English translation
DeepSeek Full-Version Deployment: A Game-Changing Setup
AI Article Decision Snapshot
Turn the lesson into workflow, model, budget, and security checks before choosing tools.
Use this quick snapshot before leaving the article. It keeps the next search tied to practical AI software, model/API, cost, privacy, and implementation questions.
Workflow fit
Identify the real job behind the article: coding, research, document review, support, analytics, content, or internal automation.
Model or tool decision
Decide whether the next step is a software shortlist, an AI tool comparison, an API platform choice, or a model benchmark.
Budget and usage signal
Estimate seats, API calls, prompt volume, retries, review time, and fallback work before assuming the workflow is cheap.
Security and privacy review
Check whether source code, customer data, private documents, prompts, logs, or embeddings will enter the AI workflow.

The most frequently overlooked aspect of a full-featured deployment is resilience. Getting the model up and running is only the first step—you must also know how to restart the service when it fails, where logs are stored, whether ports are occupied, and whether GPU memory is being preempted by other processes. In real-world usage, stability matters far more than a single successful screenshot.
After deployment, conduct a minimal stress test: submit ten consecutive queries—including short questions, long-form questions, and code-related questions—and observe response latency and resource utilization. If your system is already nearing full capacity, avoid opening it up to multiple users prematurely.
This article details the deployment strategy for DeepSeek-67B (i.e., the “full-featured” edition), with special emphasis on hardware configuration selection.
In 2025, the open-sourcing of DeepSeek-R1 sent shockwaves across the AI community—like a boulder dropped into still water. Within 48 hours on GitHub, it surpassed 10,000 stars; over 2,000 derivative projects emerged shortly thereafter—signaling unprecedented vitality in China’s AI ecosystem.
As shown below, DeepSeek’s GitHub star count has now exceeded 80,000, while its derivative projects have surpassed 10,000:

