24 DeepSeek接入个人知识库 自研算法框架
系列进度
DeepSeek本地部署 · 第 24 / 34 篇
 查看大图
查看大图自研算法框架最怕为了“自研”而复杂化。真正值得做的地方,是现成方案不能满足你的文档结构、权限规则或回答验收。先把问题说清楚,再决定哪些环节需要自己写。
可以先画一张数据流图:文档怎样进入系统,怎样切分,怎样召回,怎样交给模型,答案怎样评估。只要这张图能画清楚,后面代码结构就不会太散。
在过去这段时间,我们集中突破了DeepSeek+个人知识库软件的RAG精度问题,到今天为止自研的混合RAG算法基本开发完成,第一时间跟大家汇报下进度和主要的算法实现方案。
1 DeepSeek知识库软件
有些读者第一次看到,可能有些懵,简单介绍下。
在过去我们一直在开发DeepSeek+个人知识库软件,支持文件分析完全在本地,不用担心数据泄密;因为是本地自己使用,没有文件上传数量限制,文件大小等诸多限制;利用DeepSeek自身强大推理能力,使用此软件就能逐步搭建一个完全懂自己电脑文件的AI,可以说比较实用。
个人知识库接入AI大模型,主流的解决方案就是RAG(Retrieval-Augmented Generation)技术,它结合信息检索+大模型能力,实现更好的个人文档总结。
