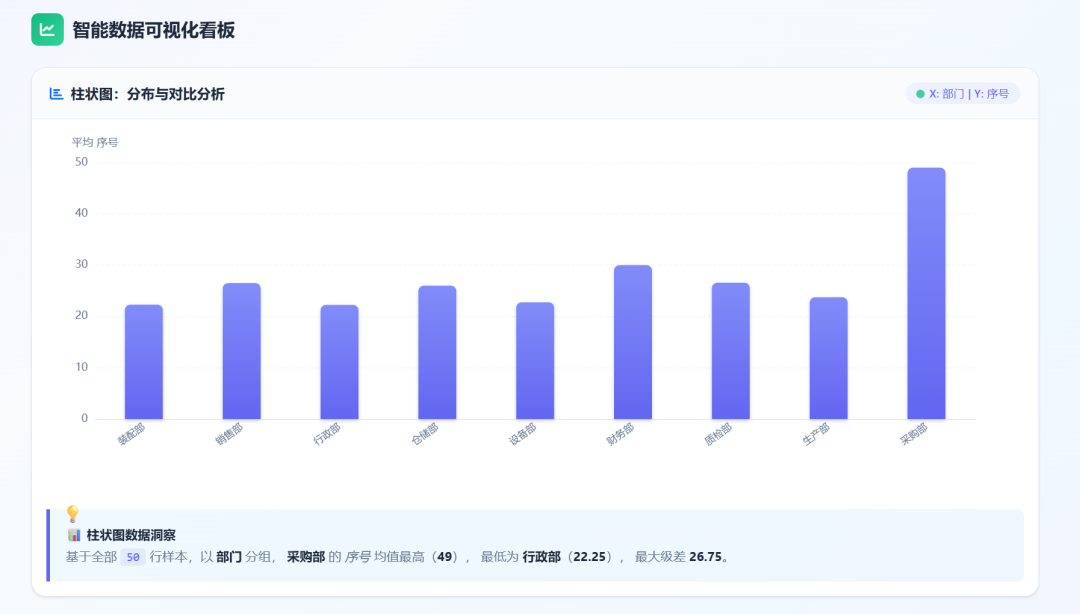
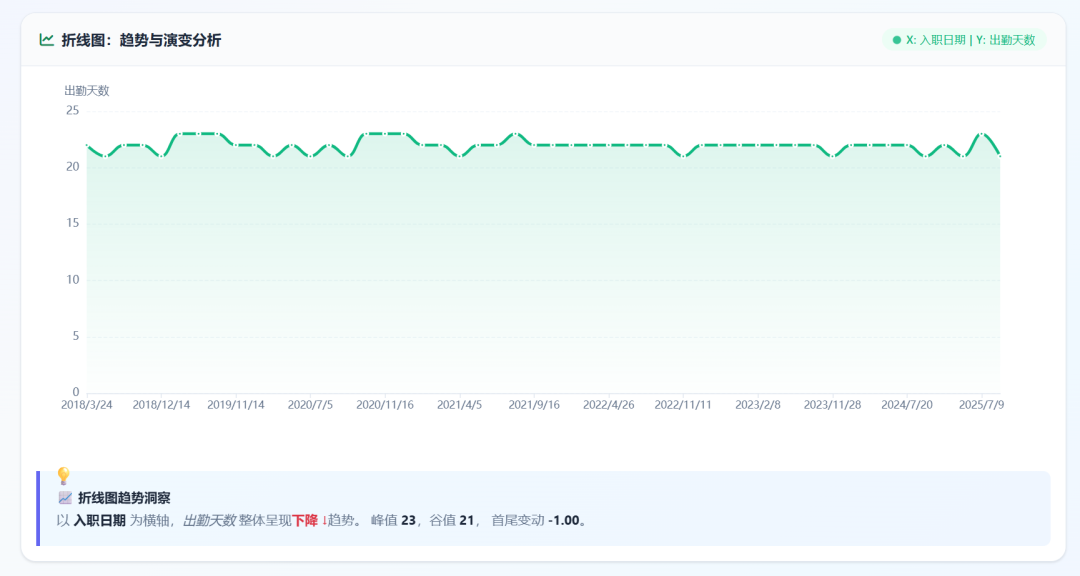
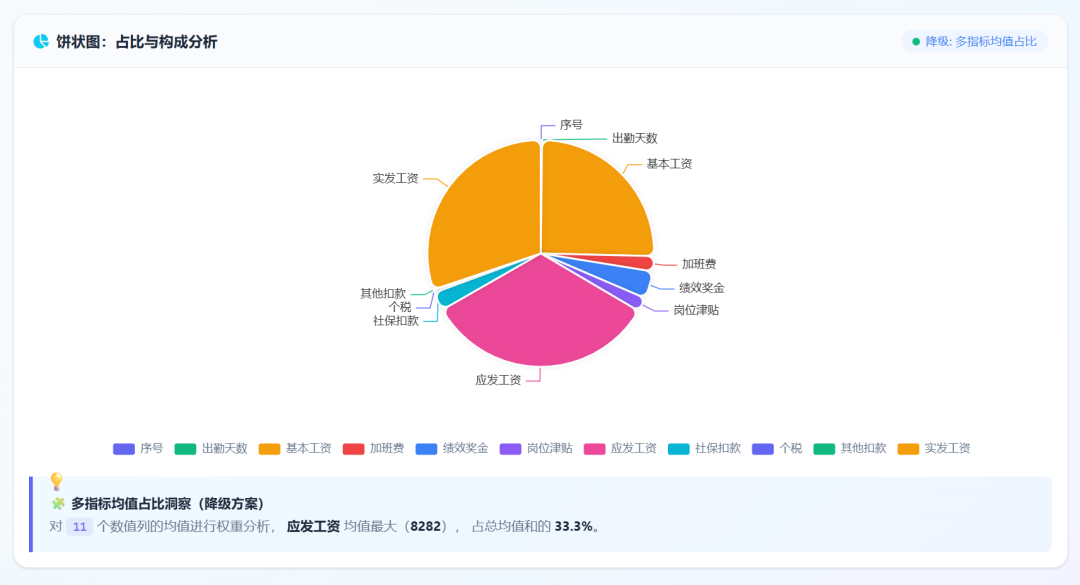
Finally, I sent the same task to GPT-5.5:
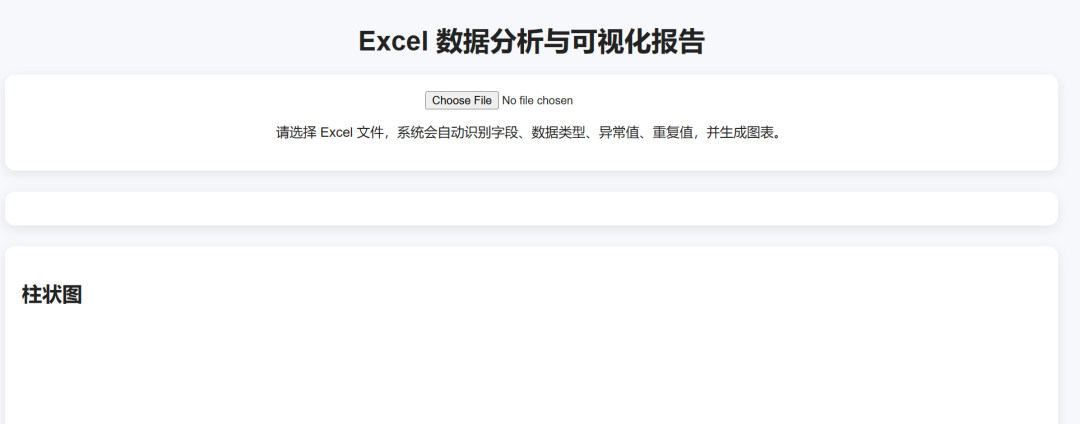
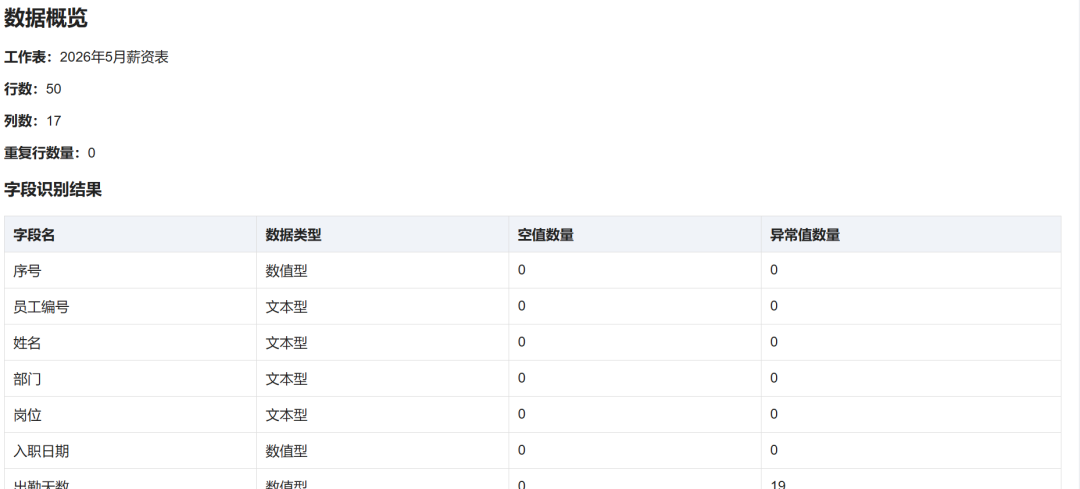
GPT-5.5 data display:
Visualization results:
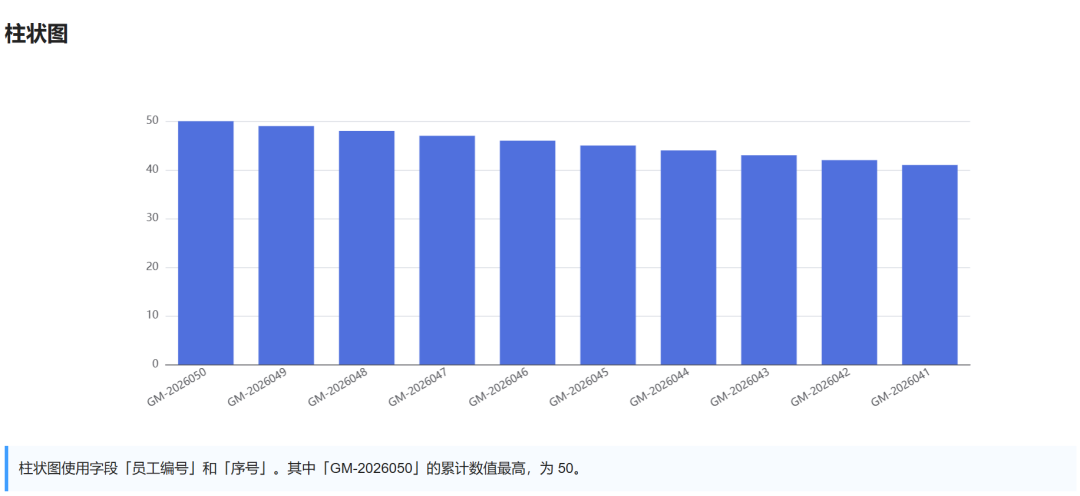
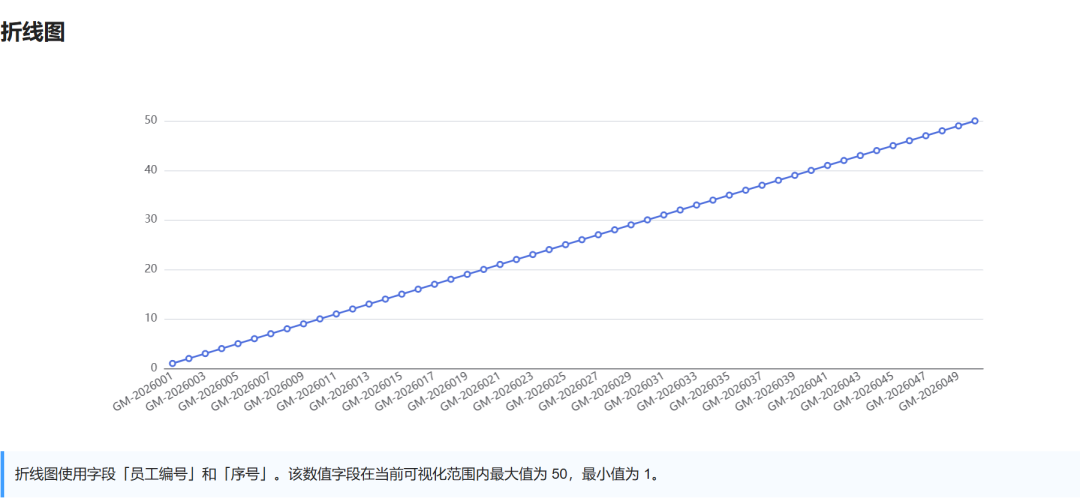
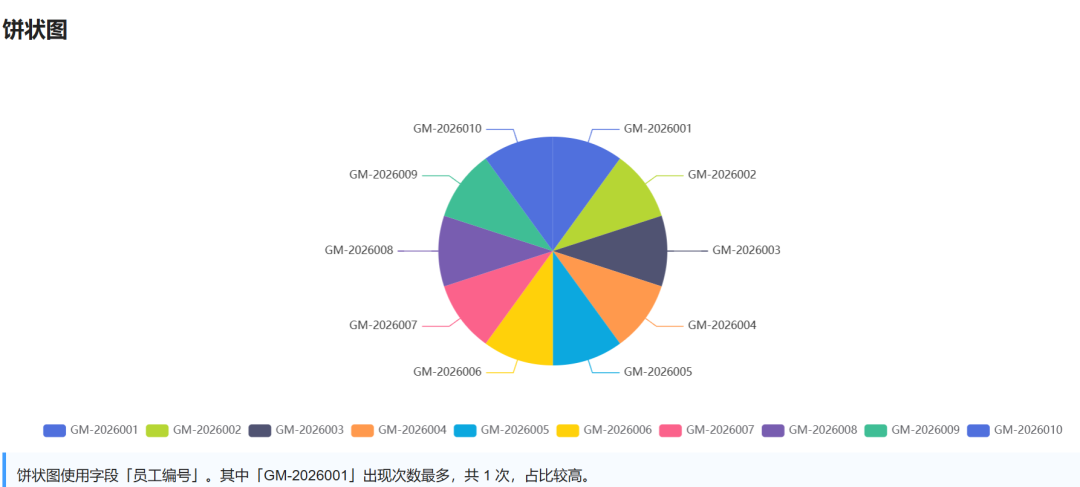
3. Judge scores
You can roughly see which result looks better just from intuition. But to make the evaluation more objective, I asked Gemini-3.1-Pro to judge the outputs:
The judge gave the scores:
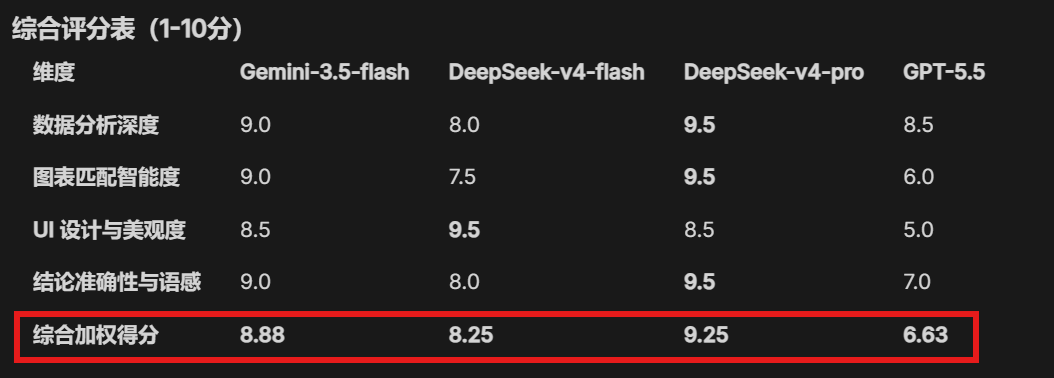
