English translation
DeepSeek Full Version Runs Instantly in Browser — Truly Legendary Performance
AI Article Decision Snapshot
Turn the lesson into workflow, model, budget, and security checks before choosing tools.
Use this quick snapshot before leaving the article. It keeps the next search tied to practical AI software, model/API, cost, privacy, and implementation questions.
Workflow fit
Identify the real job behind the article: coding, research, document review, support, analytics, content, or internal automation.
Model or tool decision
Decide whether the next step is a software shortlist, an AI tool comparison, an API platform choice, or a model benchmark.
Budget and usage signal
Estimate seats, API calls, prompt volume, retries, review time, and fallback work before assuming the workflow is cheap.
Security and privacy review
Check whether source code, customer data, private documents, prompts, logs, or embeddings will enter the AI workflow.

The biggest appeal of the full-parameter (i.e., “full-blooded”) DeepSeek online service is its zero-configuration setup. However, I evaluate such services across three key metrics:
- Whether queues form during peak hours,
- Whether long-context handling remains stable, and
- Whether pricing supports high-frequency usage.
Judging solely by a single demo’s speed can easily lead to underestimating long-term operational costs.
When trialing online services, I recommend consistently testing with three question types:
- Short Q&A,
- Long-document summarization, and
- Code-related tasks.
Ask several questions per category in sequence—and record both response latency and answer quality. This gives you objective, personal benchmark data, enabling meaningful comparisons between local and online models—not just subjective impressions.
Recently, more readers have left comments in our public backend reporting DeepSeek performance issues: messages like “Server busy—please try again later”, shown below. As DeepSeek’s popularity grows, traffic will inevitably surge—making service congestion highly likely to persist.
This article addresses that very congestion issue—so if you want smooth, reliable DeepSeek access, keep reading.
1 How DeepSeek’s Parameter Scale Impacts Inference Performance
While using DeepSeek, some readers may overlook—or simply not know—a critical fact: DeepSeek comes in multiple model sizes. As shown in the screenshot below (taken from the DeepSeek-R1 paper), six distilled variants are highlighted: 1.5B, 7B, up to 70B. These are all distilled versions—smaller, lighter-weight models. By contrast, the “standard” DeepSeek-R1—the one most commonly referenced—is actually 671B in size:
- 447× larger than the smallest distilled version (1.5B), and
- 21× larger than the 32B distilled variant.

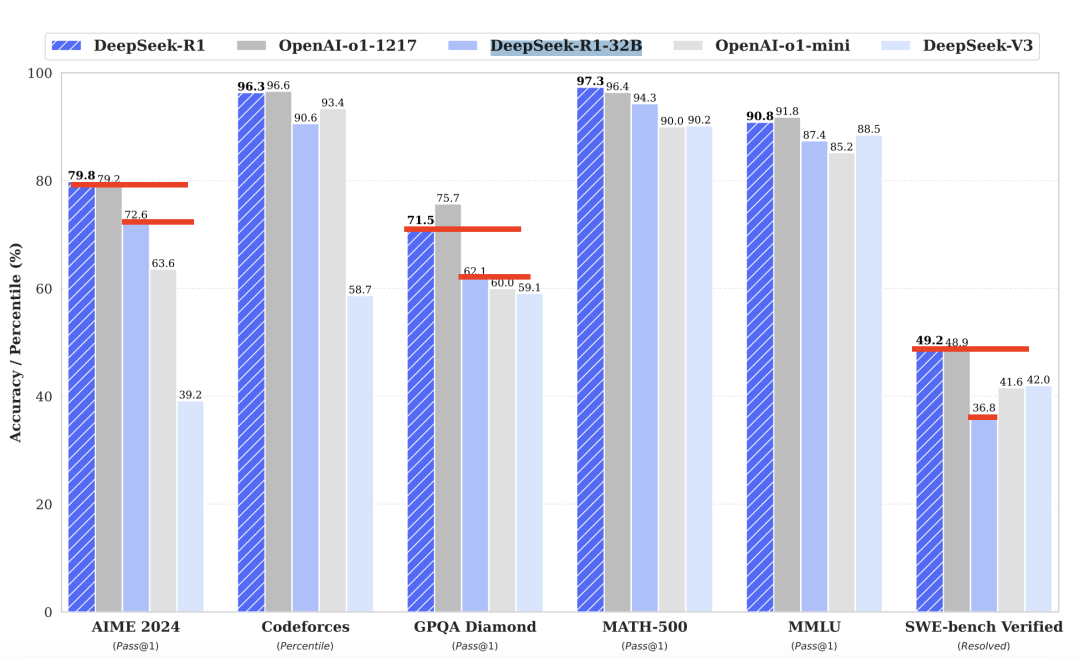
Per established large-model scaling laws, inference capability generally improves with parameter count—i.e., larger models deliver stronger reasoning performance. Consequently, distilled versions inevitably underperform the full 671B DeepSeek-R1. For precise degradation figures, refer to the R1 paper: each column represents a benchmark dataset; the two labeled entries per column show results for the full R1 (671B) and the 32B distilled version respectively. The vertical gap indicates performance loss. As shown, on AIME 2024, GPQA Diamond, and SWE-bench Verified benchmarks, the 32B variant lags behind full R1 by 7.2, 9.4, and 12.4 points, respectively—confirming substantial reasoning capability loss in distilled models.
Running the full 671B R1 locally demands extreme computational resources—far beyond typical consumer hardware. Hence, installing smaller distilled models (e.g., 1.5B) is usually recommended for local deployment. But for most real-world applications—especially those demanding high reasoning fidelity—we strongly recommend using the full-parameter R1 whenever possible, to maximize AI’s problem-solving power.
However, DeepSeek’s official web interface currently suffers from severe latency due to overwhelming traffic. Today, we introduce an alternative online platform hosting the full 671B R1—tested extensively over the past week, delivering consistently smooth, rapid responses.
2 An Online Platform That Runs Full-Parameter R1 at Blazing Speed
Go straight to the portal: wenxiaobai.com
Upon landing on the homepage, you’ll see clear labeling: “Full-Parameter DeepThinking R1 Model”—i.e., the latest DeepSeek large language model with 671B parameters:
The left sidebar features the familiar chat interface. The site’s name? “Ask Xiao Bai” (Wen Xiao Bai).