如何从个人几个G的文档中,找到和查询问题最匹配的几个文档,如何保证高效且响应快一直是个难题,如果再加一个限制条件,就是运算必须100%在个人电脑,难度就进一步加大了,因为个人电脑计算资源非常有限,很多没有GPU。
所以不难看到现在主流的大模型知识库软件,随便查询一个问题,哪怕知识库里只有十几个文件,等到响应也得分钟级,我试过多个,都是这样的情况。查询慢也就算了,还得一顿各种配置,还得安装向量数据库,对计算资源进一步加大,搞了半天最后响应又这么慢,后来就放弃了。
在过去这段时间我们一直在探索,如何解决这种安装和部署繁琐,查询又很慢的问题,到今天完整的技术框架基本成熟。
经过今天的初步测试,我电脑是m1,无GPU情况下,在保证精度的情况下,查询时间响应做到秒级,查询速度直接提升了超过20倍。
为了证明这点,从后台找了一些日志,大家看下处理过程以及前面的处理时间戳:
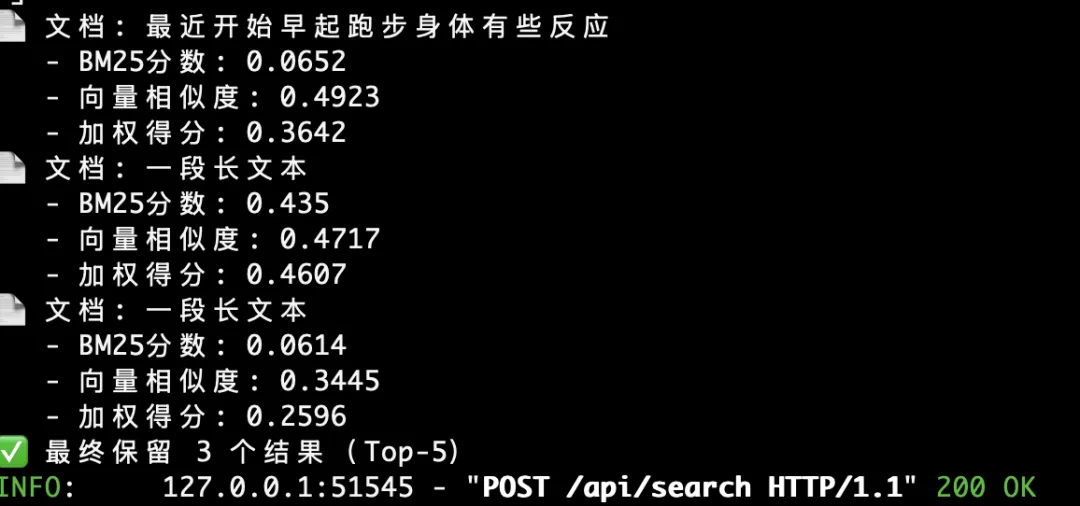 查看大图
查看大图这周我们会发布一键安装包v0.6,开箱即用,软件完全开源,不用大家花一分钱。
2 DeepSeekMine软件算法框架
