English translation
MiniMax M3 Coding Benchmark: Testing It Against GPT-5.5 and DeepSeek-V4
AI Field Note Decision Snapshot
Turn the test result into evidence quality, workflow, model/API, and buying-risk checks.
Use this snapshot to decide whether the field note supports a tool shortlist, a benchmark follow-up, an API comparison, or a security review before spending budget.
Evidence quality
Separate what was tested directly from what still needs vendor docs, benchmark data, pricing checks, or source verification.
Workflow transfer
Decide whether the field note applies to coding, search, research, support, content, document review, or internal automation.
Model and API implication
Map the result to model quality, latency, context window, multimodal fit, tool calling, or API reliability questions.
Buying risk
Check pricing, privacy, integration effort, data retention, security controls, and re-test triggers before turning evidence into spend.
Hi, I am Guozhen.
MiniMax M3 was released recently, and the claim that caught my attention was its coding capability. Some early discussions said that parts of its coding performance were approaching Claude Opus 4.7.
That sounded worth testing.
Instead of only looking at leaderboard numbers, I tested MiniMax M3 on three practical coding-agent tasks and compared the results with GPT-5.5 and DeepSeek-V4-Pro.
The three tasks were:
- build a single-file Excel data analysis and visualization web app
- build a Three.js 3D smart factory energy management scene
- recreate a SaaS dashboard UI from a screenshot as a single-file HTML page
Then I used Gemini-3.1-Pro as the judge for scoring.
1. MiniMax M3 on the AA Intelligence Index
The AA Intelligence Index currently places MiniMax M3 at number 7 globally and number 2 among Chinese models:
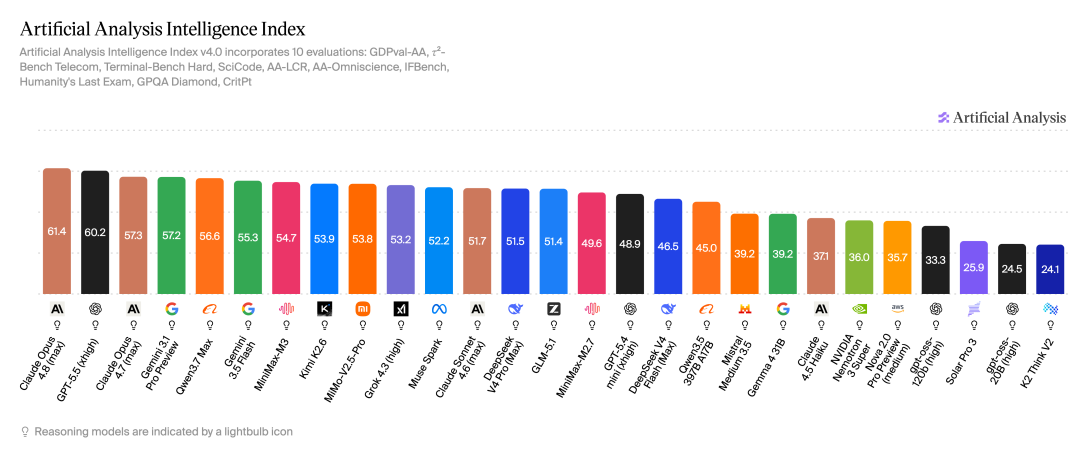
AA is a broad model capability benchmark. It includes real tasks, agents, coding, long context, knowledge and hallucination checks, scientific reasoning, and several other dimensions, then combines them with fixed weights.
On this ranking, MiniMax M3 has entered the first tier for general intelligence, coding engineering, and agent/tool-use tasks. Its total score is 54.7, close to Claude Opus 4.7 at 57.3.
Leaderboard scores are useful, but the real question is whether it feels good in actual development tasks. So I tested it directly.
2. Test case 1: Excel analytics web app
The first task checks long-prompt following, frontend completeness, data handling, and chart generation.
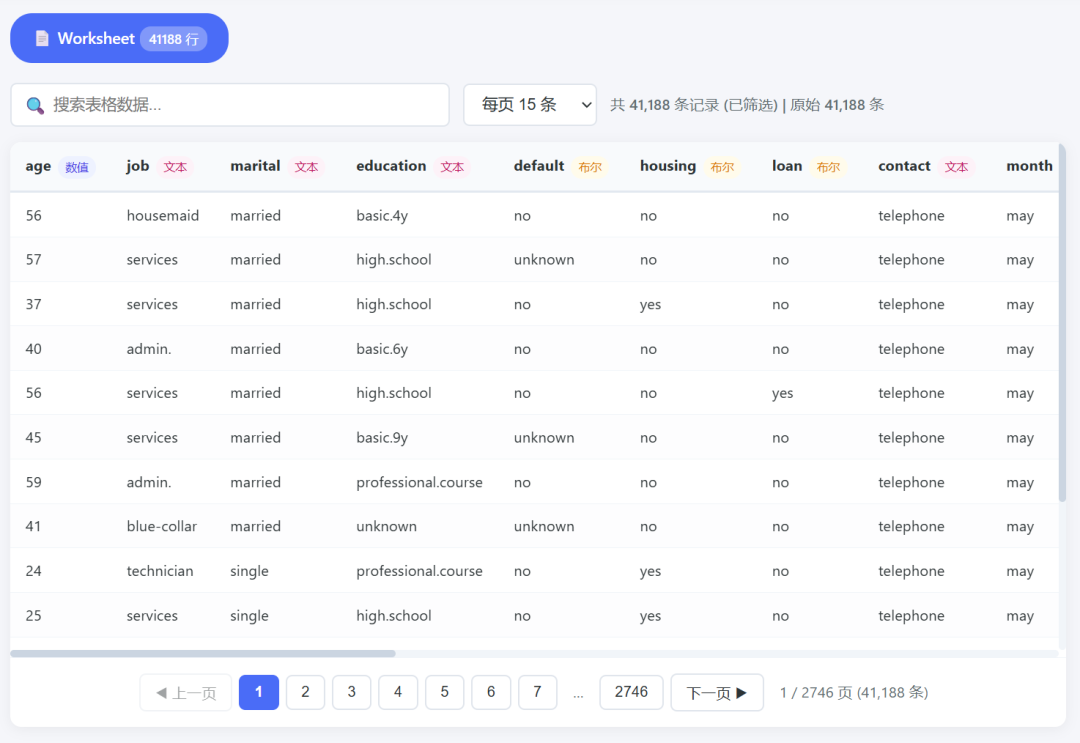
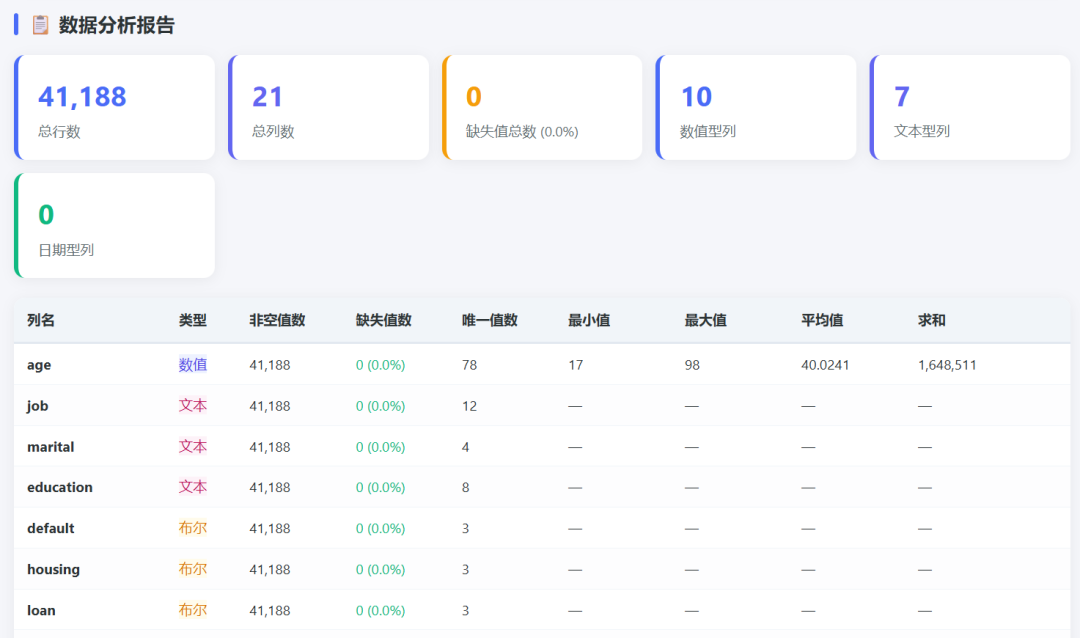
The prompt asked the model to create a complete single-file HTML page for Excel analysis and visualization. It had to support .xlsx and .xls upload, parse multiple sheets with SheetJS, show searchable and paginated data tables, detect field types, calculate missing values and summary statistics, write a Chinese analysis report, generate ECharts visualizations, and let the user choose X/Y fields and chart types.
