English translation
DeepSeek-R1 Explained: Key Concepts and Visual Guide
AI Article Decision Snapshot
Turn the lesson into workflow, model, budget, and security checks before choosing tools.
Use this quick snapshot before leaving the article. It keeps the next search tied to practical AI software, model/API, cost, privacy, and implementation questions.
Workflow fit
Identify the real job behind the article: coding, research, document review, support, analytics, content, or internal automation.
Model or tool decision
Decide whether the next step is a software shortlist, an AI tool comparison, an API platform choice, or a model benchmark.
Budget and usage signal
Estimate seats, API calls, prompt volume, retries, review time, and fallback work before assuming the workflow is cheap.
Security and privacy review
Check whether source code, customer data, private documents, prompts, logs, or embeddings will enter the AI workflow.

This article already includes several figures from the original paper. I added this diagram not to replace the paper, but to clarify the reading order: First, understand why R1-Zero is special; then, see why it still requires enhancements in readability and general-purpose capability; finally, grasp how R1 bridges advanced reasoning ability with real-world usability.
When reading the paper’s figures, follow two parallel threads:
- One traces how reasoning capability improves;
- The other tracks how responses become practically usable.
Focusing only on the first thread risks treating the model as a competition benchmark; focusing only on the second overlooks R1’s core technical contributions. Only by integrating both threads can ordinary developers gain an accurate, grounded understanding.
DeepSeek-R1: Key Insights (Visualized)
Full Training Pipeline of DeepSeek-R1
DeepSeek-R1 stands out primarily for its exceptional mathematical and logical reasoning capabilities—distinguishing it from general-purpose AI models. Its training strategy synergistically combines Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT), yielding an efficient yet highly capable reasoning model.
The entire training process consists of two core phases. Phase 1 starts from the base model described in the DeepSeek-V3 paper (not the final released version) and proceeds through SFT followed by pure RL optimization + general-purpose preference tuning, as illustrated below:
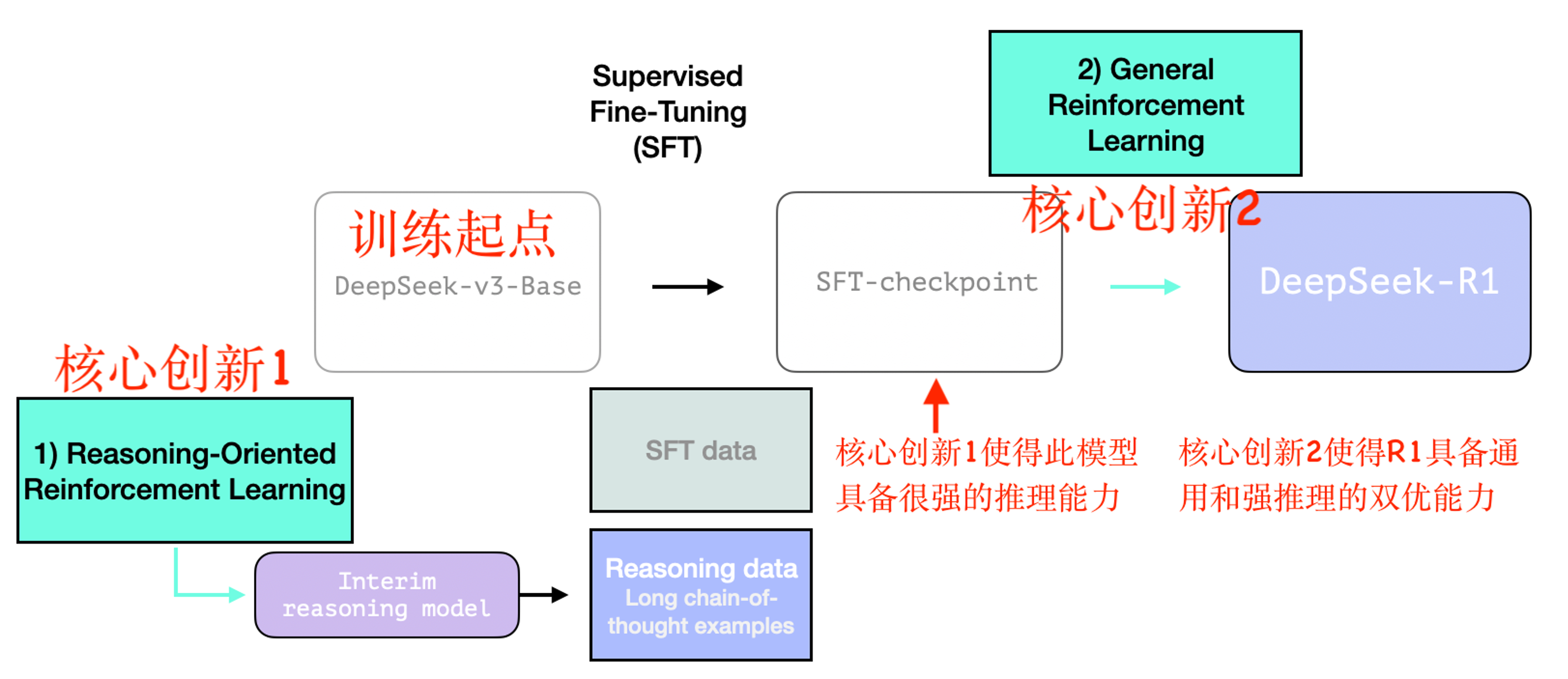
Training Starting Point: DeepSeek-R1 begins training from DeepSeek-v3-Base, serving as the foundational model upon which subsequent reasoning optimizations are built.