开发的DeepSeek+个人知识库软件,简称为DeepSeekMine,很多读者想了解其中的算法,为了解释方便,算法名统一称为自研混合RAG算法。
下面我来详细介绍下,根据业务,算法主线有两条,文档上传处理,用户查询处理:
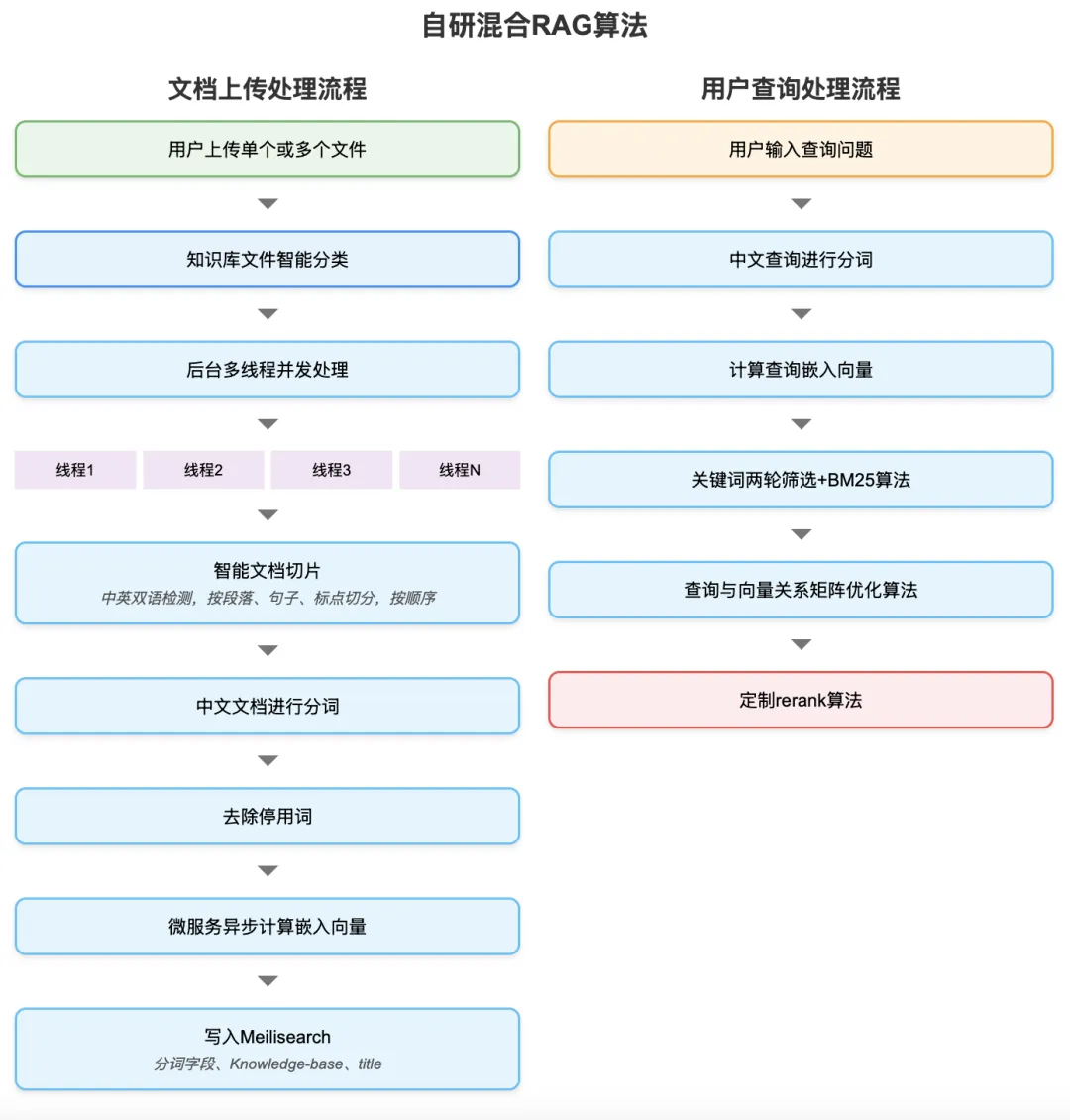 查看大图
查看大图接下来,咱们先看看文档上传处理相关的算法流程,为了更清楚,单独展示一个:
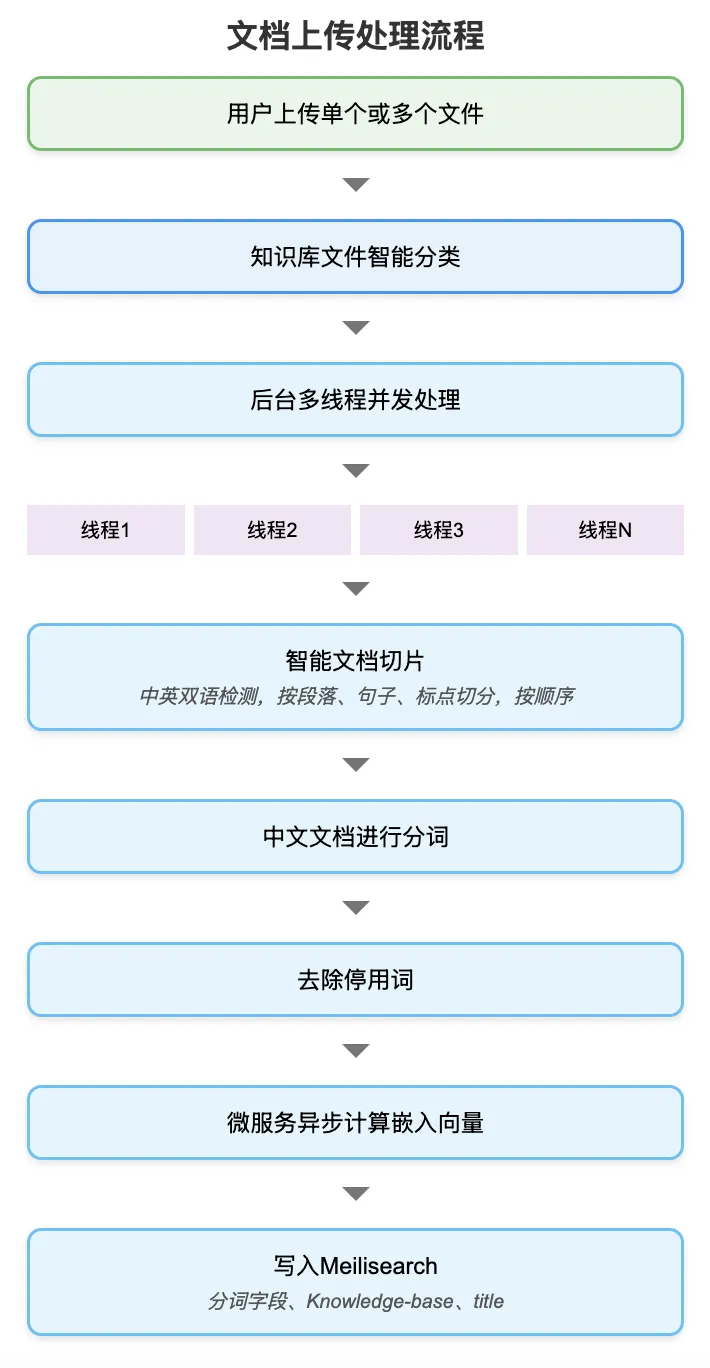 查看大图
查看大图计算机问题本质就是时间和空间复杂度的优化,DeepSeekMine软件v0.6版本支持用户一次上传多个文件,并且支持的文件格式进一步增多,如下所示:
 查看大图
查看大图上传多个文档后,接下来文档智能分类就是很重要的一个模块,提升了查询效率。为了加速文件写入效率,启用多线程并发处理多文件。然后,智能文档切片模块,负责自适应中英语言,按段落、标点等自动切分文档为片段,为接下来的语义向量计算做铺垫。
为了支持查询阶段的关键词匹配,需要先对文档chunk分词、去除停用词、异步计算嵌入向量,然后写入Meilisearch工具(一个高效的本地文件检索系统)。其中嵌入向量的计算使用了嵌入向量大模型(在这版当中我们还未加入监督微调,计划会在接下来做)。