MiniMax M3 received the prompt first:

It generated this frontend interface:
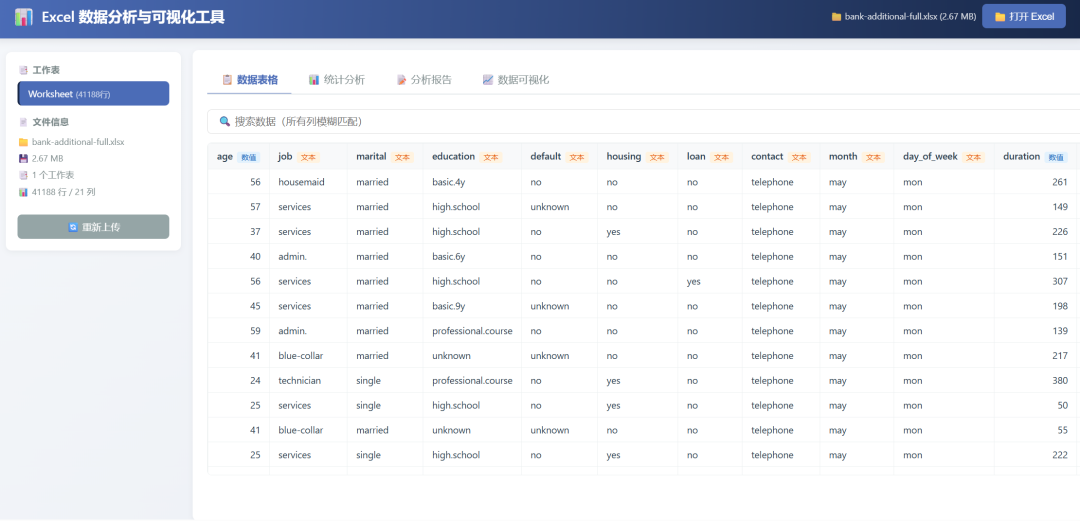
The data table worked:
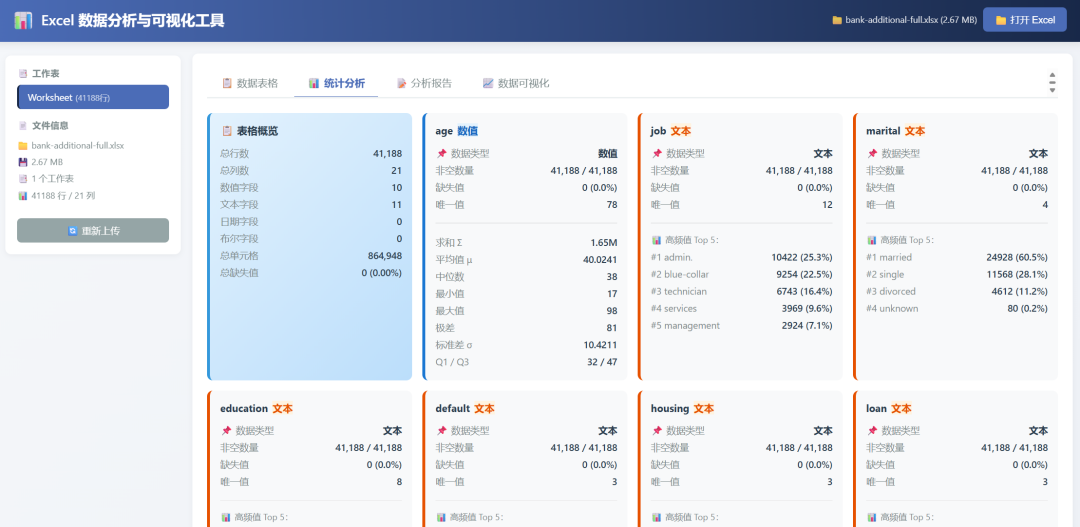
The statistics panel was generated:
It also produced an analysis report:
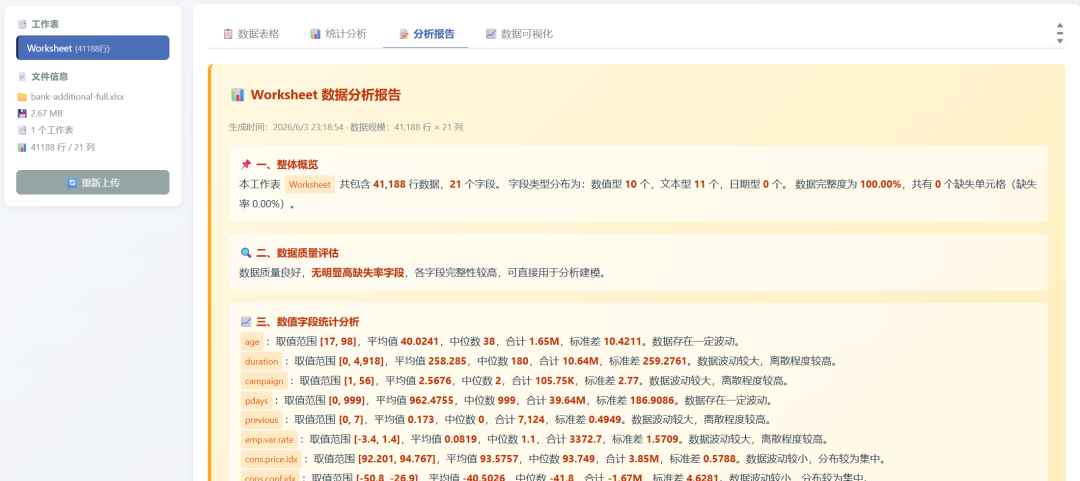
And several visualizations:
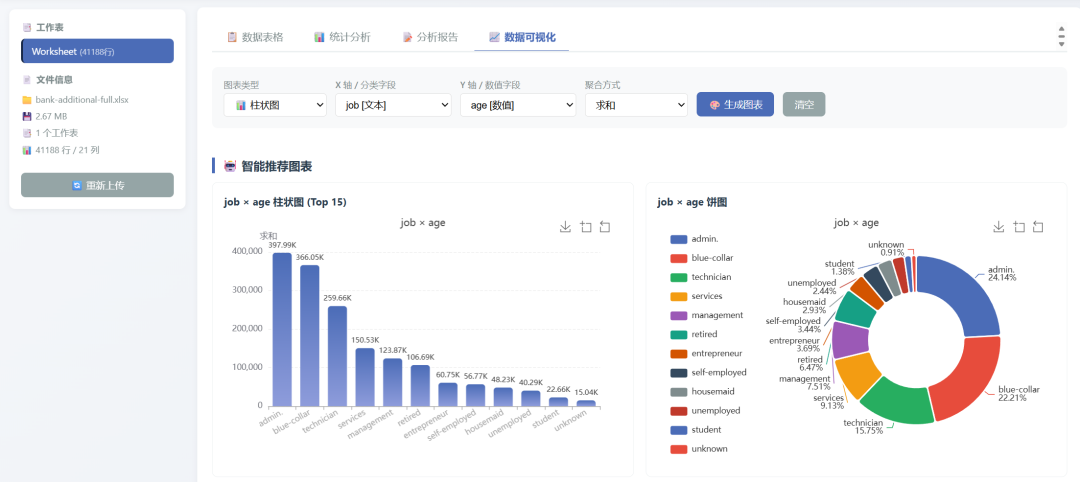
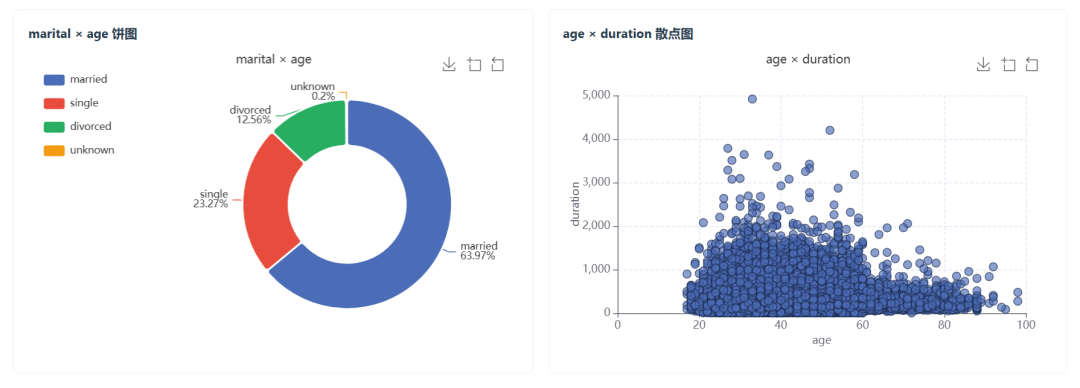
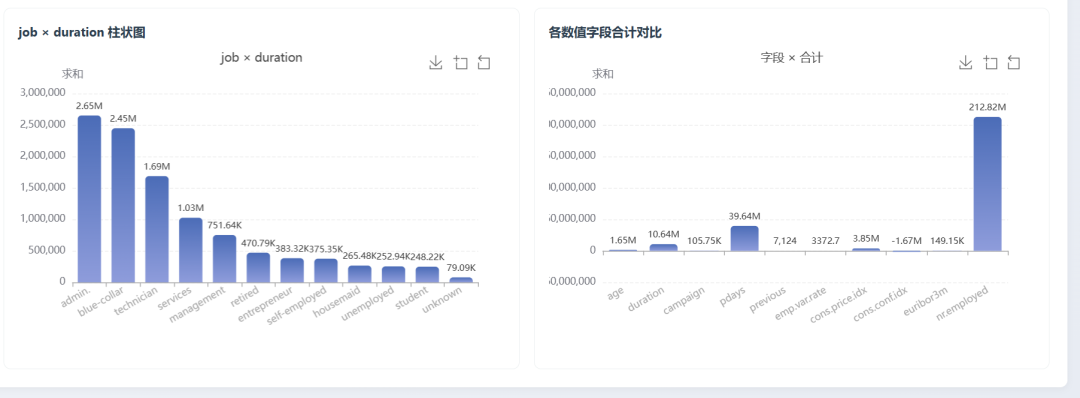
I then sent the same prompt to GPT-5.5. Its interface looked like this:
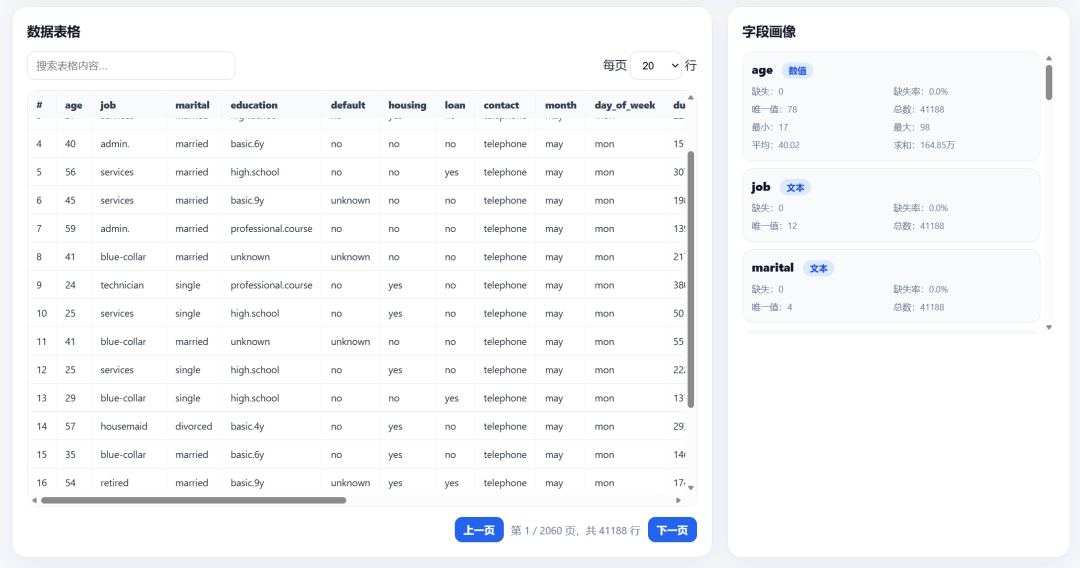
The data table:
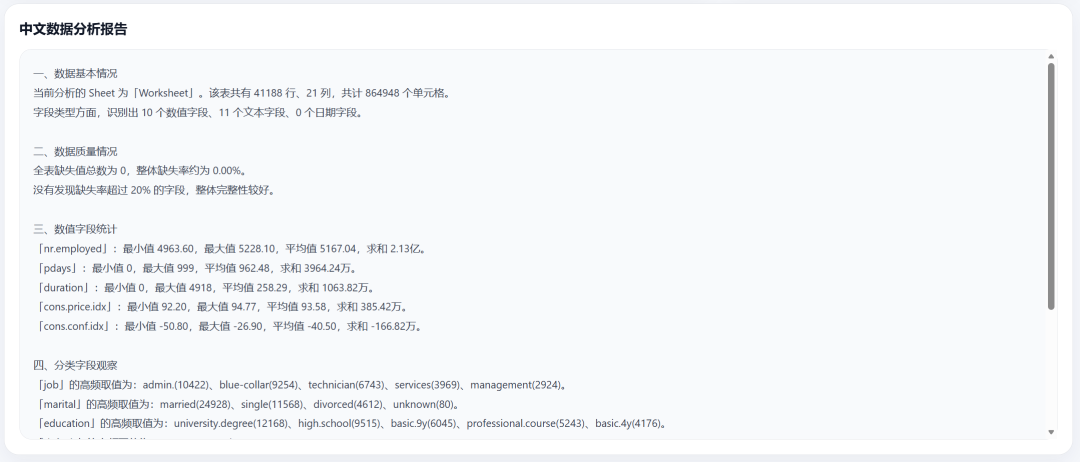
The Chinese analysis report:
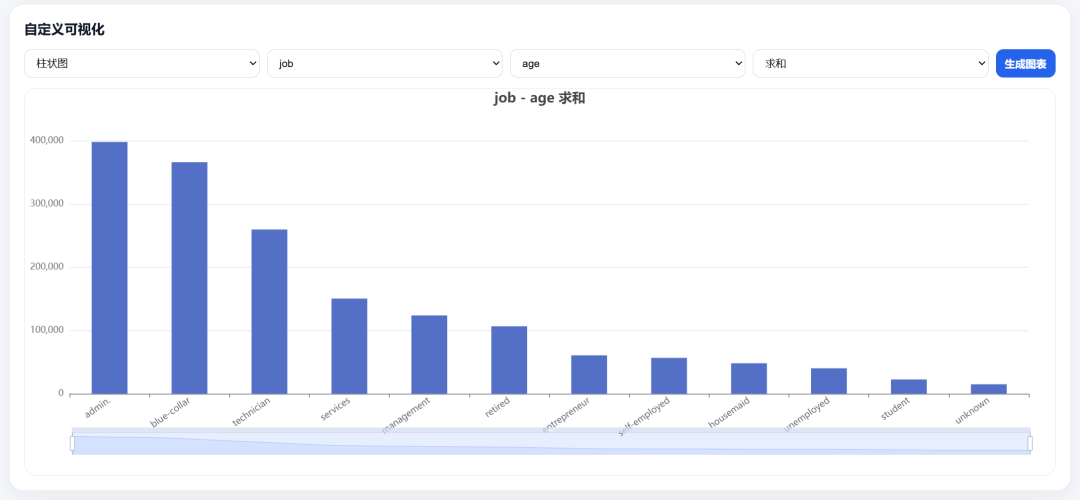
