Claude Code + LongCat-2.0,一句话就做了个完整网站,实测丝滑!
你好,我是郭震!
Claude模型虽然编程能力好用,但是API费用真的很高,于是看到在openrouter月调用量只排到第6名:
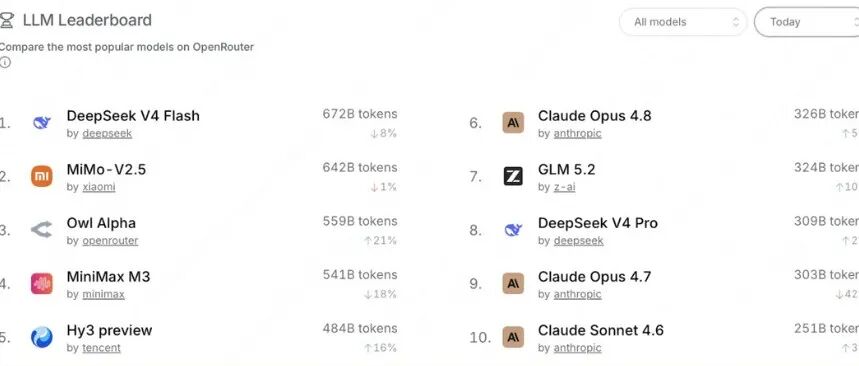
相对的DeepSeek-V4-Flash,小米MiMo-V2.5,月使用量前两名。
第三名这个模型很神秘,近两天正式发布后,才知道是美团的模型LongCat-2.0
之前已经实测过前两个,今天咱们实测下LongCat-2.0的Agent能力如何。
对一个 Agent能力强的大模型来说,会聊天不稀奇,能不能读项目、改代码、跑起来、报错后继续修,这才是真正能不能干活的关键。
测试方法接入它到Claude Code,从零开发一个完整的项目。
1 先看成果
一句话下发任务:
过了一会儿,一个本地数据看板网站跑起来,先看工作台首页:
接下来点击 上传数据:
上传一个Excel文件,系统自动读取表头和数据,并生成数据预览,如下部分截图:
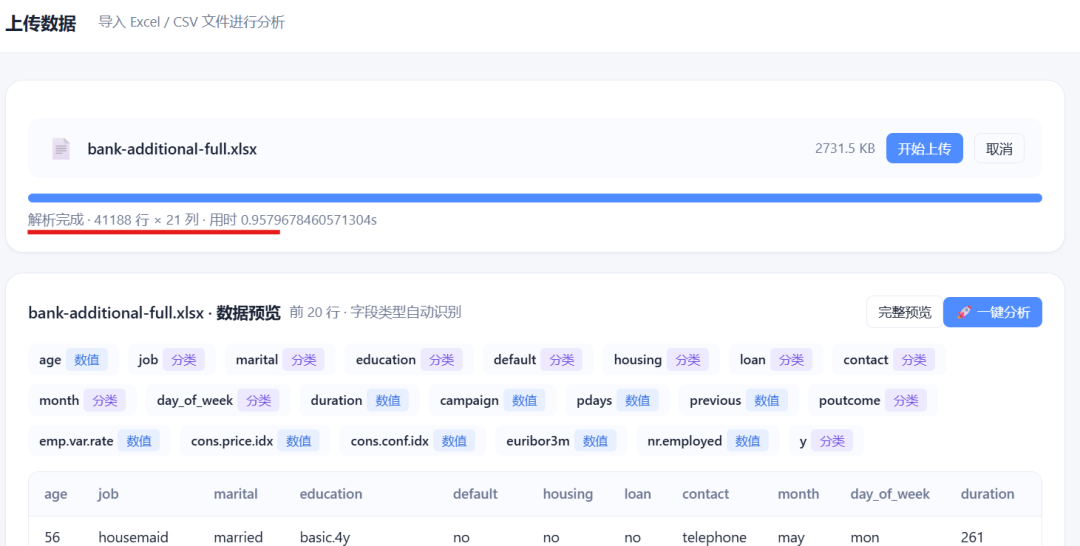