文件和元数据等全部持久化到Meilisearch工具后,相当于数据预处理完成。接下来等待用户输入,也就是进入查询阶段,为了确保查询精准+极速响应,使用三个关键优化算法:1)关键词两轮筛选+BM25算法,2)查询与向量关系矩阵优化算法,3)定制rerank算法,如下所示:
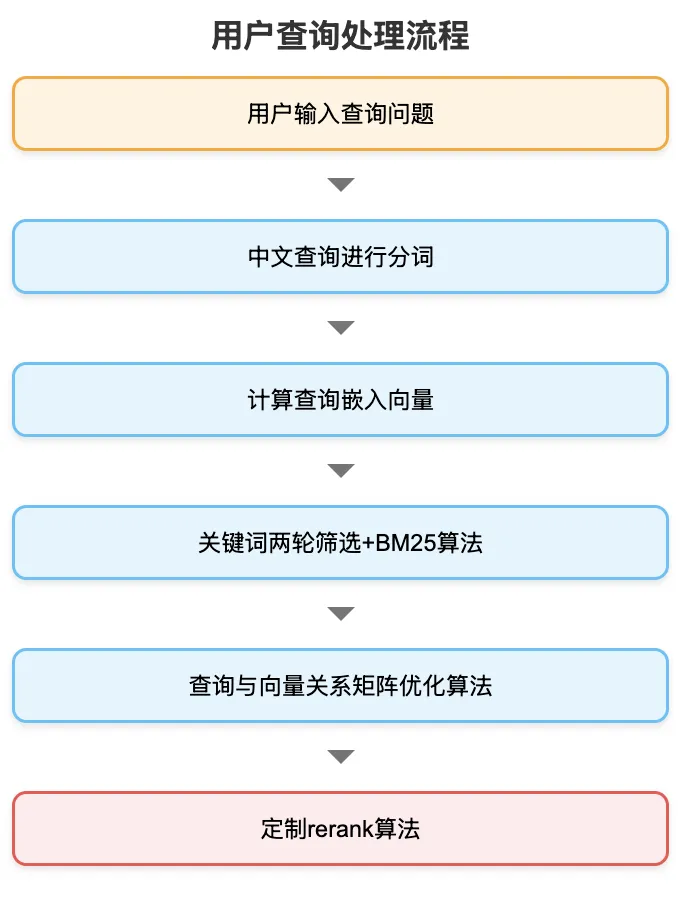 查看大图
查看大图最后输出这样的结果,实时定位出与查询最相关的语义文档片段,如下所示一共定位出3个语义片段:
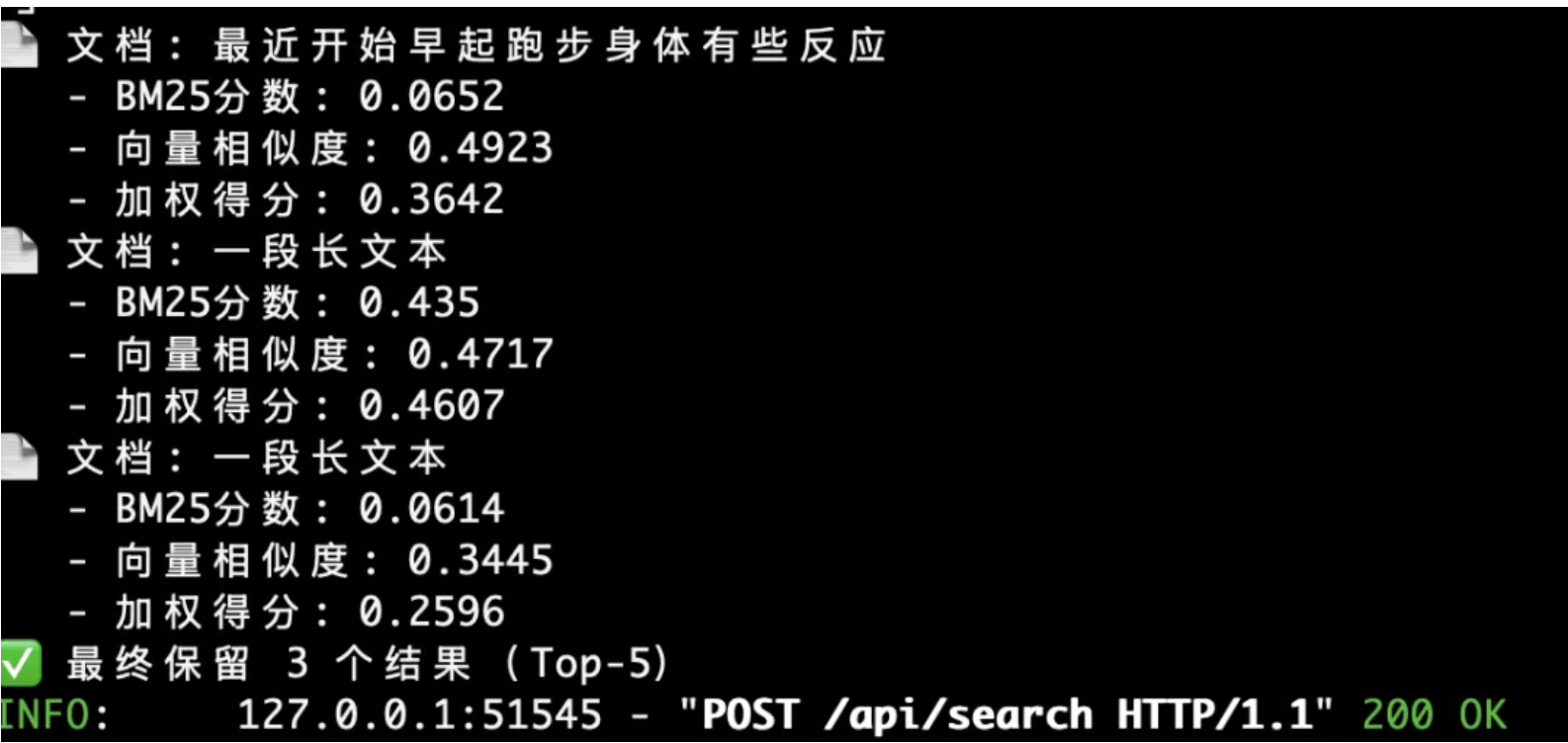 查看大图
查看大图最后就是大模型响应阶段,在注入大模型前,需要使用提示词技术,这是临门一脚,也是很重要的,整合文档片段+元数据信息,最后生成RAG回答:
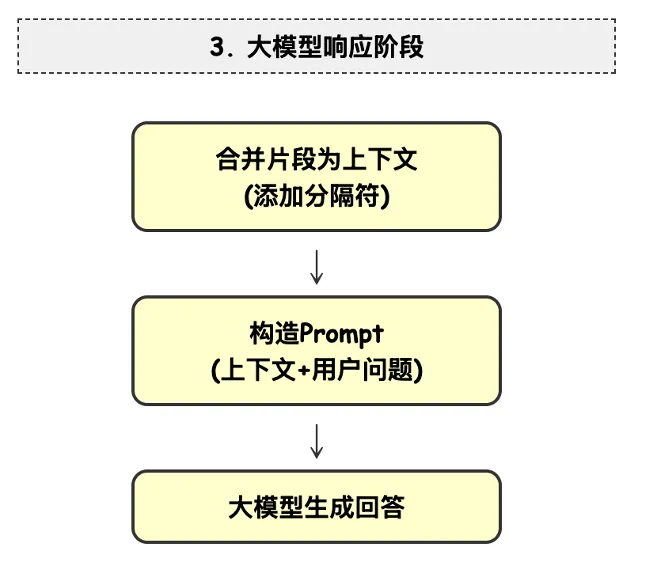 查看大图
查看大图核心提示词模版,主体结构如下所示:
 查看大图
查看大图3 DeepSeekMine软件特点
基于上面介绍的算法框架,DeepSeekMine软件主要与其他知识库软件如腾讯的ima等区别,接下来总结下。