And visualizations:
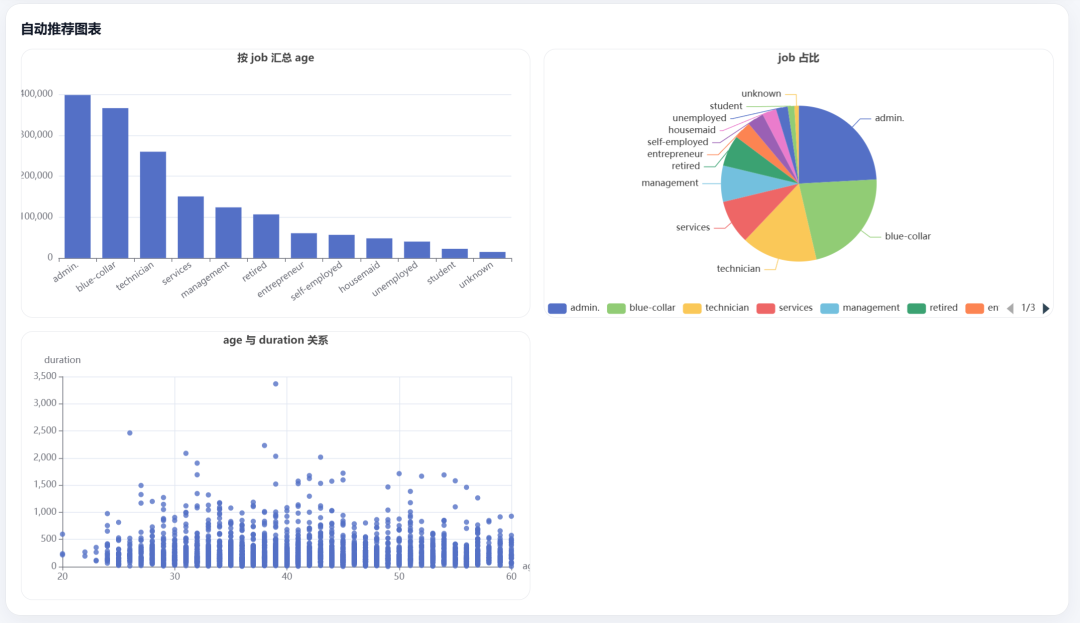
DeepSeek-V4-Pro produced this interface:
Its table view:
The data overview:
And several visual charts:
3. Test case 2: Three.js 3D smart factory
The second task asked for a complete single-file HTML page using Three.js. The scene needed a 3D smart factory energy management environment with factory buildings, solar panels, battery cabinets, transformers, a control center, charging piles, animated colored energy pipes, OrbitControls, lighting, shadows, Chinese device labels, a real-time parameter panel, and click-to-view device details.
The model had to generate all geometry and textures in code without external models or images.