这个Excel一共4万多行,21列。表头能识别,行数据能展示,说明文件读取这条链路是通的。
再点击 一键分析(如上图所示),自动生成了核心指标卡片,如下图所示:
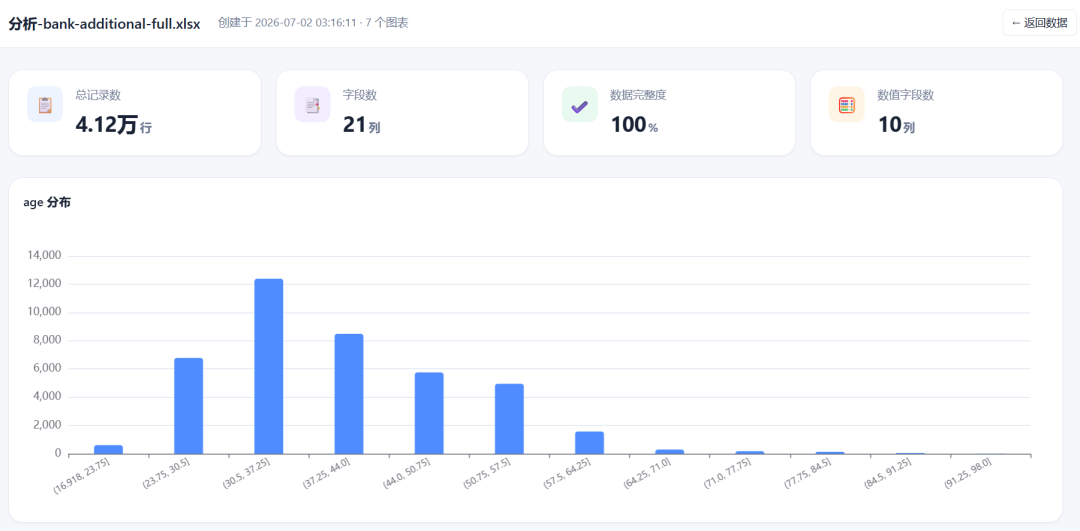
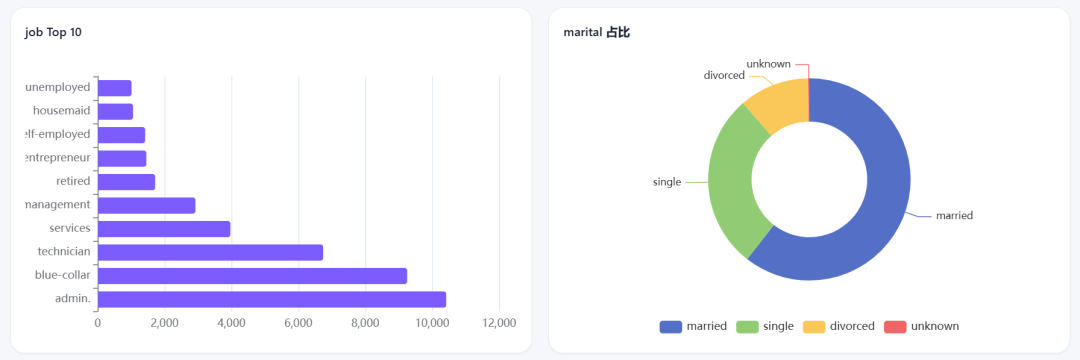
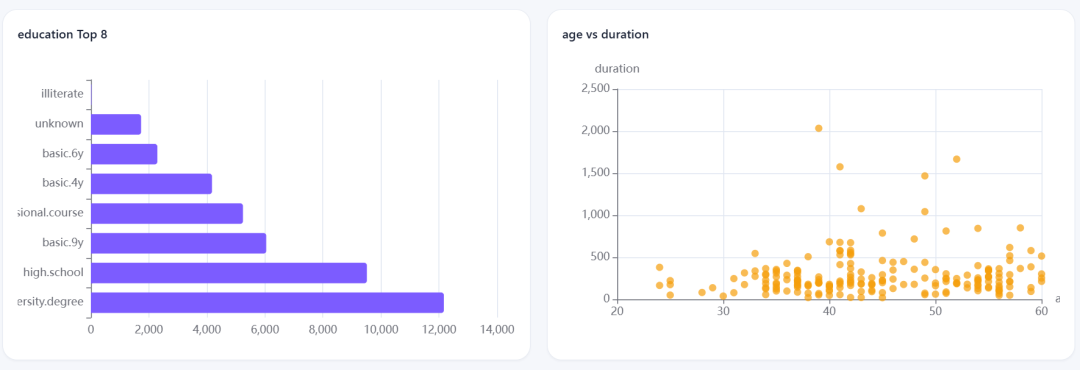
比如age、job、material等数量、关键字段统计这些,都能展示出来。
最后看历史记录。我关掉页面,再重新打开,之前上传过的数据、分析配置和历史结果还在:

这说明它不是只做了一个前端假页面,而是把 SQLite 本地存储也接上了。
这个项目里同时包含了前端,后端,数据库的完整SaaS MVP系统。
这类任务,已比较接近真实编程 Agent 的工作强度,实测更有意思。
2 LongCat-2.0
开发以上项目,使用的是 LongCat-2.0
大概看了下资料,它是一个总参数量 1.6 万亿、每个 token 激活约 480 亿参数的 MoE 模型。如下图是它的稀疏注意力设计概览图:
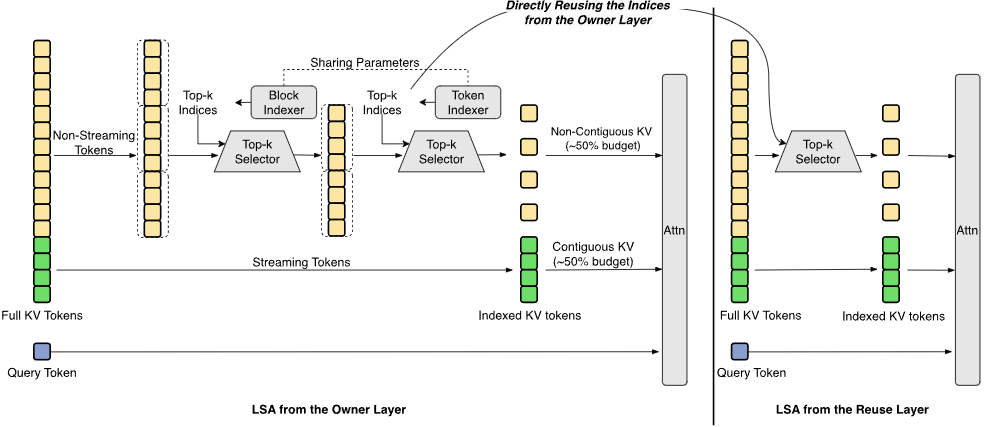
当模型面对更长上下文、更复杂任务、更连续的工具调用时,怎么在成本和效果之间取得平衡。
而 Agent 场景,恰好最吃这几件事。
因为它不是问一句答一句,而是要读需求、看文件、改代码、跑命令、看报错,再继续修。
资料显示, LongCat-2.0是Agent 原生、代码能力强,已经适配 Claude Code、OpenClaw、Hermes 这些主流编程工具。
更关键的是,它的完整训练流程和大规模部署都基于国产算力集群完成。
预训练用了 5 万余国产算力芯片,消耗超过 35 万亿 tokens。
但我还是那句话:模型再大,最后都要落到能不能干活。
很多模型在榜单上看着不错,但一进真实项目目录,就开始迷路。
下面介绍完整实操步骤,感兴趣的根据我的步骤一步一步来。
3 完整实操
先把 LongCat-2.0 接进 Claude Code。
如下图所示,目前配置的是 deepseek-v4-pro:
我先在 LongCat 平台里创建 API Key:
https://longcat.chat/platform/api_keys
