4 DeepSeek-R1 精华图解
系列进度
DeepSeek本地部署 · 第 4 / 34 篇
 查看大图
查看大图这篇原本已经有不少论文图,我补这张图的目的不是替代论文,而是把阅读顺序画出来。先看 R1-Zero 为什么特别,再看它为什么还需要可读性和通用能力补强,最后再理解 R1 怎样把推理能力接到真实使用里。
读论文图时可以抓两条线:一条是推理能力怎么变强,另一条是回答怎么变得可用。只看第一条容易把模型当竞赛工具,只看第二条又会忽略 R1 的技术贡献。两条线合起来,才适合普通开发者理解。
DeepSeek-R1 精华图解
DeepSeek-R1 完整训练过程
DeepSeek-R1 的主要亮点在于其出色的数学和逻辑推理能力,与一般的通用 AI 模型有所区别。其训练方式结合了强化学习(RL)与监督微调(SFT),创造了一种高效训练且具有强大推理能力的 AI 模型。
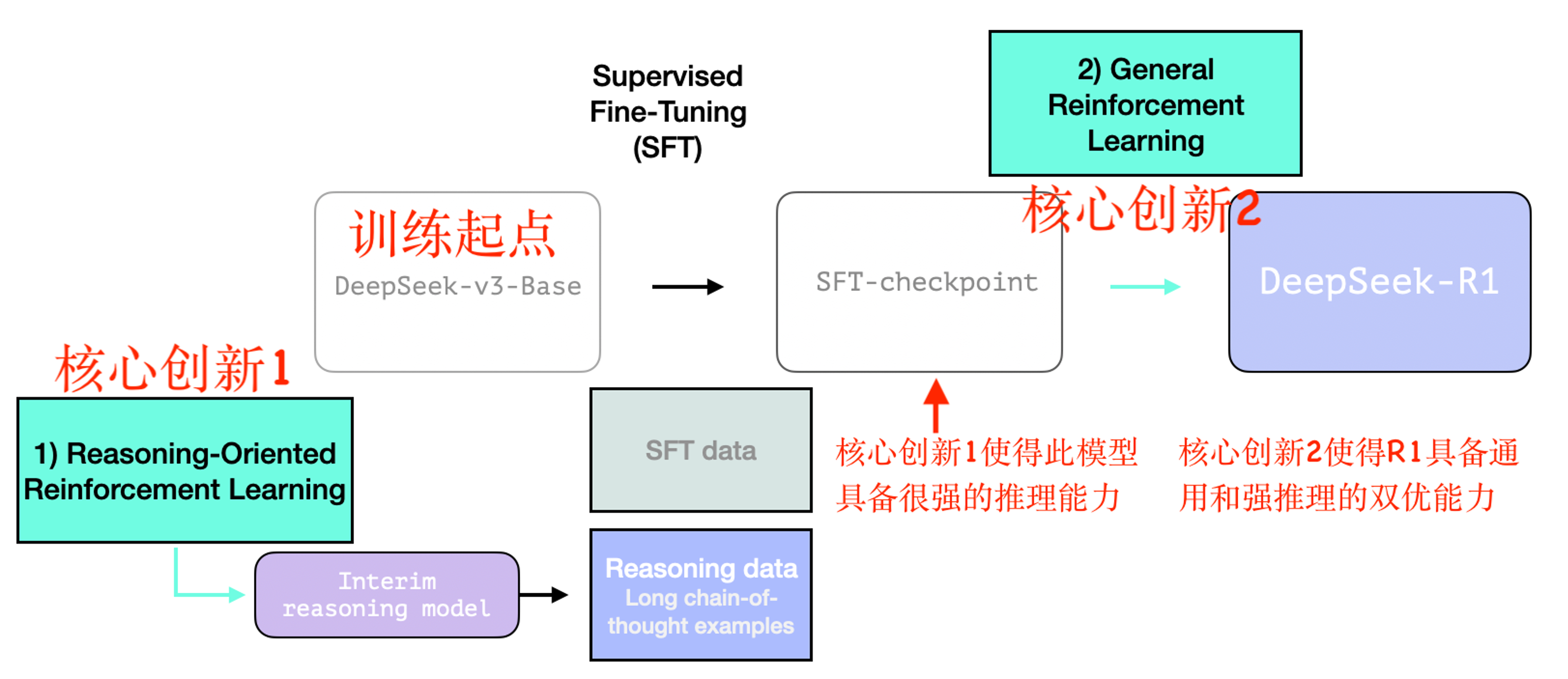
整个训练过程分为两个核心阶段。第一阶段基于 DeepSeek-V3 论文中的基础模型(非最终版本),经历了 SFT 和纯强化学习调优+通用性偏好调整,如下图所示:
 查看大图
查看大图训练起点:DeepSeek-R1 的训练起点是 DeepSeek-v3-Base,作为基础模型进行训练,为后续推理优化奠定基础。
核心创新1:含 R1-Zero 的中间推理模型
如图所示,推理导向的强化学习(Reasoning-Oriented Reinforcement Learning)产生了中间推理模型(Interim reasoning model)。图中详细说明了中间模型的训练过程。