The judge also gave detailed explanations:

Then I asked the judge to summarize the result in three sentences:
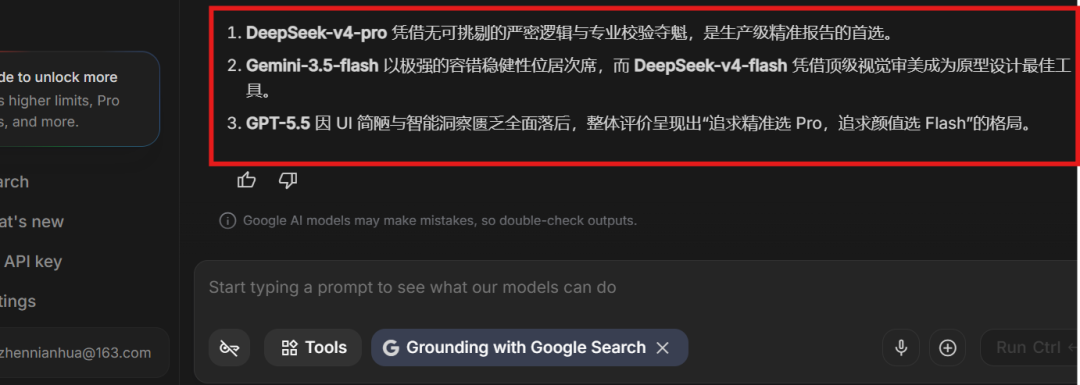
DeepSeek-V4-Pro won because of its rigorous logic and professional validation. It is the first choice for production-grade accurate reports.
Gemini-3.5-Flash ranked second because of strong fault tolerance and stability, while DeepSeek-V4-Flash became the best prototyping tool because of its excellent visual design.
GPT-5.5 fell behind because of a simple UI and weaker intelligent insights. The overall conclusion became: choose Pro for precision, choose Flash for visual polish.
I was surprised that GPT-5.5 ranked last, so I tried several more times. The result stayed the same.