然后在 Claude Code 里配置好Base URL、API Key ,以及LongCat-2.0支持的最大上下文1M等:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的_LongCat_API_Key",
"ANTHROPIC_BASE_URL": "https://api.longcat.chat/anthropic",
"ANTHROPIC_MODEL": "LongCat-2.0",
"ANTHROPIC_SMALL_FAST_MODEL": "LongCat-2.0",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "LongCat-2.0",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "LongCat-2.0",
"CLAUDE_CODE_MAX_OUTPUT_TOKENS": "131072",
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "1000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1"
},
"permissions": {
"allow": [],
"deny": []
}
}
按照以上配置完成后,Claude Code 显示可以直接调用 LongCat-2.0了:
接好以后,我新建了一个空项目目录:
然后直接把这次需求丢进去:
请从零开发一个 BI 数据看板网站,要求 100% 本地运行。用户可以上传 Excel 数据,系统自动识别字段并生成数据预览、核心指标卡片和可视化分析结果;使用 SQLite 保存用户上传记录、分析配置和历史结果;使用 ECharts 展示图表;页面要像专业 SaaS 工具,包含清晰的工作台、上传入口、数据预览、图表分析和历史记录页面。不需要接第三方登录。
这次测试里,我重点观察三件事:它会不会先拆任务;它能不能持续修改项目文件;它遇到报错后,会不会根据终端反馈继续修。
先拆任务:
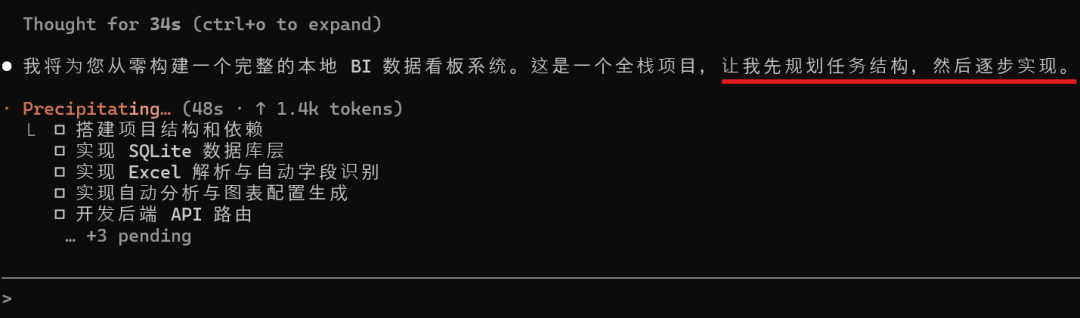
再搭项目结构:
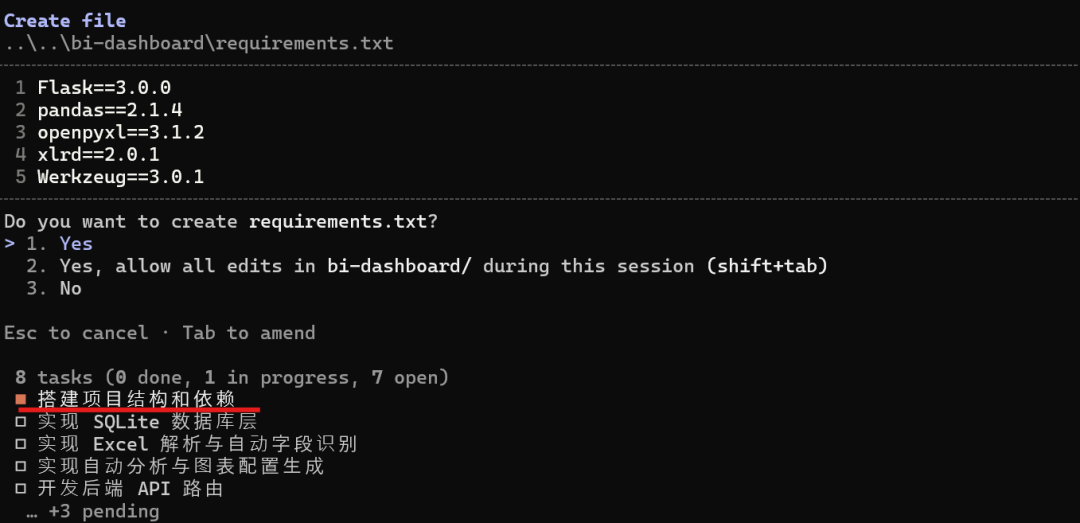
再处理 Excel 上传和解析:
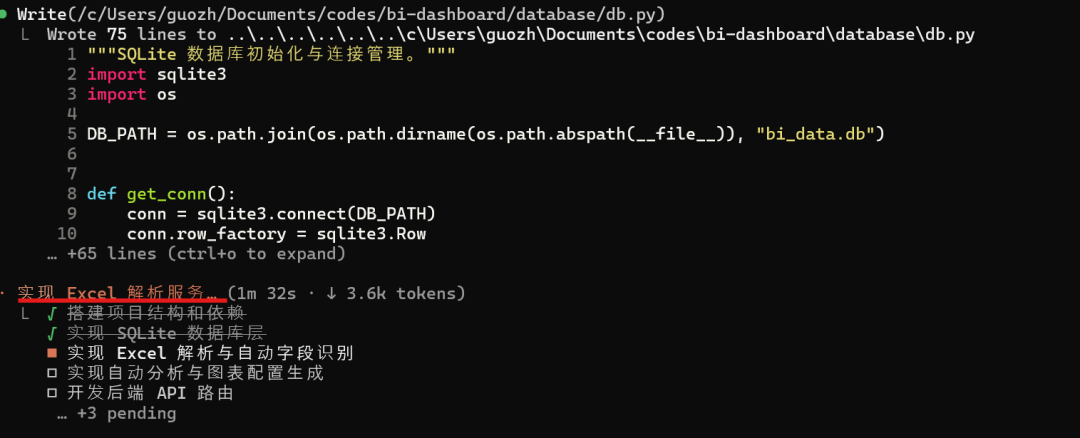
接着实现后端API路由,它接着修改了自动分析引擎文件代码:
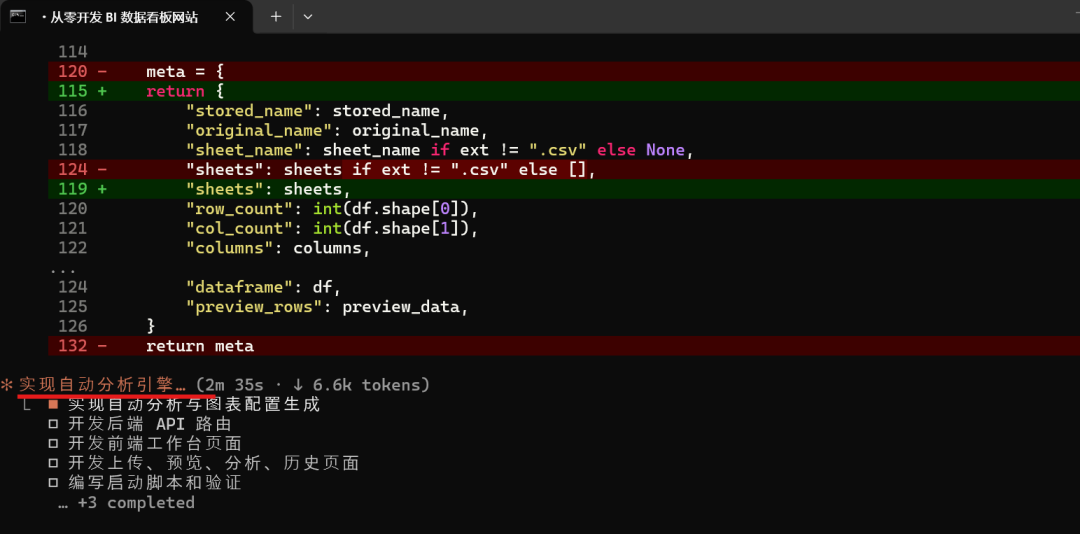
接着开发前端页面:
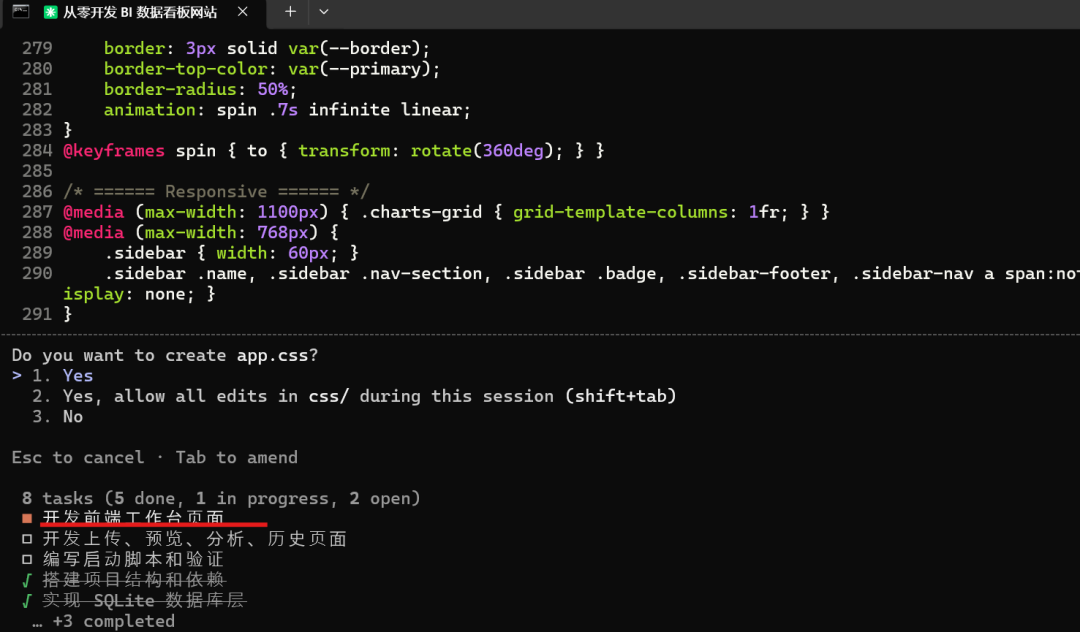
然后 启动脚本都给整好了:
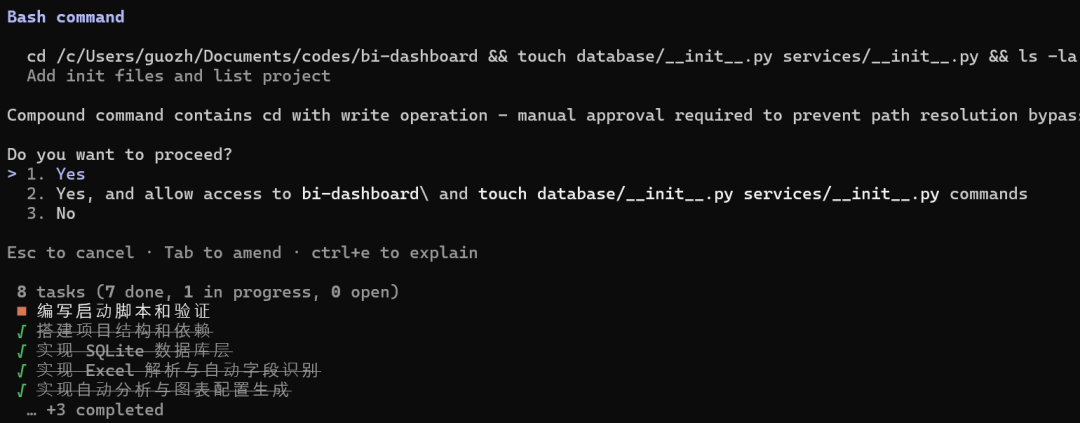
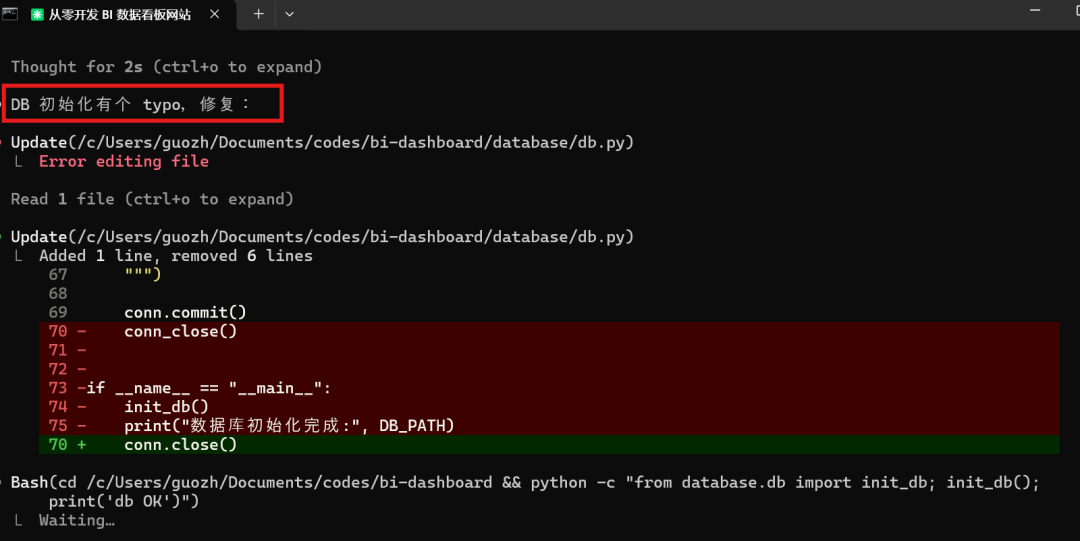
最后帮我测试代码,发现是db数据库conn_close未定义的错误:
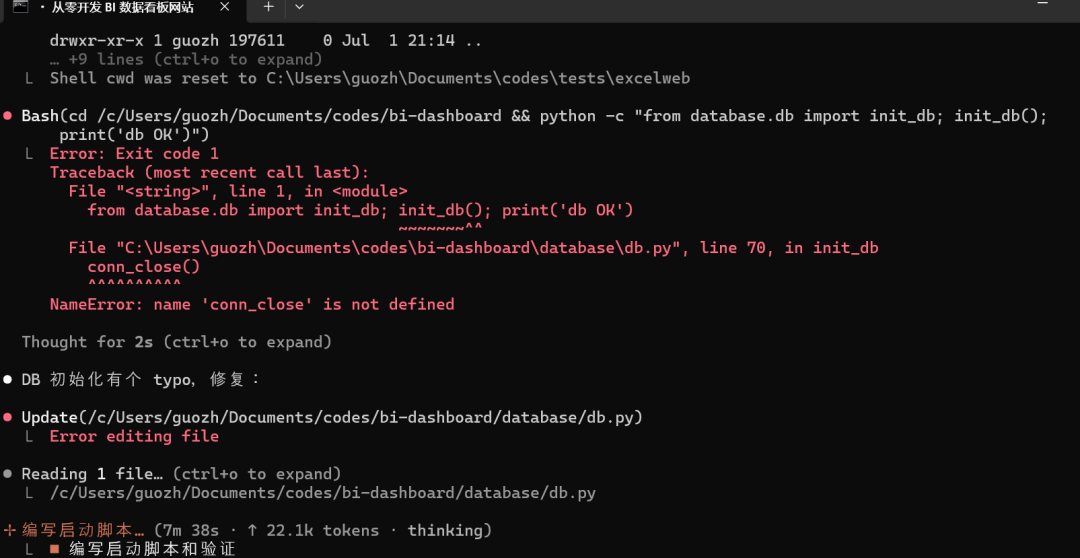
它自动修复这个错误:
小白最怕的就是安装环境依赖,它都能帮我们安装好了。
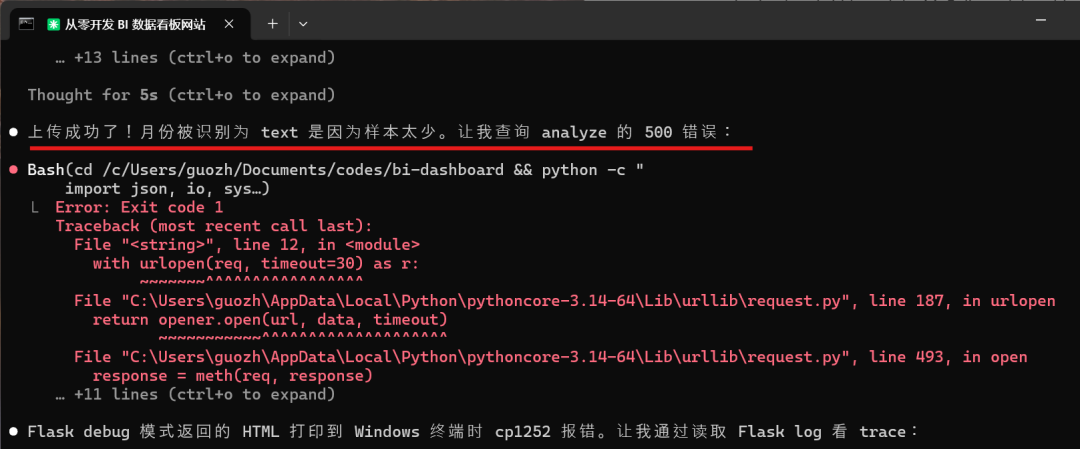
同时还会一边验证功能,一边修复bug:
全程10多分钟,到现在所有页面和API都正常响应,如下所示:
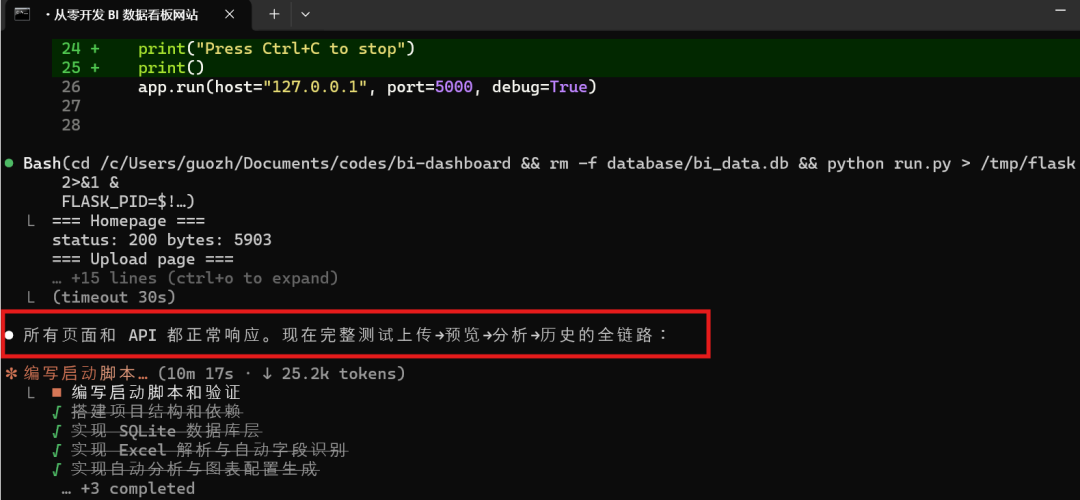
这个过程比较像一个程序员在连续干活。