DeepSeek-R1 核心贡献:首次验证通过纯强化学习也能大幅提升大模型推理能力,并开源纯强化学习推理模型 DeepSeek-R1-Zero。
R1-Zero 能生成高质量推理数据,包括大量长链式思维(Chain-of-Thought, CoT)示例,用于支持后续的 SFT 阶段。
核心创新2:通用强化学习
虽然第一阶段的 R1-Zero 显示了惊人的推理能力提升,但也存在回复时语言混合、非推理任务表现较差的问题。为了解决这些问题,DeepSeek 提出了通用强化学习训练框架。
如图所示,通用强化学习(General Reinforcement Learning)基于 SFT-checkpoint,对模型进行 RL 训练,优化其在推理任务和其他通用任务上的表现。
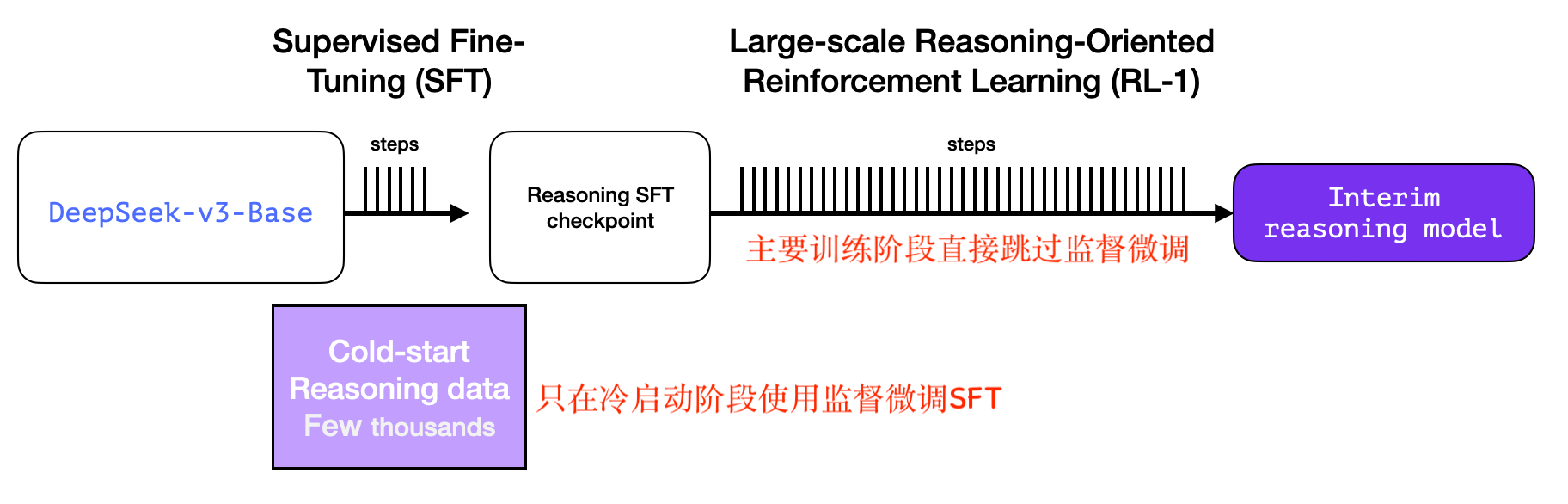
含 R1-Zero 的中间推理模型训练过程
中间模型占据了主要的训练精力阶段,实际上完全通过推理导向的强化学习直接训练而成,跳过了监督微调(SFT)阶段,仅在强化学习的冷启动阶段使用了 SFT。
 查看大图
查看大图大规模推理导向的强化学习训练必不可少的就是推理数据,手动标注成本昂贵且繁琐,因此 DeepSeek 团队训练了一个 R1-Zero 模型,这正是核心创新所在。
R1-Zero 完全跳过监督微调阶段,直接使用强化学习训练,如下图所示(基于 V3,直接开启强化学习训练):
 查看大图
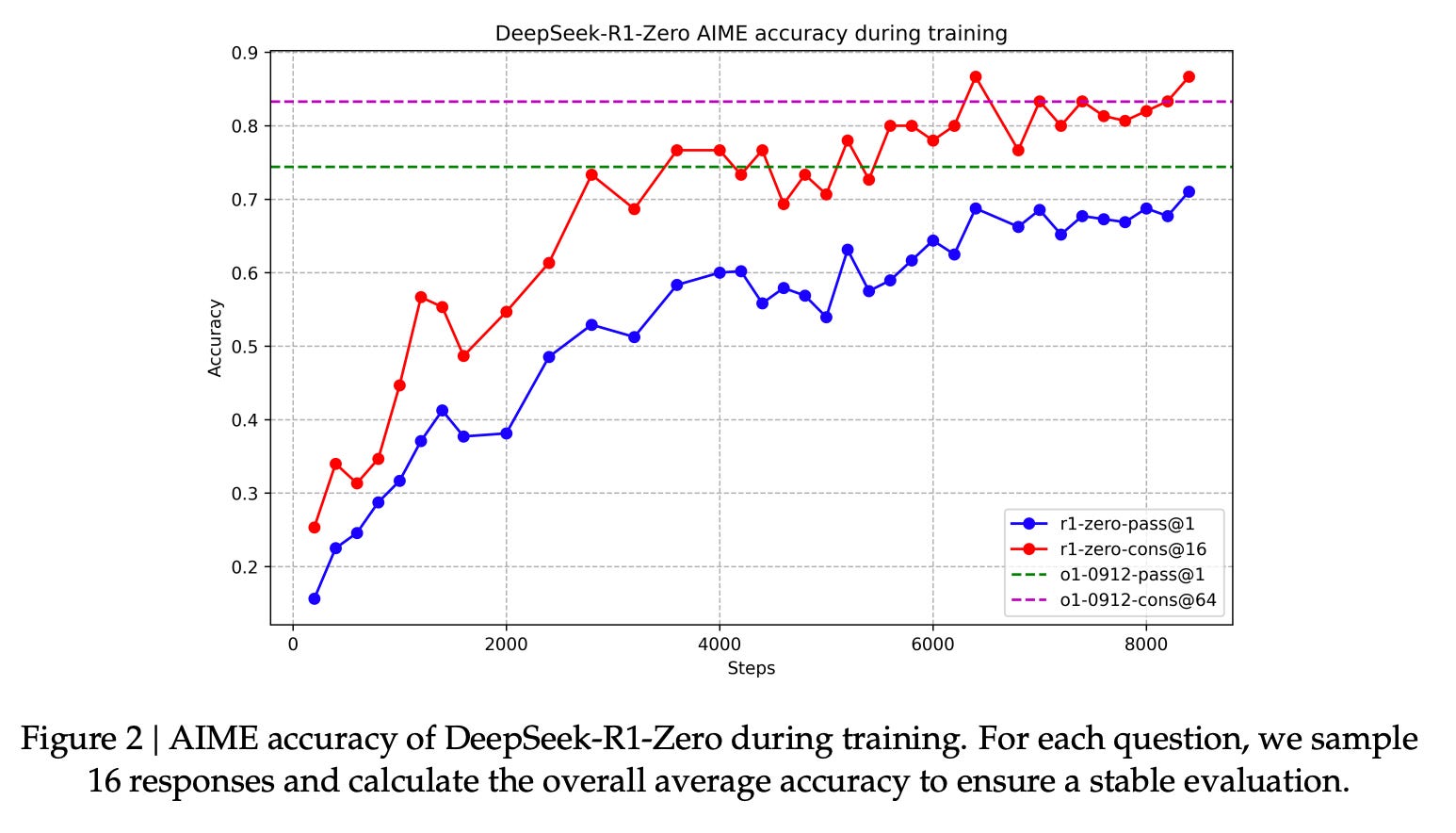
查看大图这样做竟然达到了惊人的效果,推理能力超越 OpenAI O1。如图所示,蓝线表示单次推理(pass@1)的准确率,红线表示 16 次推理取一致性结果(cons@16)的准确率,由此可见一致性推理显著提高了最终性能。虚线代表 OpenAI O1 的基准表现,图中显示 DeepSeek-R1-Zero 的性能逐步接近甚至超越了 OpenAI O1。