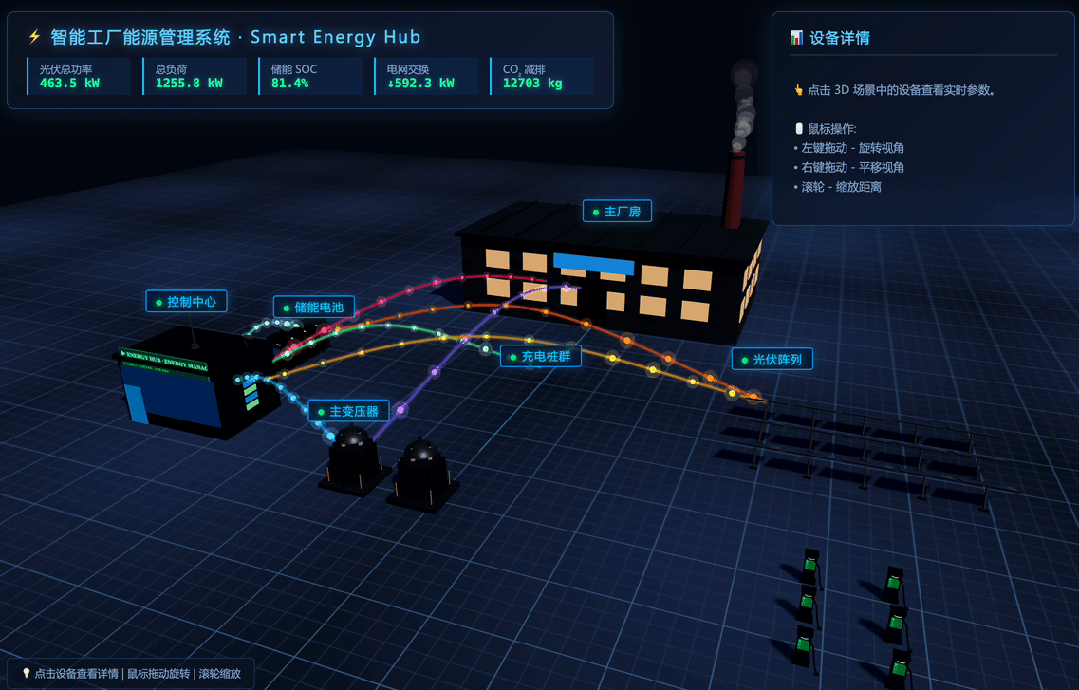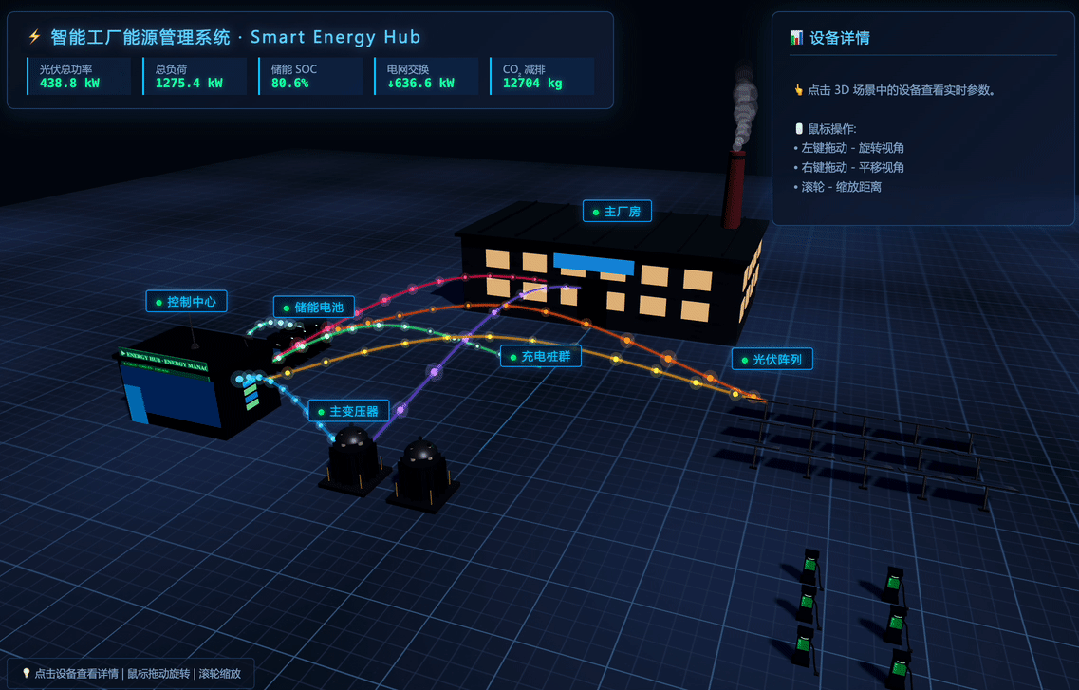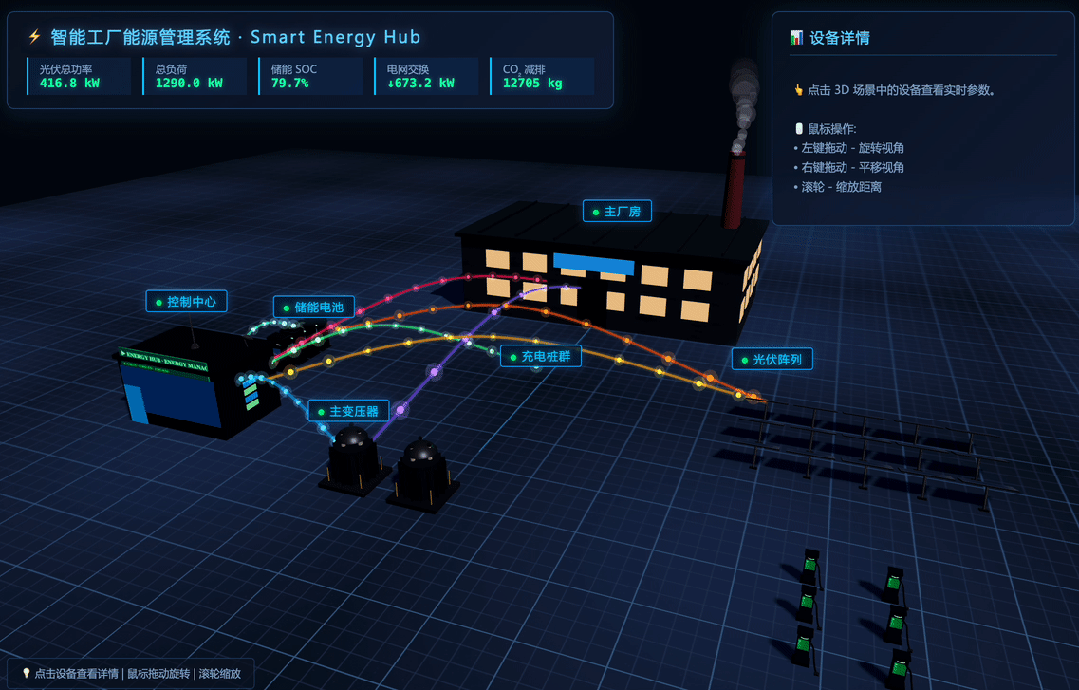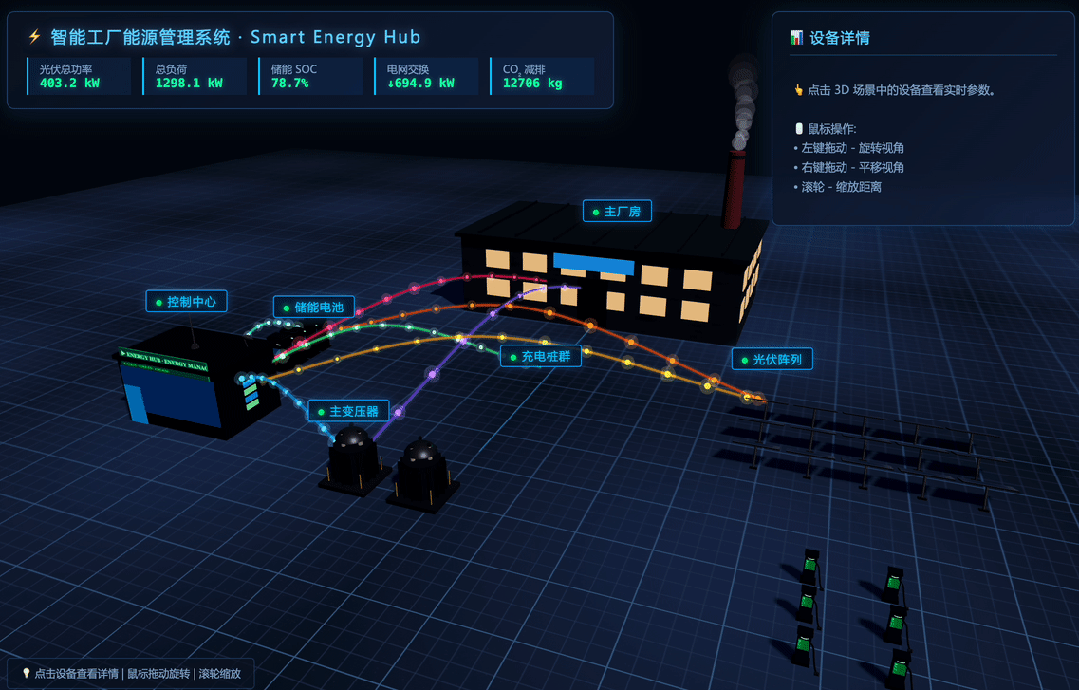
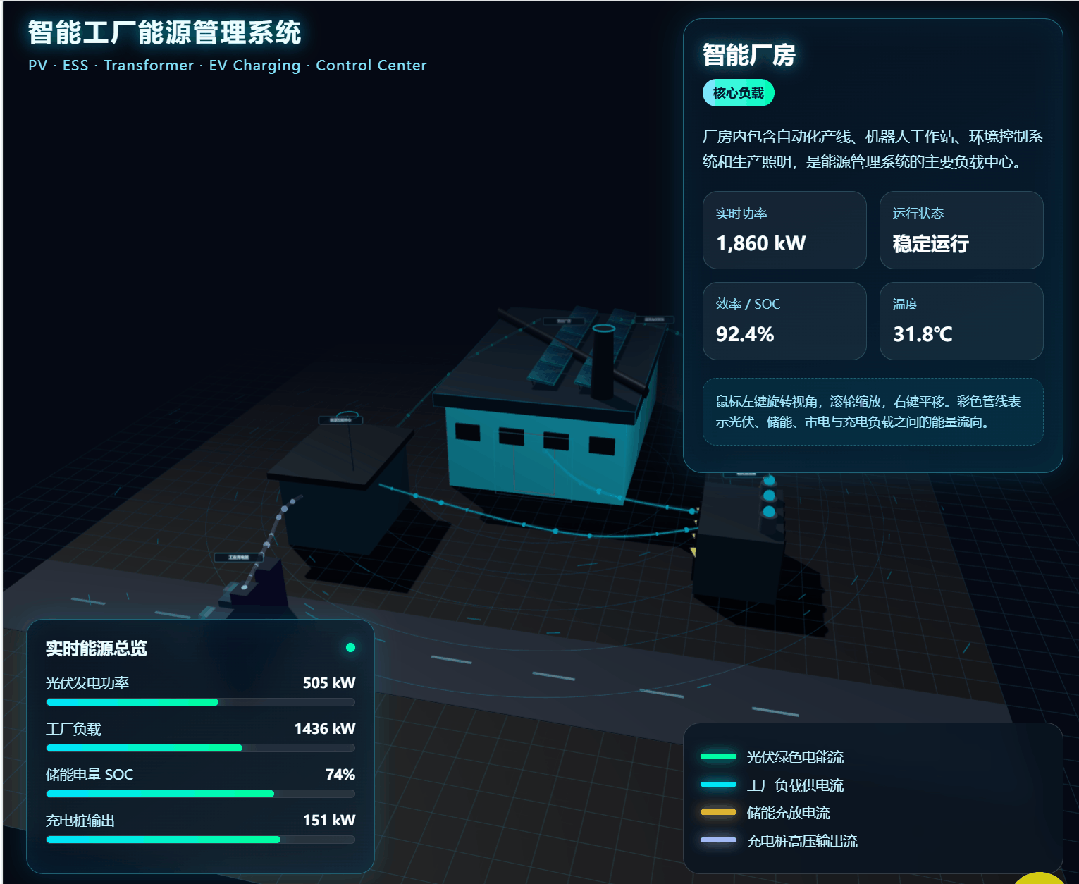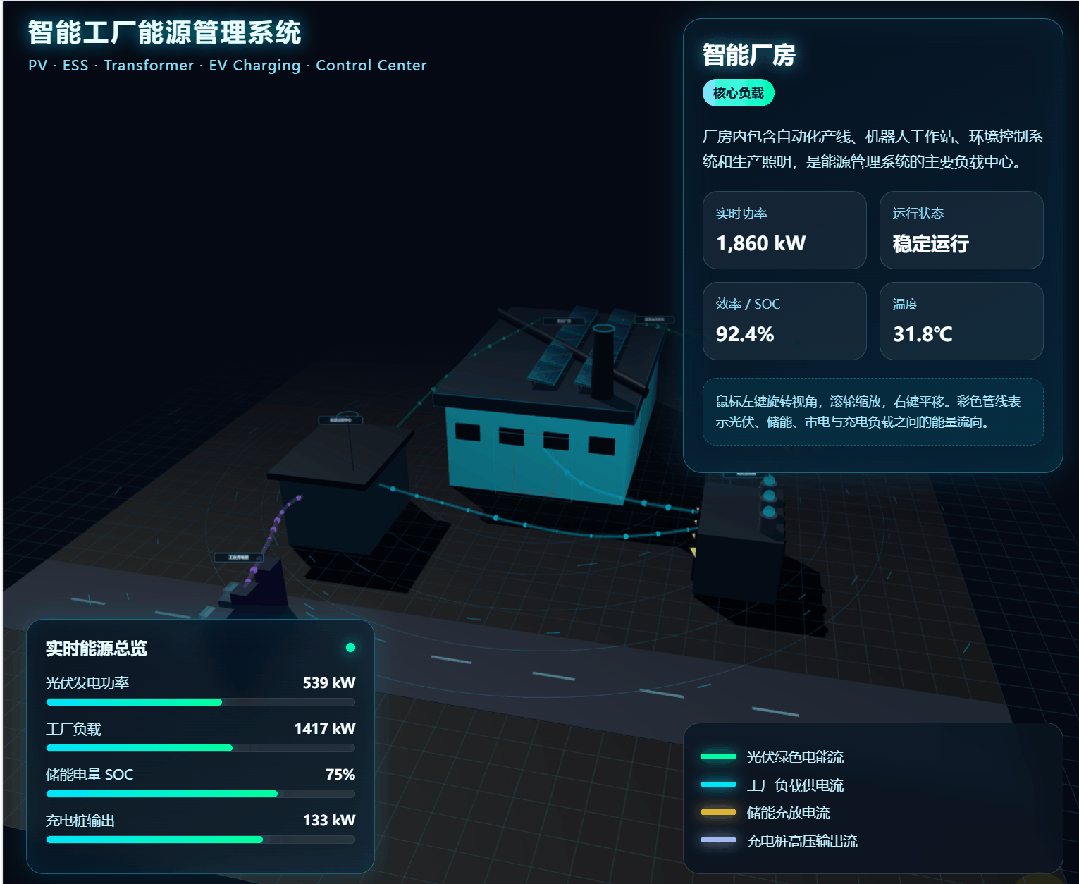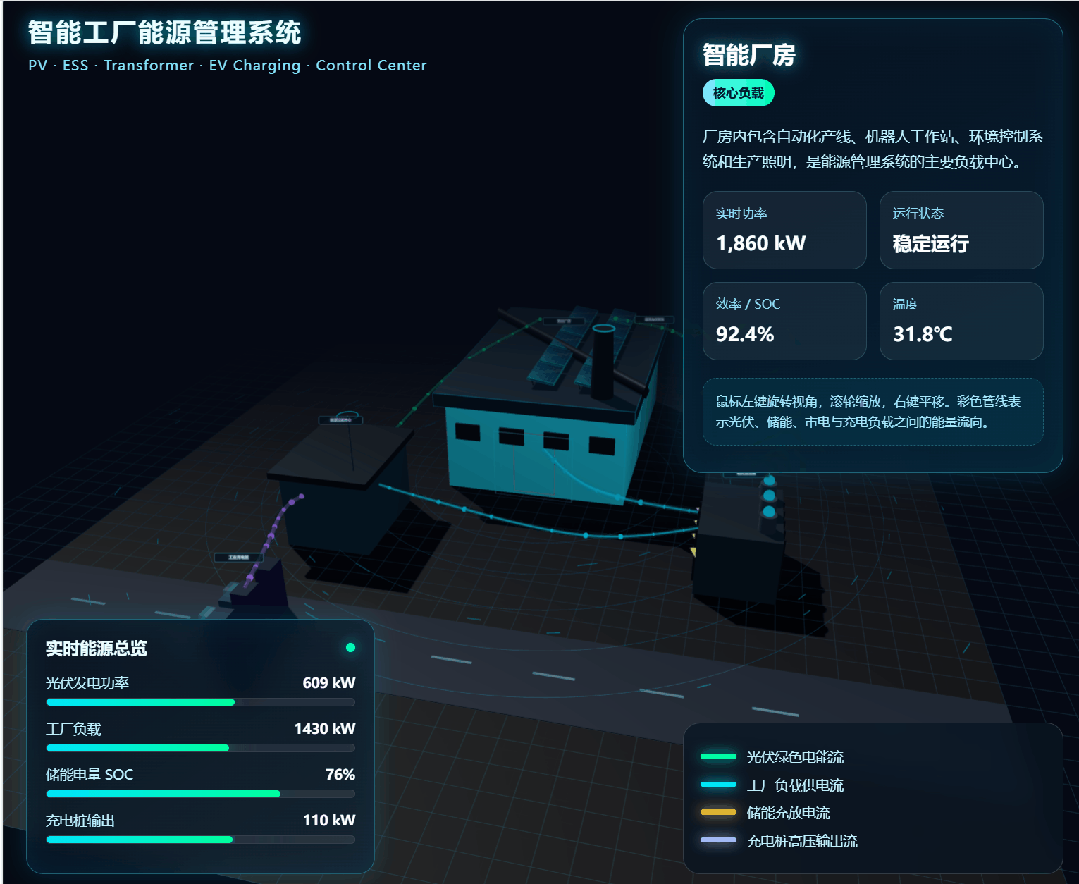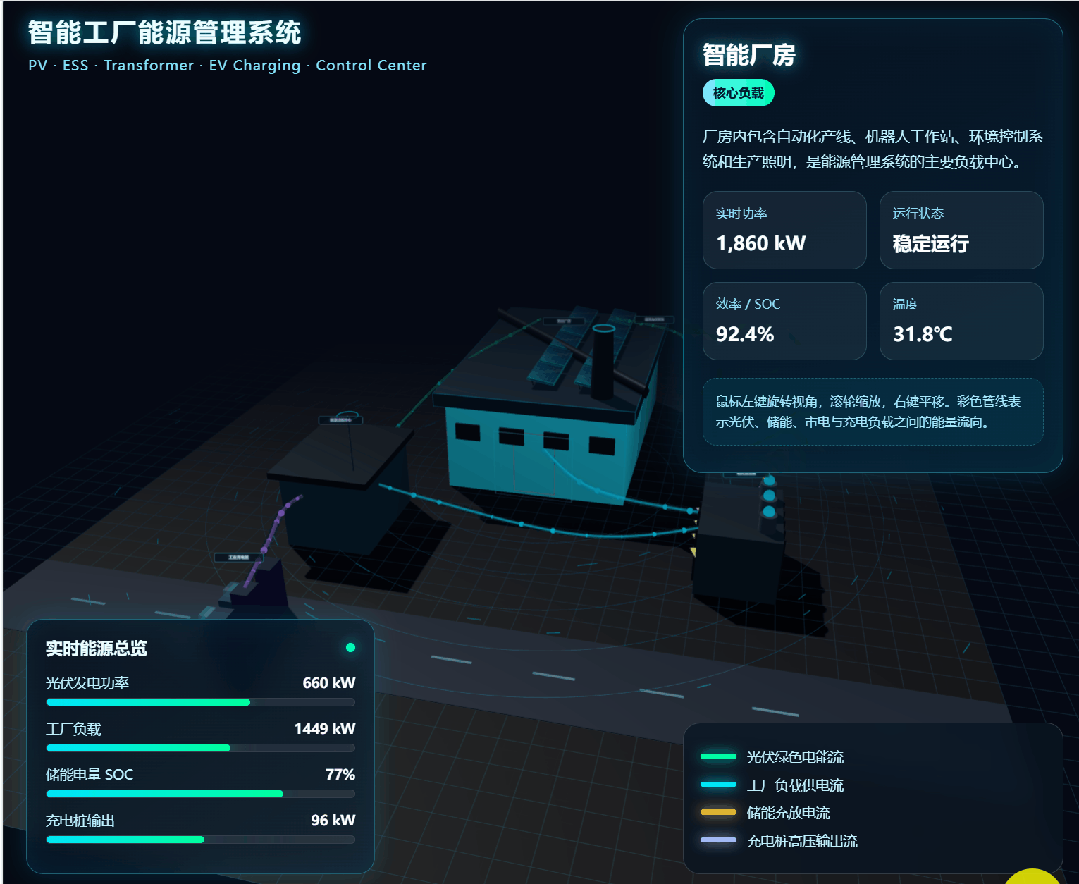
MiniMax M3 received the prompt:

Because the result was animated, I recorded a GIF:
GPT-5.5 received the same prompt:
DeepSeek-V4-Pro also generated a dynamic scene:
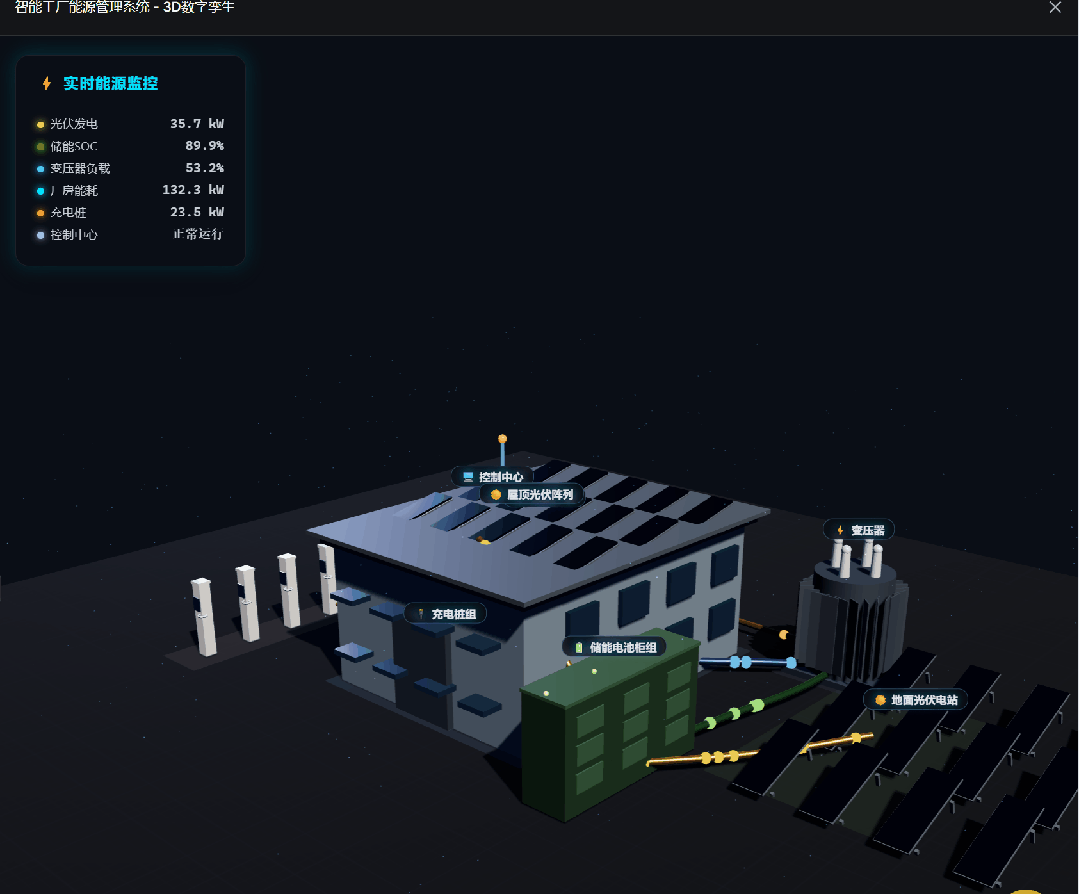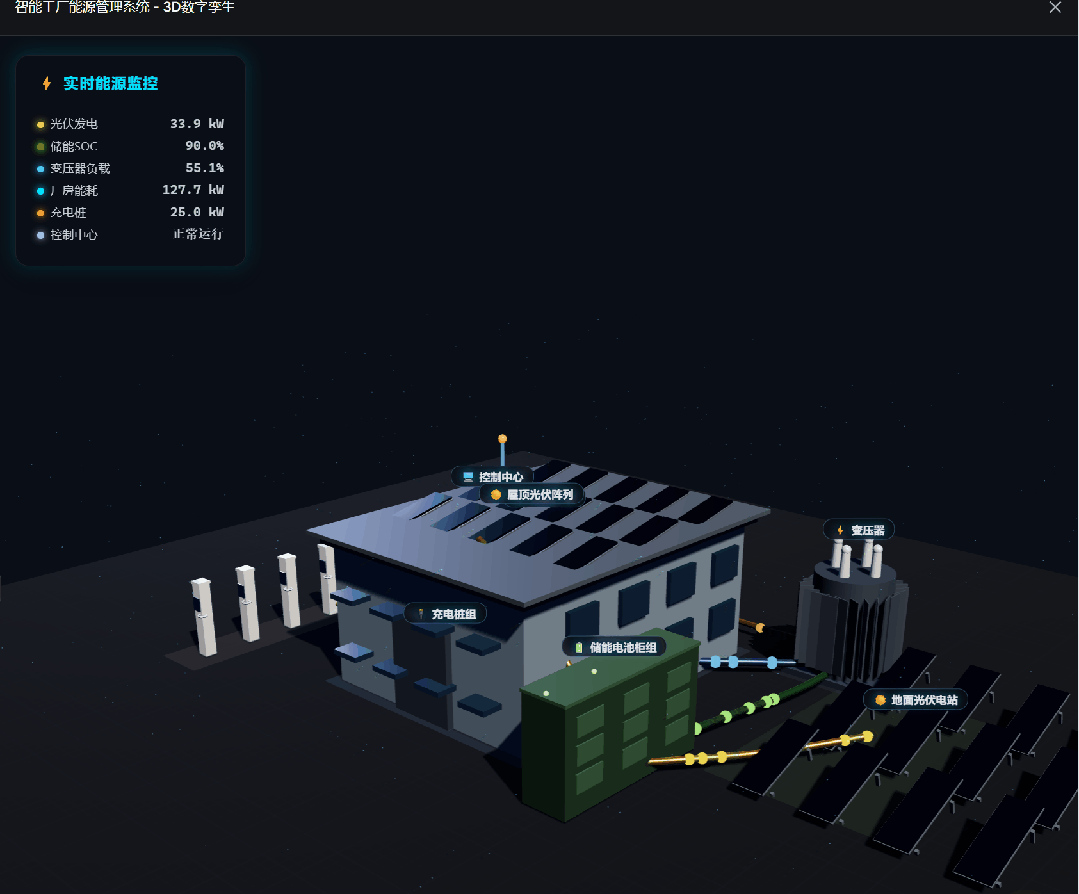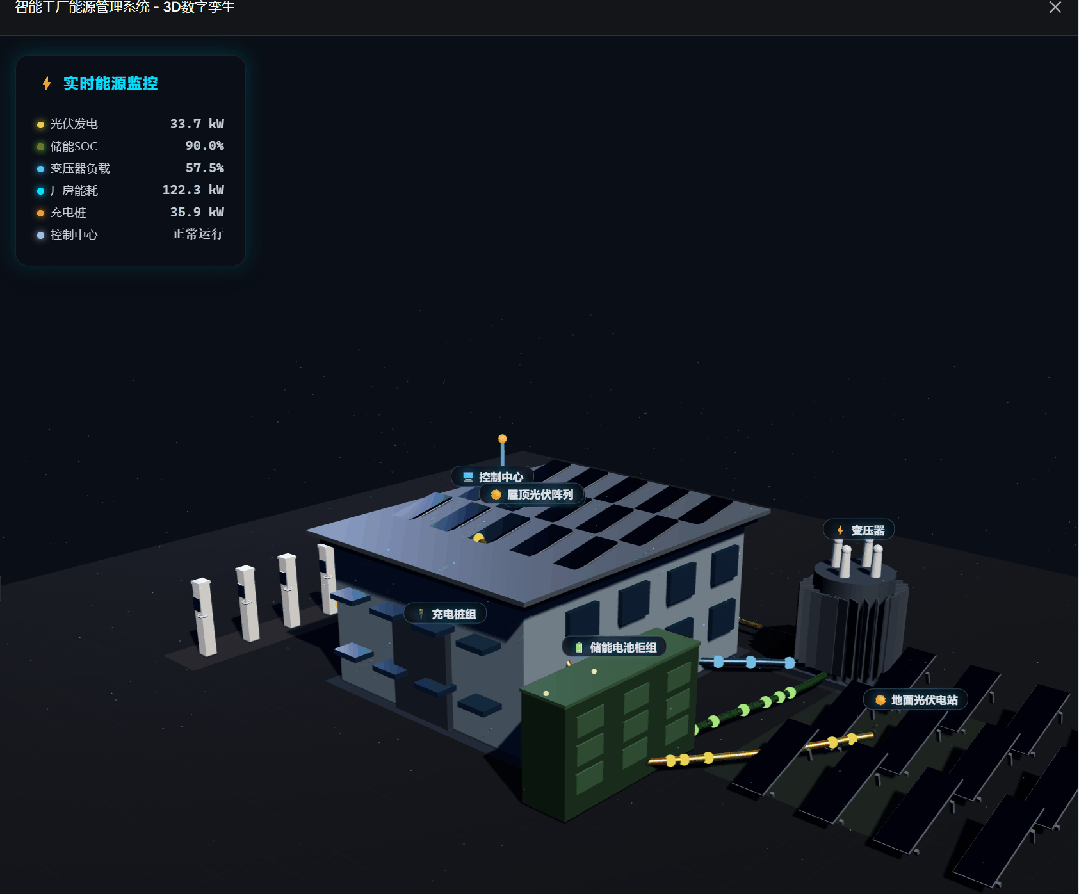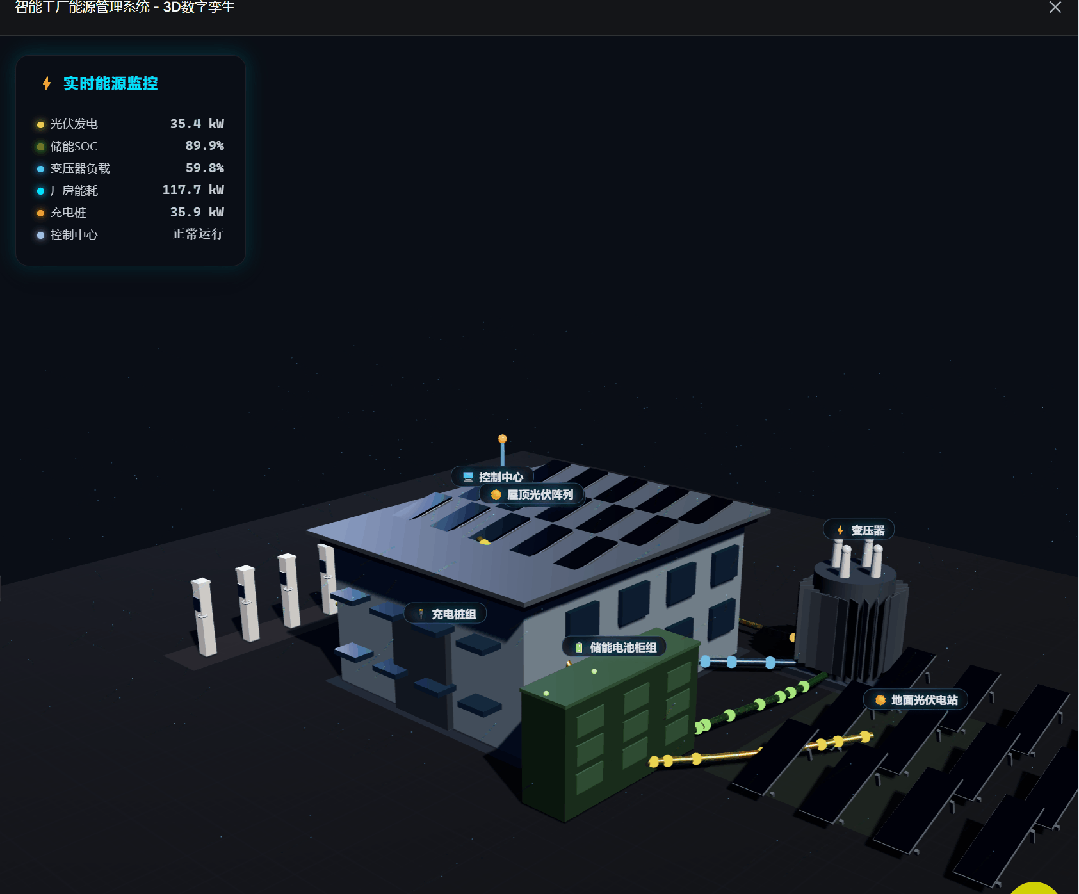
This task is useful because it exposes whether a model can plan a complex frontend scene, generate enough visual detail, and keep interactivity working in one file.