先把骨架搭起来。
再把功能一个个补进去。
哪里跑不通,再回头修哪里。
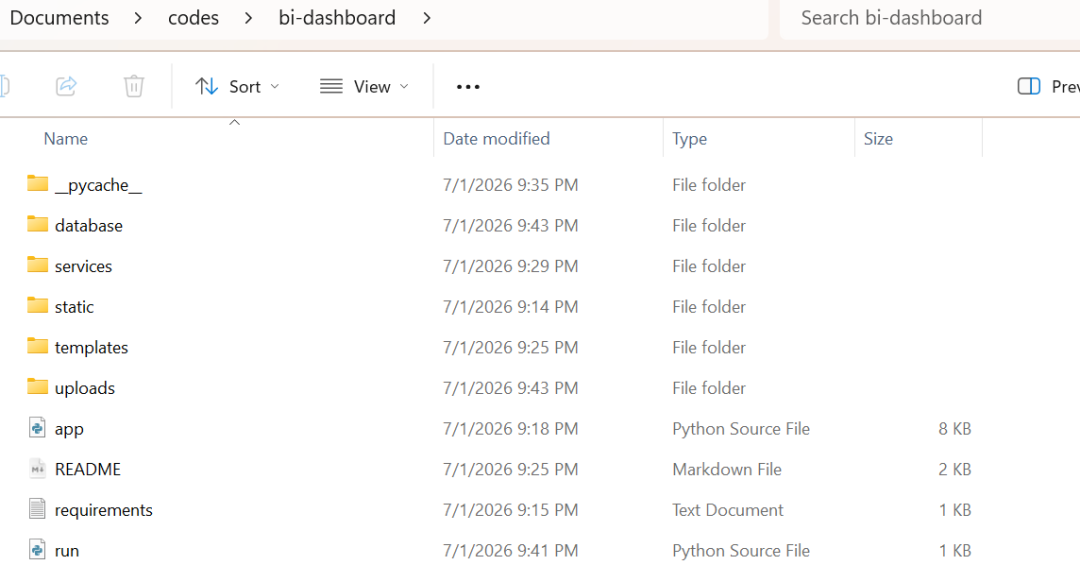
如下图所示,Claude Code 生成项目结构的截图:
如下图所示,建议插入终端报错和修复后的运行成功截图:
浏览器输入127.0.0.1:5000,具体网站使用,文中第一节已有介绍,不再赘述。
除了跑通,顺手看了下它大概消耗总token 15万:

同样任务在Codex+GPT-5.5下消耗token大约为22万:
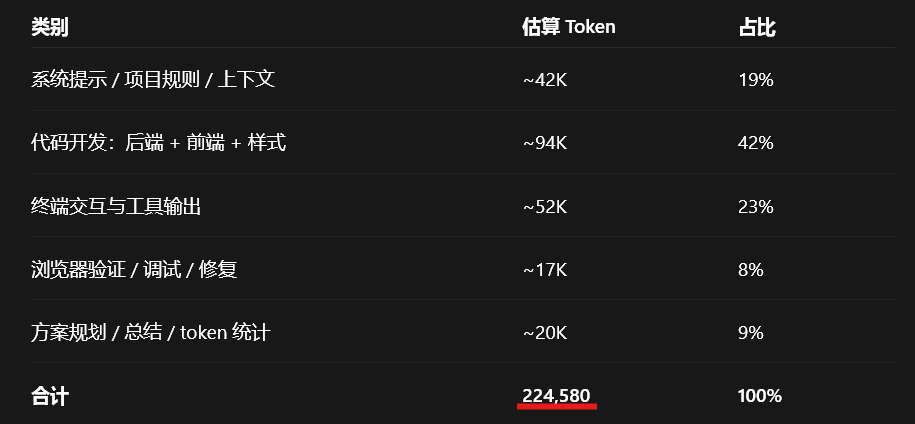
也就是说,在完成同类任务的情况下,LongCat-2.0 的 token 消耗少了大约三分之一。
LongCat-2.0 cache 命中不计费。简单理解就是:很多已经读过、重复出现的上下文,后续如果命中缓存,就不会继续按普通 token 那样消耗,这点比较好。
最后总结一下
整体跑下来,我觉得Claude Code + LongCat-2.0组合的优势不是“某一段代码写得多漂亮”。
而是能把一个项目往前推。
从需求到页面,从页面到数据,从数据到图表,从图表到历史记录,它能把这几块串起来。
这说明 LongCat-2.0 接入 Claude Code 以后,不只是能写代码片段,而是有一定项目级开发能力。
中间也不是一次就完美。
真正能干活的编程 Agent,它自己也不能一次性生成惊艳的结果。
它必须自己能持续迭代,这就是最近比较火的 loop engineering
哪个环节不满意,就单独改哪个。哪里报错,就继续修哪里。
整体下来,我的结论:Claude Code + LongCat-2.0,开发这个完整前后端网站,还是比较丝滑的。感兴趣的大家可以试试。
常见问题
Claude Code + LongCat-2.0,一句…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
Claude Code + LongCat-2.0,一句…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
Claude Code + LongCat-2.0,一句…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容