On my first visit, a natural question arose: “Is it truly the full-parameter R1?” To verify, I conducted several tests.
The most direct approach—asking the model outright about its parameter count—proved unreliable. Modern LLMs often struggle to self-identify accurately; many cannot even state their own model name or architecture definitively:

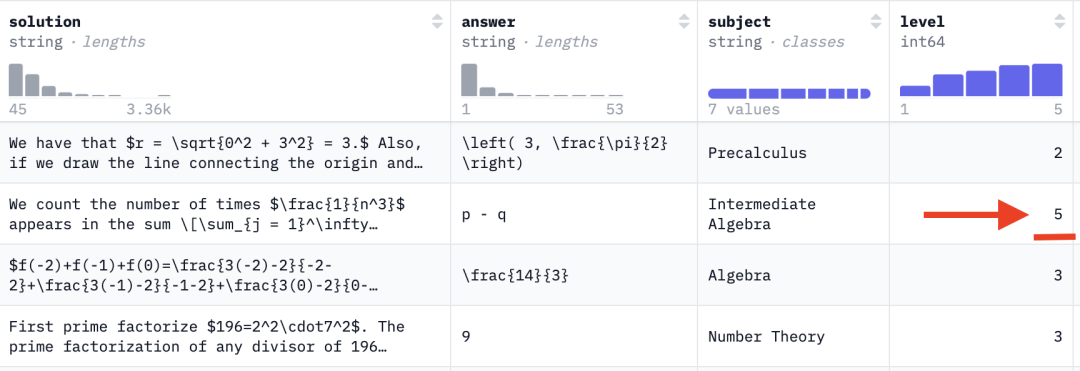
After this method failed, I turned to performance-based verification. Simple questions won’t reveal differences—only high-difficulty tasks can. The industry standard for such evaluation is the MATH-500 benchmark, whose problems span five difficulty levels. Level 5 represents the hardest tier—covering advanced calculus, mathematical analysis, and Olympiad-level problems (e.g., AIME). Below is an overview of MATH-500:
Now, let’s rigorously test whether Ask Xiao Bai truly deploys full-parameter R1—by tackling Level 5 problems exclusively. Below is the first test case. Due to WeChat Official Account GIF limitations (frame count & resolution), only the first three frames are shown. The screen recording was made at native speed, with no acceleration:

This problem involves infinite series—a topic from university-level advanced calculus and mathematical analysis—so difficulty is nontrivial. Per MATH-500’s ground-truth answer key, the correct solution is p − q, as shown:
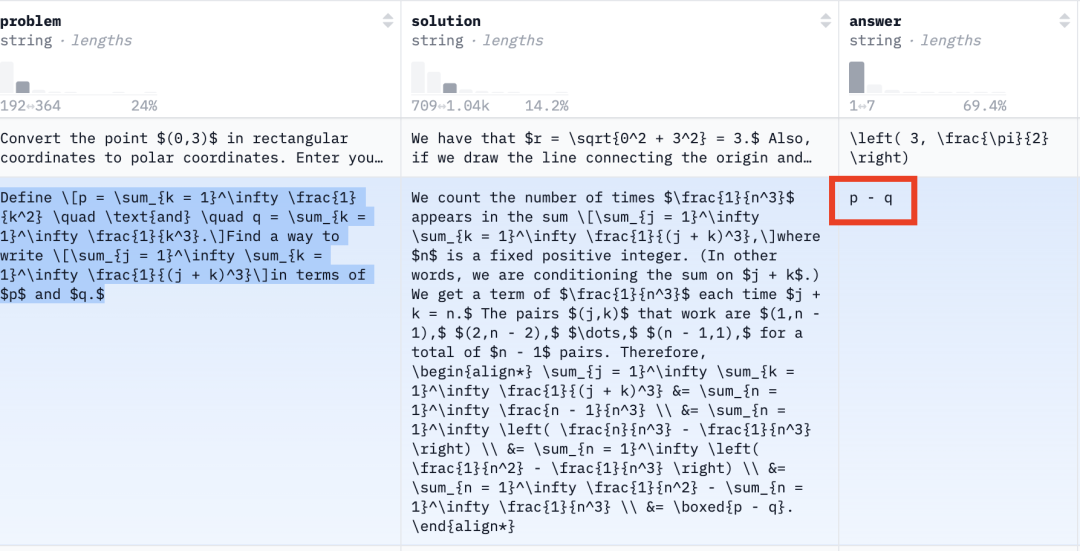
The platform’s output? Also p − q—✅ First test passed.
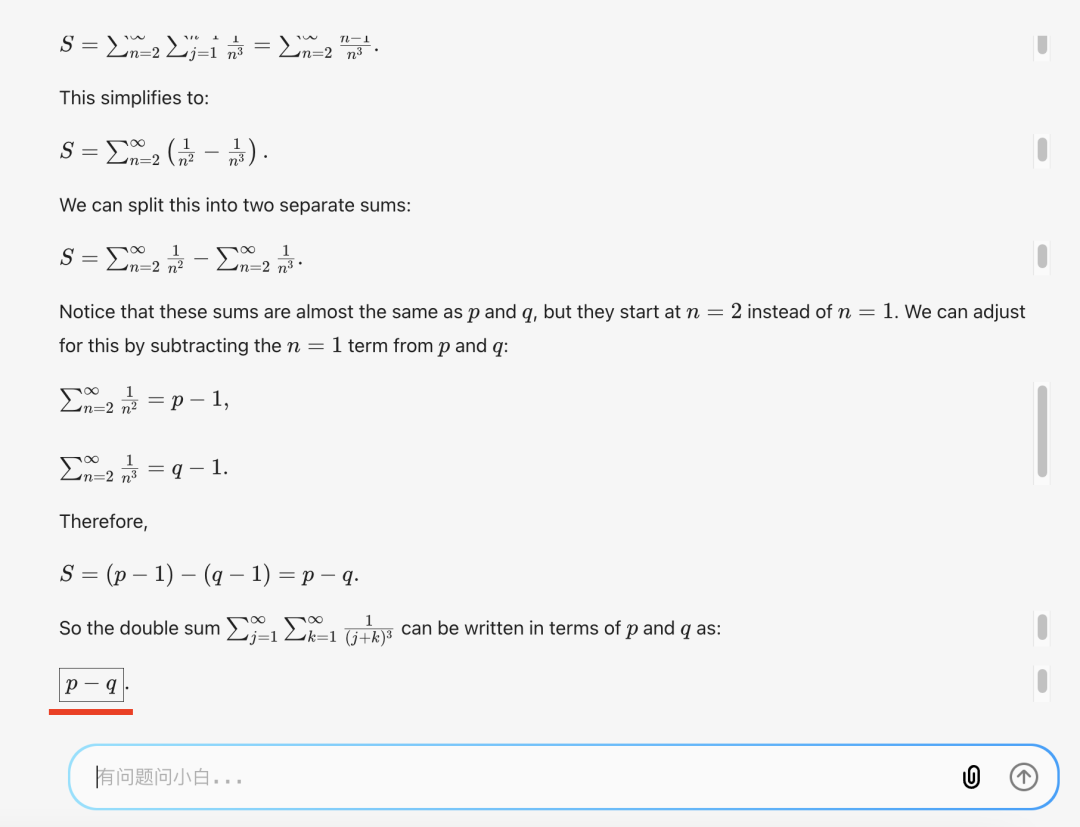
Second test—also Level 5—covers polynomial interpolation and Lagrange interpolation, typical of AIME-style competitions. The GIF below captures the interaction:

Its step-by-step reasoning and final answer appear below:

MATH-500’s official answer matches exactly—✅ Second test passed.
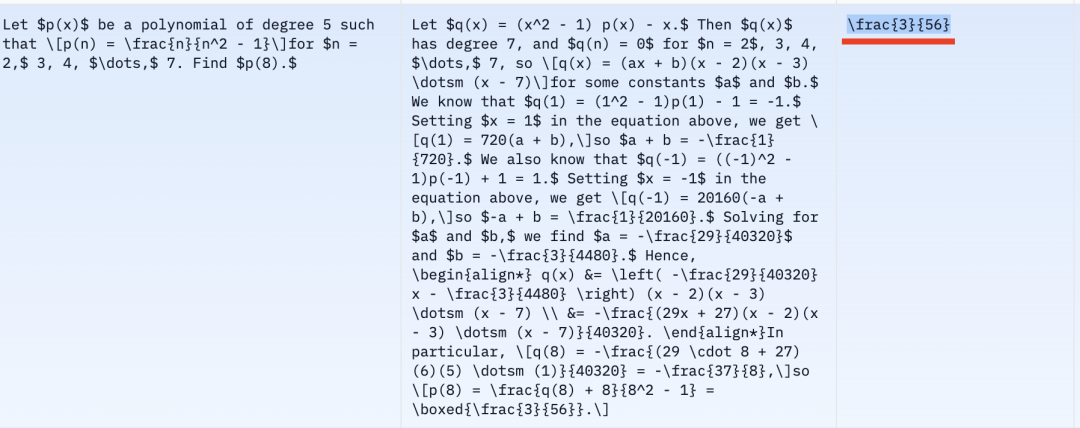
We continued through ten Level-5 problems in Round 1. Ultimately, we ran four full rounds (40 total Level-5 problems). Accuracy per round:
- Round 1: 100%
- Round 2: 90%
- Round 3: 90%
- Round 4: 100%
→ Overall accuracy: 95.0%
Two errors occurred:
- Round 2, Problem 4: Correct answer = 10, model output = 5
- Round 3, Problem 7: (Error details omitted for brevity)
Below is the erroneous reasoning trace for Round 2, Problem 4:

A 95.0% accuracy rate on the hardest problems available implies significantly higher accuracy on easier tiers (Levels 1–4). Thus, the overall accuracy across all MATH-500 levels should exceed the 97.3% reported in the R1 paper—strongly suggesting this is the full-parameter R1. Readers are welcome to replicate and extend this validation at scale!
3 “Ask Xiao Bai”: Lightning-Fast Responses
During deep testing, I observed another standout advantage: extremely low latency. Refer to the two GIFs above—recorded with Kap (no speed-up applied, playback at original frame rate). Judge the response speed for yourself.
Compare this to DeepSeek’s official interface today: due to massive demand, responses stall indefinitely at “Thinking…”—a consequence of the full-parameter model’s heavy compute requirements. When inference servers are oversubscribed, delays become unavoidable:

The contrast is stark. Our recommendation? Use platforms strategically:
- For ultra-fast, stable, unlimited access—Ask Xiao Bai excels.
- No usage caps. Zero cost.
Below is their recent promotional material—confirmed accurate after extensive hands-on testing. Both web and mobile app versions are available:

Final Summary
- This article introduces wenxiaobai.com—a reliable, free, unlimited-access online platform running the full 671B DeepSeek-R1.
- Compared to its six distilled variants, full-R1 delivers superior reasoning—making it ideal for demanding tasks. Reserve distilled models only for local knowledge-base deployments where resource constraints apply.
- Rigorous evaluation using 40 Level-5 MATH-500 problems achieved 95.0% accuracy, strongly indicating full-parameter deployment.
- Beyond raw capability, Ask Xiao Bai delivers blazing inference speed, zero usage limits, and zero cost—a compelling alternative to official channels strained by traffic.
Apply This Lesson
Turn this article into AI software, model, API, and security decisions.
English Article FAQ
Use this article as evidence before choosing AI tools
How should I use this AI Tutorials article?
Use it as the implementation or learning layer, then connect the idea to AI software buyer guides, tool comparisons, benchmarks, API choices, and security checks before making a production decision.
Is this English article different from the Chinese original?
The English edition is localized for global AI readers while preserving the original diagrams, screenshots, prompts, code examples, and source context from the Chinese article.
What should I read after DeepSeek Full Version Runs Instantly in Browser — Truly Legendary Performance?
Continue with AI Software Buyer Guides, AI Tools Workbench, Best AI Coding Agents, AI Model Benchmarks, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
Can this article alone choose an AI product or model?
No. Treat the article as evidence and context, then validate fit with pricing, privacy requirements, integration effort, benchmark results, workflow tests, and fallback planning.
Continue