Core Innovation 1: Interim Reasoning Model Featuring R1-Zero
As shown in the figure, Reasoning-Oriented Reinforcement Learning yields an Interim Reasoning Model. The diagram details the training procedure for this intermediate model.
DeepSeek-R1’s Key Contribution: It is the first work to empirically validate that pure reinforcement learning alone can dramatically boost large-model reasoning performance—and it open-sources the pure-RL reasoning model: DeepSeek-R1-Zero.
R1-Zero generates high-quality reasoning data—including abundant long-chain Chain-of-Thought (CoT) examples—used to support the downstream SFT phase.
Core Innovation 2: General-Purpose Reinforcement Learning
Although R1-Zero (Phase 1) achieves remarkable gains in reasoning, it suffers from issues such as code-switching in responses and poor performance on non-reasoning tasks. To address these limitations, DeepSeek introduces a General-Purpose Reinforcement Learning framework.
As illustrated, General-Purpose RL trains on top of an SFT checkpoint, optimizing model behavior across both reasoning and general-purpose tasks.
Training Process of the Interim Reasoning Model (with R1-Zero)
The interim reasoning model occupies the most resource-intensive stage of training. Crucially, it is trained entirely via reasoning-oriented RL, bypassing SFT altogether—except for minimal SFT used only during RL cold-start initialization.
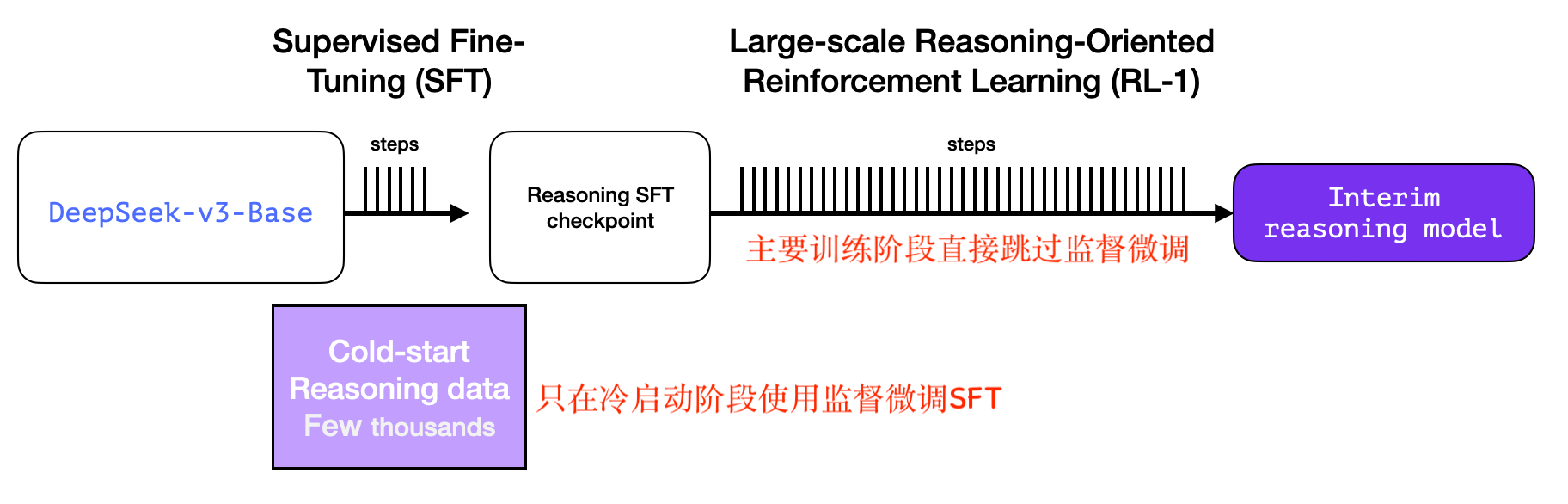
Large-scale reasoning-oriented RL critically depends on high-quality reasoning data—but manual annotation is prohibitively expensive and laborious. To solve this, the DeepSeek team trained R1-Zero, the very centerpiece of their innovation.