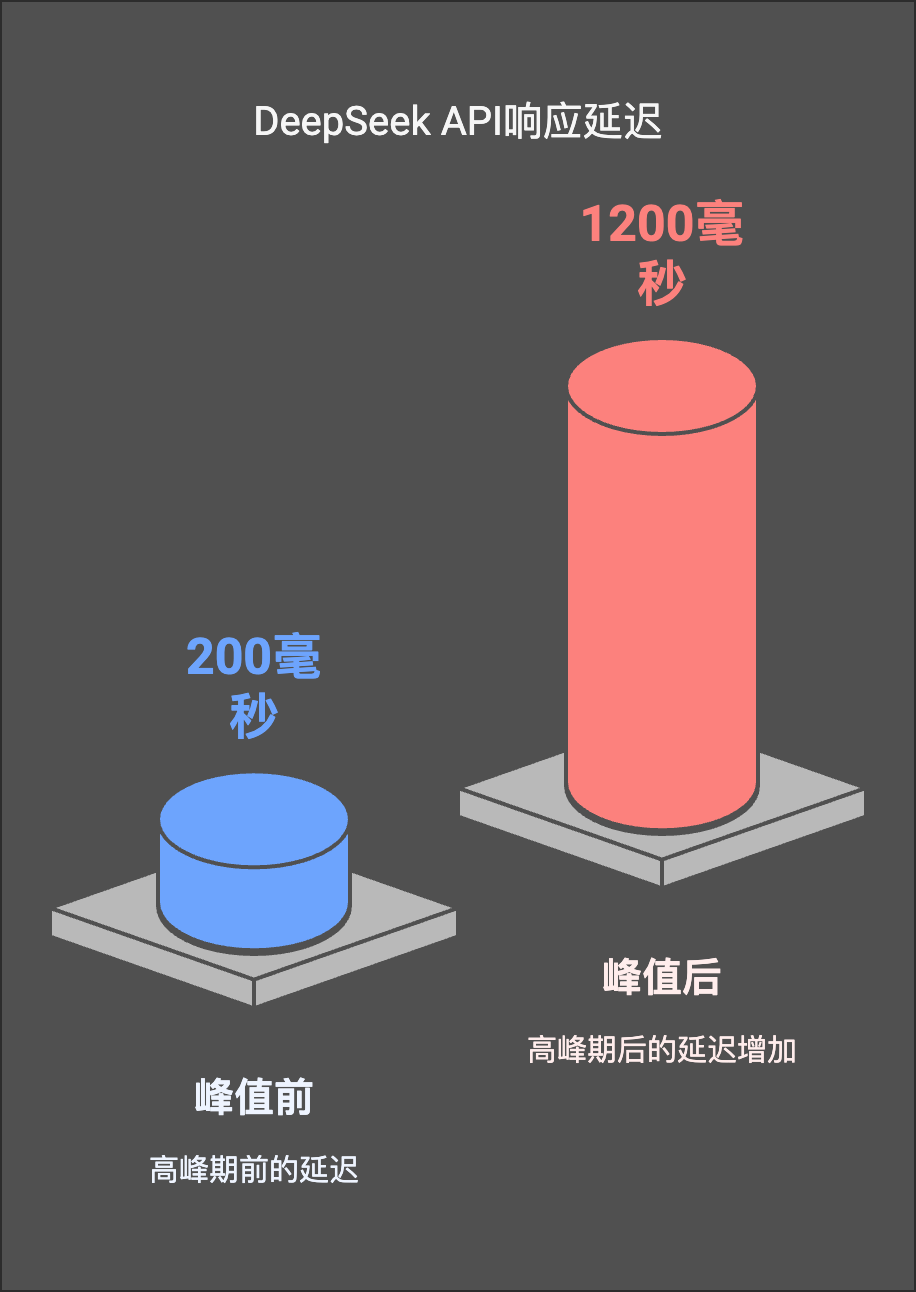
Yet beneath this celebration, a quiet but intense competition for compute resources is unfolding. Reports indicate that peak-time API response latency for DeepSeek has surged from 200 ms to 1.2 seconds, with some regions even triggering traffic circuit-breaker mechanisms.
This is not a technical flaw—it reflects an inherent limitation of public cloud compute scheduling: when thousands of enterprises compete for the same pool of GPU resources, smaller players inevitably become casualties of the “resource-hunger game.”
A representative case comes from an AIGC startup. Using a public-cloud H100 cluster to train a domain-specific large language model (13B parameters), their monthly bill reached ¥800,000, nearly 40% of which was spent on virtualization overhead and idle-resource billing. Even more sobering: attempts to cut costs revealed that extending training duration by 20% reduced expenses by just 5%—a pricing model that effectively penalizes those who lack deep pockets.
The Life-or-Death Game for SMEs
Within narratives of AI democratization, one cold reality is rarely acknowledged: running a 70B-parameter DeepSeek model can consume half a startup’s monthly revenue—in a single day. Test data from an e-commerce AI customer-service platform shows that reducing inference latency from 500 ms to 300 ms boosts conversion rates by 2.3%—yet the associated GPU cluster cost remains prohibitively high for SMEs handling millions of daily requests.
H200 Bare-Metal Servers: A Technological Revolution Breaking Compute Monopolies
Performance Breakthrough: Redefining Productivity Boundaries
The arrival of NVIDIA’s H200 GPU represents a “dimensional strike” against compute scarcity. Its 141 GB of HBM3e memory enables loading three full distilled DeepSeek-R1 models simultaneously onto a single GPU—eliminating over 30% of GPU memory waste previously incurred during model switching.

Real-world benchmarks from an autonomous driving team show that: ✅ An 8-GPU H200 cluster increases batch size by 2.4× compared to H100-based setups, ✅ Cutting total training time by 58%.
Even more transformative is the 4.8 TB/s memory bandwidth—a leap enabling concurrent execution of traditionally siloed workloads. For example, a cross-border e-commerce team leveraged this capability to triple AIGC asset generation throughput: the system now simultaneously writes product copy, designs promotional posters, and auto-generates multilingual variants—all within under 800 ms end-to-end latency.
Security & Autonomy: Reclaiming Data Sovereignty
Compute autonomy and data sovereignty are inseparable. Unlike GPU virtual machines, H200 bare-metal servers allocate dedicated physical resources to a single tenant. Their hardware-level isolation—combined with built-in security modules—enables end-to-end encryption across memory, storage, and networking layers. When enterprises deploy DeepSeek privately on such infrastructure, they not only eliminate risks of sensitive data leakage but also significantly improve inference accuracy through localized fine-tuning. This “closed-loop data + dedicated compute” paradigm is redefining enterprise AI security standards.
DigitalOcean’s Latest H200 Bare-Metal Servers