 查看大图
查看大图虽然中间模型推理能力很强,但存在可读性和多任务能力不足的问题,因此诞生了第二个创新。
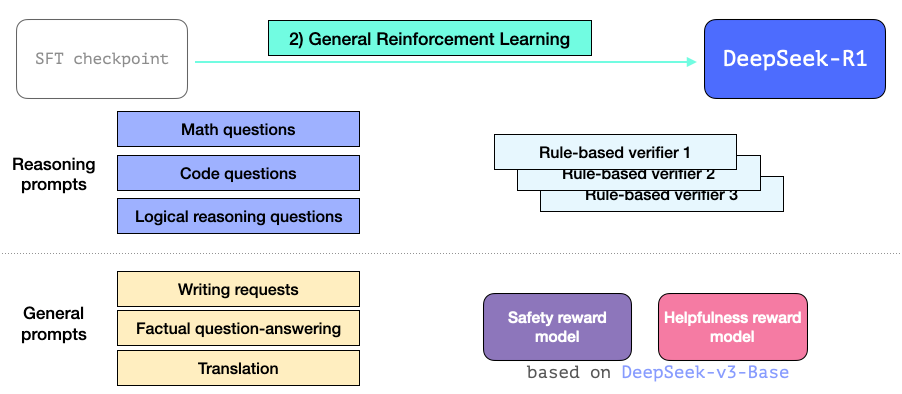
通用强化学习训练过程
最终偏好调整(Preference Tuning)如下图所示。经过通用强化学习训练后,R1 不仅在推理任务中表现卓越,在非推理任务中的表现也非常出色。由于其能力扩展到非推理类应用,因此在这些应用中引入了帮助性(helpfulness)和安全性(safety)奖励模型(类似于 Llama 模型),以优化相关提示处理能力。
 查看大图
查看大图总结 DeepSeek-R1
中间推理模型生成:通过推理导向的强化学习(Reasoning-Oriented RL),直接生成高质量推理数据(CoT 示例),减少了人工标注的依赖。 通用强化学习优化:基于帮助性和安全性奖励模型,优化了推理和非推理任务表现,构建了通用性强的模型。
最终,DeepSeek-R1 将 R1-Zero 的推理能力与通用强化学习的适应能力相结合,成为一个兼具强大推理能力和广泛任务适应性的高效 AI 模型。
核心创新总结
中间推理模型生成:通过推理导向的强化学习(Reasoning-Oriented RL),直接生成高质量的推理数据(CoT 示例),减少人工标注依赖。 通用强化学习优化:基于帮助性和安全性奖励模型,优化推理与非推理任务表现,构建通用性强的模型。 最终成果:DeepSeek-R1 将 R1-Zero 的推理能力与通用强化学习的适应能力相结合,成为一个兼具强大推理能力和广泛任务适应性的高效 AI 模型。