Final thoughts
Because of article length, this test only used one small agent task to make an initial evaluation of Gemini 3.5 Flash's real performance. Overall, its completion quality was stable.
If you need a rigorous report, DeepSeek-V4-Pro is stronger. Gemini 3.5 Flash's advantage is balance, stability, and suitability for real office-automation scenarios.
GPT-5.5 performing poorly on this task surprised me. Of course, this is only a small-sample test. I will continue testing with more complex tasks later.
This English edition preserves the screenshots and workflow order from the original Chinese article.
Final verdict
Gemini-3.5 Flash looked balanced in this small task, while DeepSeek-V4-Pro stayed stronger for rigorous report quality. The result is useful, but it should be treated as an early field note rather than a universal benchmark.
From Field Note to Buying Decision
Use this AI field note to choose software, APIs, agents, search, and security tools.
AI Field Note FAQ
Use this field note as evidence before choosing AI tools
How should I use this AI field note?
Use it as hands-on evidence from a real AI workflow, then compare the related software category, model benchmark, API guide, security checklist, and tool alternatives before choosing a product.
Is this field note enough to choose an AI tool?
No. Treat the field note as practical context, then validate pricing, privacy, integration effort, reliability, benchmark fit, and team workflow before spending budget.
What should I read after I Tested Gemini-3.5 Against DeepSeek-V4 and GPT-5.5. The Result Was Unexpected?
Open AI Software Buyer Guides, AI Model Benchmarks, Best AI Coding Agents, Enterprise AI Search Tools, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
When should teams re-test the result from this field note?
Re-test when the model, product plan, pricing, API behavior, prompt workflow, data policy, browser support, or deployment environment changes.
Continue