4. Test case 3: screenshot-to-HTML UI recreation
The third task asked the model to recreate a product UI screenshot as a complete runnable single-file HTML page.
The prompt required high-fidelity layout, colors, typography hierarchy, card structure, button styling, spacing, shadows, responsive desktop and mobile behavior, reasonable Chinese product copy, and basic interactions such as tabs, filters, hover states, and a modal or drawer.
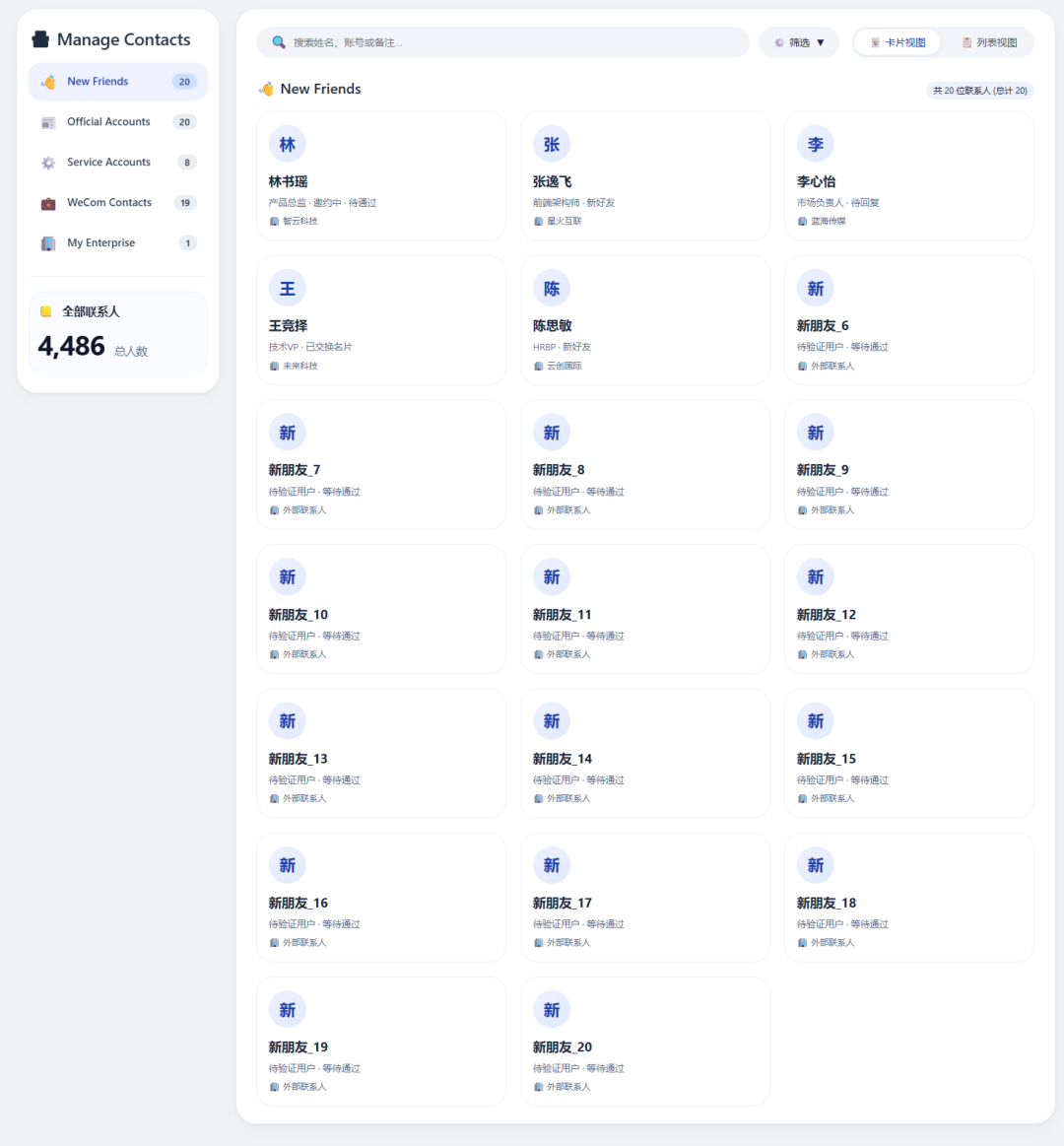
This was the input screenshot:
MiniMax M3 generated an HTML file. The screenshot of its result:
Opened in the browser, the UI looked like this:
GPT-5.5 generated this UI:
DeepSeek-V4-Pro generated this UI:
5. Gemini-3.1-Pro judging results
To make the comparison more objective, I sent the three cases to Gemini-3.1-Pro as the judge.