In the compute services arena, publicly traded cloud provider DigitalOcean stands apart through its “minimalist philosophy” and transparent, cost-effective pricing. Unlike hyperscalers (e.g., AWS, Google Cloud) with complex, opaque architectures, DigitalOcean’s H200 GPU bare-metal offering adheres to three core principles:
Transparent Cost Structure. No hidden fees—ever. Free bandwidth allowances, zero virtualization overhead, and predictable per-unit pricing empower businesses to precisely forecast ROI on every compute dollar spent. Benchmark tests by an AI startup found that identical model-training workloads cost only 50–60% on DigitalOcean versus leading hyperscalers.
Blazing-Fast Provisioning. Delivery in just 1–2 business days, powered by pre-configured hardware pools and automated deployment pipelines. When your team needs to launch an AI demo system within days for a competitive bid, this “plug-and-play” speed becomes your decisive advantage.
Localized Ecosystem Integration. To better serve Chinese enterprises, DigitalOcean has formed an exclusive strategic partnership with Zhuopu Cloud. DigitalOcean supplies compliant, legally authorized servers and professional operations support—while Zhuopu Cloud delivers tailored business consulting and technical assistance to Chinese customers. Multiple Chinese enterprises are already leveraging DigitalOcean’s GPU cloud offerings—including H100 GPU Cloud Servers (pay-as-you-go), L40s GPU Cloud Servers, and H100 Bare-Metal Servers (contract-based).
DigitalOcean’s newly launched NVIDIA HGX H200 Bare-Metal Servers offer flexible deployment options—operating as standalone units or scaling into multi-node clusters. This gives you full control over both hardware and software environments, empowering you to build custom AI infrastructure capable of training large language models (LLMs), running generative AI workloads, or optimizing proprietary systems—with unmatched agility.
Ready to seize first-mover advantage in the compute race? Contact Zhuopu Cloud—the exclusive strategic partner of DigitalOcean in China (aidroplet.cn) to reserve capacity today—or explore how NVIDIA HGX H200–powered bare-metal servers can accelerate your path to faster, smarter AI applications.

Summary
This article outlines the optimal hardware strategy for deploying DeepSeek’s full-featured edition. The NVIDIA H200 GPU delivers groundbreaking performance: an 8-GPU H200 cluster reduces training time by 58% versus H100, while also dramatically lowering inference latency.
DigitalOcean—a leading provider of H200 GPU infrastructure—has partnered exclusively with Zhuopu Cloud to serve the Chinese market. Together, they deliver highly efficient, low-latency DeepSeek deployments—ideal for enterprises seeking responsive, production-grade AI capabilities. Interested readers are encouraged to learn more.
Apply This Lesson
Turn this article into AI software, model, API, and security decisions.
English Article FAQ
Use this article as evidence before choosing AI tools
How should I use this AI Tutorials article?
Use it as the implementation or learning layer, then connect the idea to AI software buyer guides, tool comparisons, benchmarks, API choices, and security checks before making a production decision.
Is this English article different from the Chinese original?
The English edition is localized for global AI readers while preserving the original diagrams, screenshots, prompts, code examples, and source context from the Chinese article.
What should I read after DeepSeek Full-Version Deployment: A Game-Changing Setup?
Continue with AI Software Buyer Guides, AI Tools Workbench, Best AI Coding Agents, AI Model Benchmarks, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
Can this article alone choose an AI product or model?
No. Treat the article as evidence and context, then validate fit with pricing, privacy requirements, integration effort, benchmark results, workflow tests, and fallback planning.
Continue