R1-Zero skips SFT entirely and trains directly with RL—as shown below (starting from V3, RL training begins immediately):

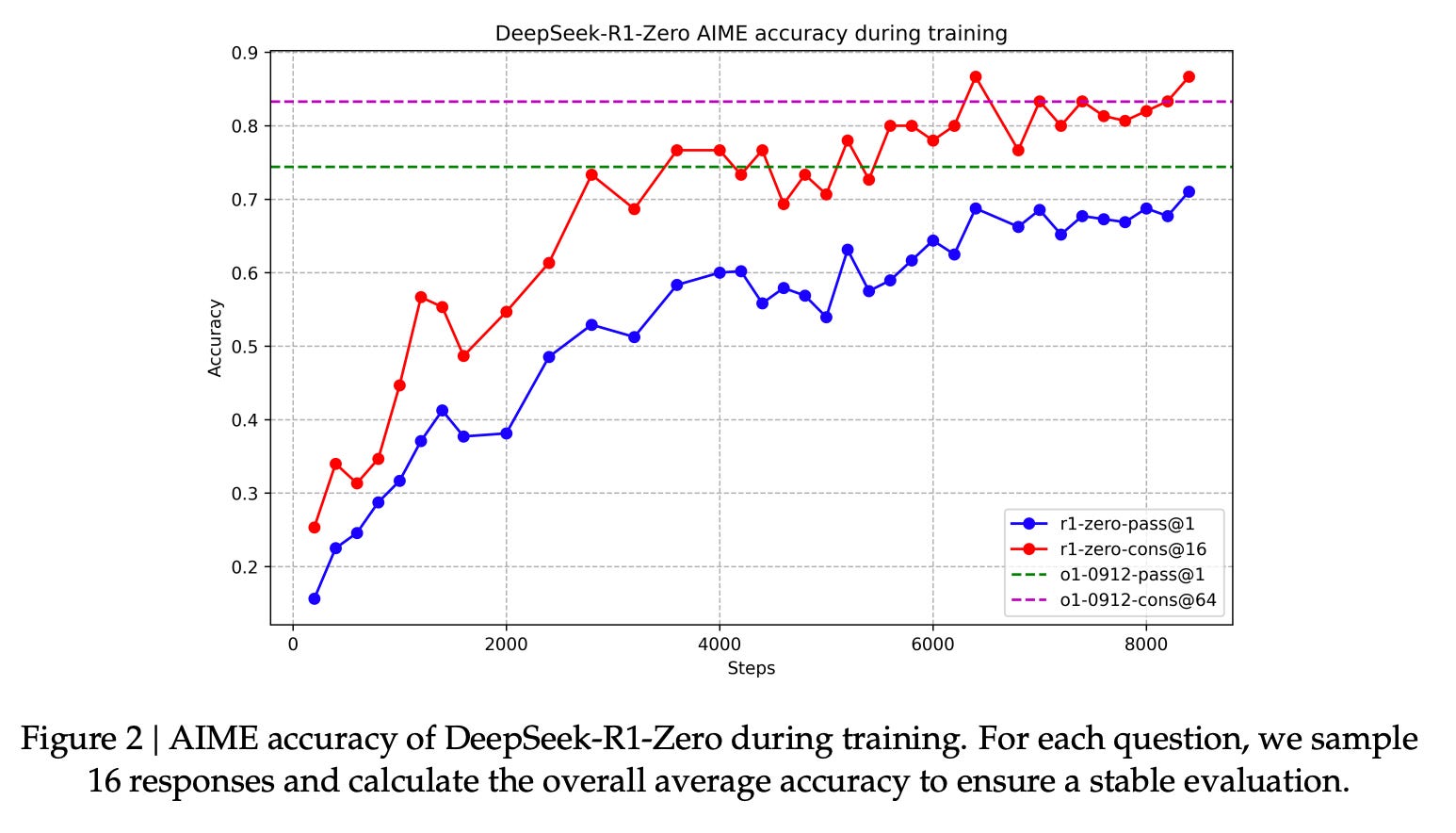
Remarkably, this approach delivers extraordinary results: R1-Zero’s reasoning performance surpasses OpenAI’s O1. As shown in the plot, the blue line indicates single-sample accuracy (pass@1), while the red line shows consensus accuracy over 16 independent samples (cons@16). Consensus-based inference significantly boosts final performance. The dashed line represents OpenAI O1’s baseline—demonstrating that DeepSeek-R1-Zero’s performance steadily approaches and ultimately exceeds O1.