相关教程
相关入口
分享文章
转发到常用平台
微信/朋友圈可先复制链接
相关教程
从相近问题继续读




相关内容
相关 AI 教程
 继续学习DeepSeek-R1 提示词基础用法DeepSeek本地部署 · 第 5 篇 · 6 张图 · 2.3k 字
继续学习DeepSeek-R1 提示词基础用法DeepSeek本地部署 · 第 5 篇 · 6 张图 · 2.3k 字 图文补读DeepSeek+实在Agent,一句指令生成全自动流程DeepSeek本地部署 · 37 张图 · 3.6k 字AI 教程总索引全部 AI 教程文章大模型、Agent、本地部署、机器学习和工程实践。AI 图文教程索引流程、配置和图文节点教程中的流程图、配置图和关键截图。跨领域 AI 入口其它技术系列里的 AI 章节大数据、爬虫、量子计算和 Spark 章节。AI 教程图片索引按图查找教程文章流程图、配置图和判断卡片。DeepSeek本地部署目录DeepSeek本地部署完整目录全部小节、图文密度和文章列表。
图文补读DeepSeek+实在Agent,一句指令生成全自动流程DeepSeek本地部署 · 37 张图 · 3.6k 字AI 教程总索引全部 AI 教程文章大模型、Agent、本地部署、机器学习和工程实践。AI 图文教程索引流程、配置和图文节点教程中的流程图、配置图和关键截图。跨领域 AI 入口其它技术系列里的 AI 章节大数据、爬虫、量子计算和 Spark 章节。AI 教程图片索引按图查找教程文章流程图、配置图和判断卡片。DeepSeek本地部署目录DeepSeek本地部署完整目录全部小节、图文密度和文章列表。