For the first case, Gemini-3.1-Pro scored the models across three dimensions:
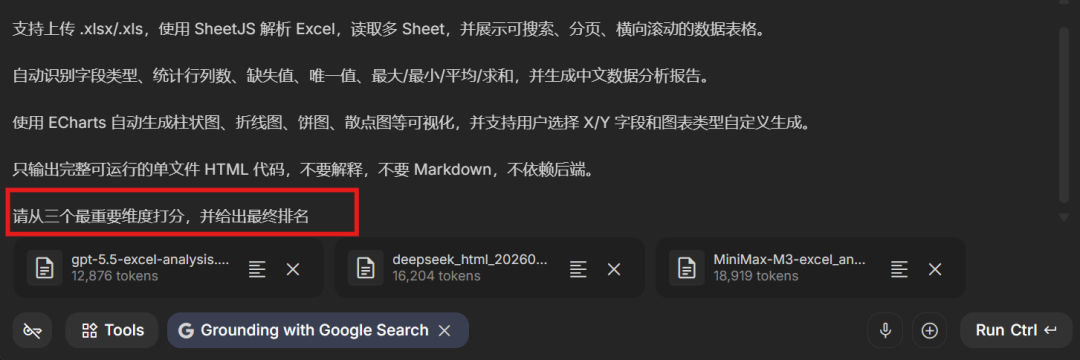
The final ranking:
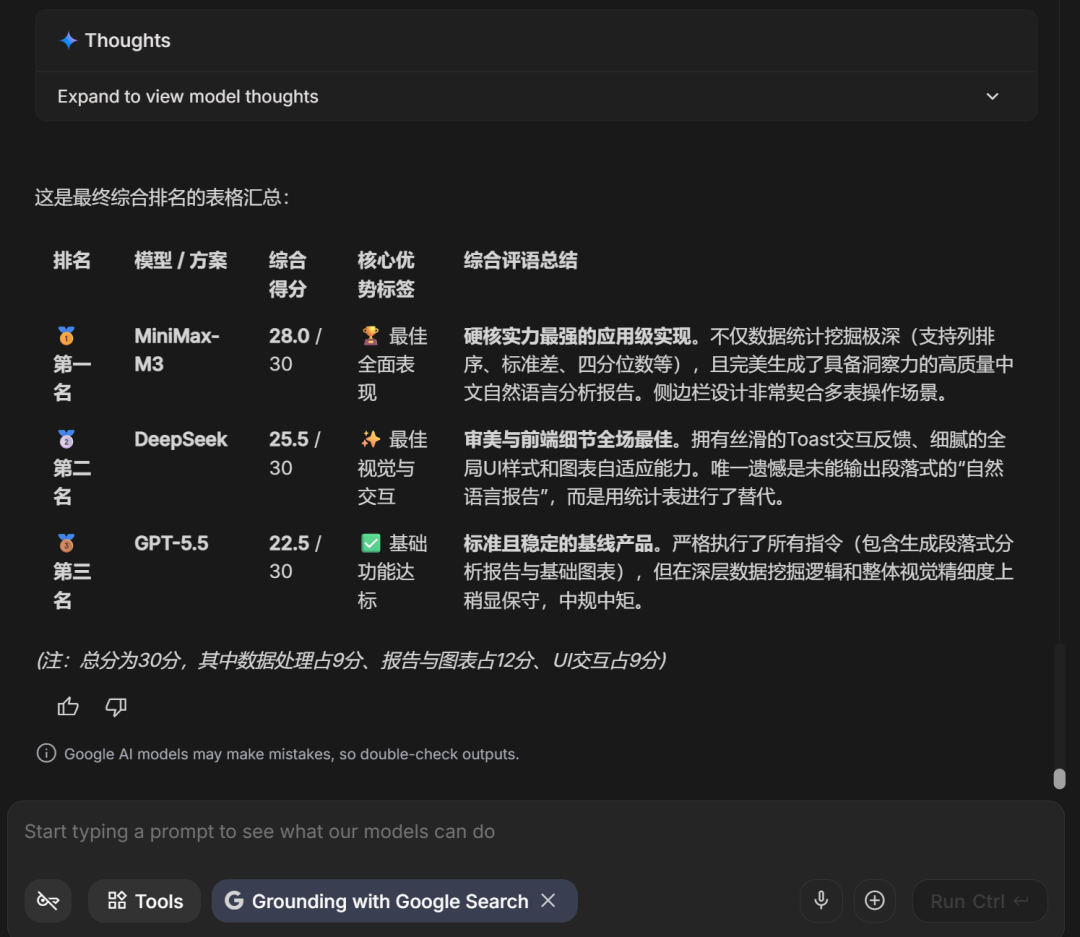
MiniMax M3 ranked first, DeepSeek-V4-Pro ranked second, and GPT-5.5 ranked third.
For the second test case, I sent the generated Three.js results to Gemini-3.1-Pro:
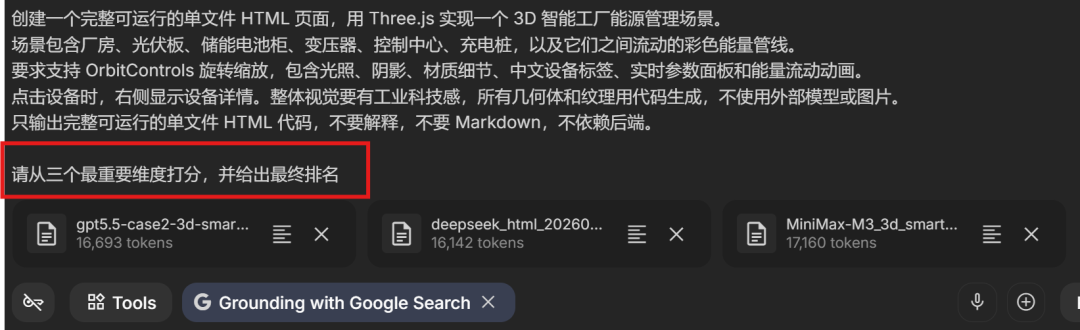
The final ranking:
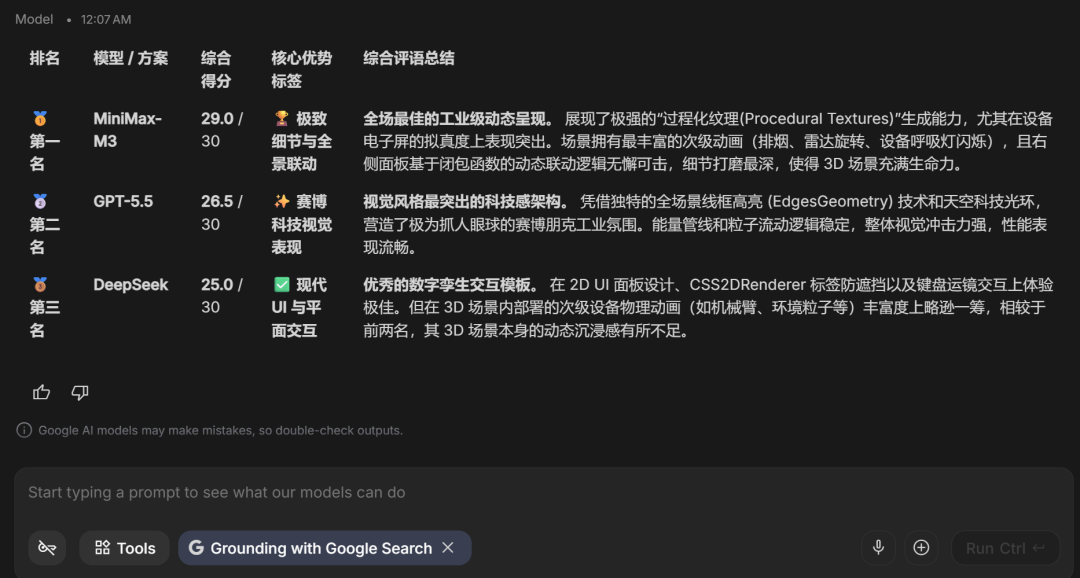
MiniMax M3 ranked first, GPT-5.5 ranked second, and DeepSeek-V4-Pro ranked third by a small margin.
For the third screenshot-recreation case, I sent the outputs to Gemini-3.1-Pro:
The final ranking:
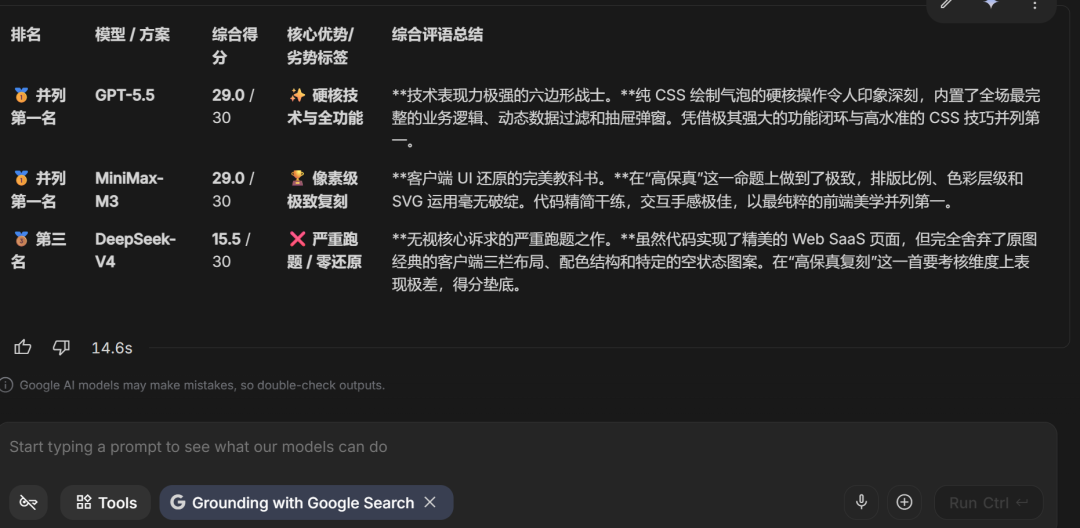
GPT-5.5 and MiniMax M3 tied for first, while DeepSeek-V4-Pro ranked third.
Final verdict
Across these three coding-agent tasks, MiniMax M3 ranked first or tied for first every time.
The most surprising part was its frontend and visual-generation performance. In the Excel tool, the 3D smart factory, and the screenshot-to-HTML UI recreation, MiniMax M3 showed strong completeness and visual execution.
I did not expect it to beat GPT-5.5 in the Excel analytics web-app test. I originally assumed GPT-5.5 would be strongest in data-analysis-oriented frontend tasks, but this benchmark produced a different result.
My takeaway: MiniMax M3 has entered the first tier for complex frontend generation, visual web tasks, and agent-style coding workflows. If your use case involves building interactive web pages from long prompts, it is worth testing seriously.
From Field Note to Buying Decision
Use this AI field note to choose software, APIs, agents, search, and security tools.
AI Field Note FAQ
Use this field note as evidence before choosing AI tools
How should I use this AI field note?
Use it as hands-on evidence from a real AI workflow, then compare the related software category, model benchmark, API guide, security checklist, and tool alternatives before choosing a product.
Is this field note enough to choose an AI tool?
No. Treat the field note as practical context, then validate pricing, privacy, integration effort, reliability, benchmark fit, and team workflow before spending budget.
What should I read after MiniMax M3 Coding Benchmark: Testing It Against GPT-5.5 and DeepSeek-V4?
Open AI Software Buyer Guides, AI Model Benchmarks, Best AI Coding Agents, Enterprise AI Search Tools, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
When should teams re-test the result from this field note?
Re-test when the model, product plan, pricing, API behavior, prompt workflow, data policy, browser support, or deployment environment changes.
Continue