Although the interim model excels at reasoning, its shortcomings in readability and multi-task versatility motivated the second innovation.
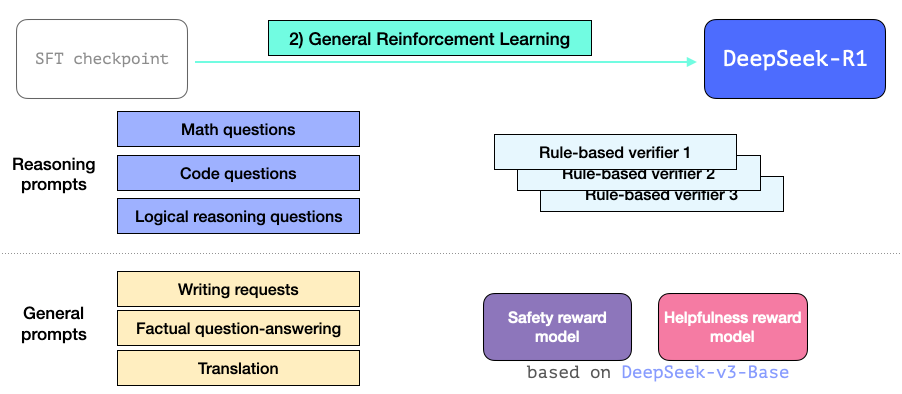
General-Purpose Reinforcement Learning Training Pipeline
Final preference tuning is illustrated below. After general-purpose RL training, R1 achieves outstanding performance not only on reasoning tasks—but also across diverse non-reasoning tasks. Because its capabilities now span non-reasoning applications, DeepSeek incorporates helpfulness and safety reward models (similar to those used in Llama)—to optimize prompt handling in these broader use cases.
Summary: DeepSeek-R1
- Interim Reasoning Model Generation: High-quality reasoning data (e.g., CoT examples) is generated directly via reasoning-oriented RL—significantly reducing reliance on manual annotation.
- General-Purpose RL Optimization: Using helpfulness- and safety-aware reward models, performance is jointly optimized across both reasoning and non-reasoning tasks, resulting in a broadly capable model.
Ultimately, DeepSeek-R1 unifies R1-Zero’s raw reasoning power with the adaptability conferred by general-purpose RL—yielding an efficient, high-performance AI model that excels at deep reasoning and seamlessly handles real-world, multi-faceted tasks.
Summary of Core Innovations
Interim Reasoning Model Generation: High-quality reasoning data (e.g., CoT examples) is generated directly via reasoning-oriented RL—minimizing dependence on manual annotation. General-Purpose RL Optimization: Helpfulness- and safety-aware reward models jointly optimize performance across reasoning and non-reasoning tasks—building a truly general-purpose model. End Result: DeepSeek-R1 integrates R1-Zero’s superior reasoning capability with the broad adaptability of general-purpose RL—delivering an efficient, high-performance AI model that masters complex reasoning while remaining robust and usable across diverse real-world applications.
Apply This Lesson
Turn this article into AI software, model, API, and security decisions.
English Article FAQ
Use this article as evidence before choosing AI tools
How should I use this AI Tutorials article?
Use it as the implementation or learning layer, then connect the idea to AI software buyer guides, tool comparisons, benchmarks, API choices, and security checks before making a production decision.
Is this English article different from the Chinese original?
The English edition is localized for global AI readers while preserving the original diagrams, screenshots, prompts, code examples, and source context from the Chinese article.
What should I read after DeepSeek-R1 Explained: Key Concepts and Visual Guide?
Continue with AI Software Buyer Guides, AI Tools Workbench, Best AI Coding Agents, AI Model Benchmarks, OpenAI vs Anthropic API, or LLM Security Tools depending on the decision you need to make.
Can this article alone choose an AI product or model?
No. Treat the article as evidence and context, then validate fit with pricing, privacy requirements, integration effort, benchmark results, workflow tests, and fallback planning.
Continue