首先,ima管理个人文档全部都在云端,DeepSeekMine全部都在本地,对文件安全无所谓的都可以使用,涉及到个人隐私文件、企业商业文件不方便上云的选择后者。
其次,ima管理知识库文件有大小限制,比如是2G;DeepSeekMine分析文件100%全都在本地,所以管理的知识库文件数量、文件大小、总体积无任何限制。
第三,DeepSeekMine如文章一开始说到的一样,是为了解决其他类似软件响应分钟级、部署复杂、配置多的难题,这周我们要发布的v0.6版本,实时秒级响应、开箱即用(无需安装任何向量数据库等)。
最后,DeepSeekMine软件全部功能免费使用,不用大家花一分钱。
以上全文2398字,8图。软件开发不易,如果觉得这个软件对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个⭐️,谢谢你看我的文章,我们下篇再见。
相关教程
相关页面
延伸教程
AI 教程列表



相关内容
相关 AI 教程
 继续学习DeepSeek接入Mureka,直接生成好听的音乐,确实可以封神了!DeepSeek本地部署 · 第 25 篇 · 10 张图 · 2.5k 字
继续学习DeepSeek接入Mureka,直接生成好听的音乐,确实可以封神了!DeepSeek本地部署 · 第 25 篇 · 10 张图 · 2.5k 字 图文补读DeepSeek+实在Agent,一句指令生成全自动流程DeepSeek本地部署 · 37 张图 · 3.6k 字AI 教程列表全部 AI 教程文章大模型、Agent、本地部署、机器学习和工程实践。图文教程流程、配置和图文节点教程中的流程图、配置图和关键截图。跨领域章节AI 章节大数据、爬虫、量子计算和 Spark 章节。教程图片按图查找教程文章流程图、配置图和判断卡片。DeepSeek本地部署目录DeepSeek本地部署完整目录全部小节、图文密度和文章列表。
图文补读DeepSeek+实在Agent,一句指令生成全自动流程DeepSeek本地部署 · 37 张图 · 3.6k 字AI 教程列表全部 AI 教程文章大模型、Agent、本地部署、机器学习和工程实践。图文教程流程、配置和图文节点教程中的流程图、配置图和关键截图。跨领域章节AI 章节大数据、爬虫、量子计算和 Spark 章节。教程图片按图查找教程文章流程图、配置图和判断卡片。DeepSeek本地部署目录DeepSeek本地部署完整目录全部小节、图文密度和文章列表。