实测 DeepSeek-V4 接入 Hermes:一句话爬取几十个网页,真的丝滑!
你好,我是郭震。
这段时间我一直在用 OpenClaw 龙虾做本地电脑上的智能体实验。体感还不错,哪怕接入 Qwen3.5:9B 这种本地小模型,也能做到 Token 自由,回复速度和操作体验都比较顺。
比如让它生成一个 HTML 风格的文件结构树,效果如下:
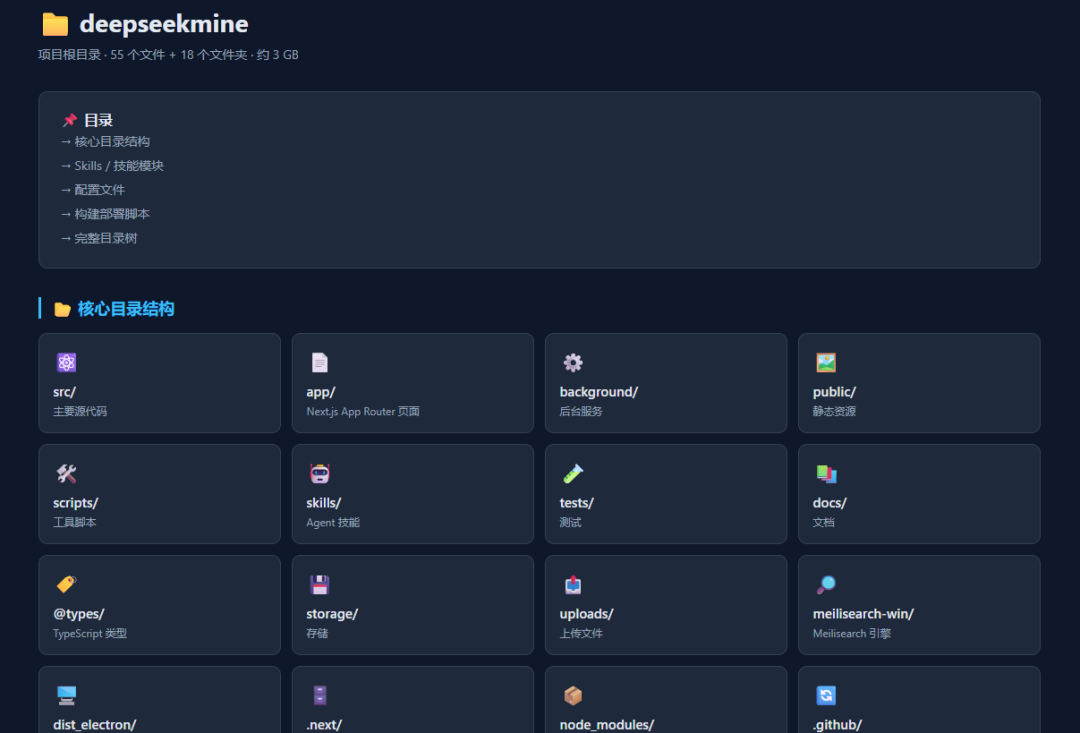
再比如让它把数据整理成一个 HTML 数据分析看板,也能比较快地跑出来:
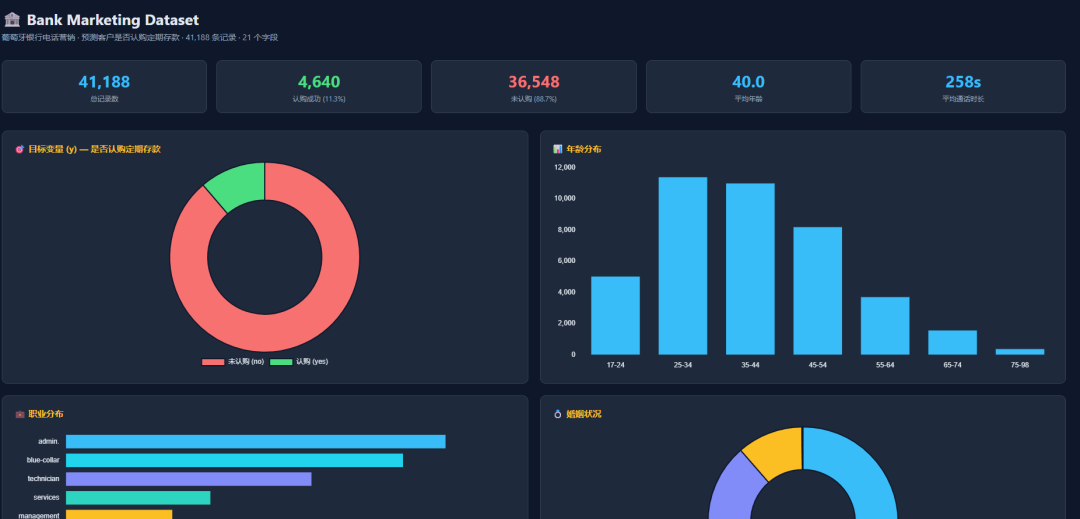
这篇文章重点记录我最近实测 Hermes 的过程:Windows 电脑如何安装 Hermes,如何接入 DeepSeek-V4,以及它能不能真的一句话抓取多个网页并保存成 Markdown 文件。
1 先看 Hermes 是什么
最近智能体工具更新很快,OpenClaw、Hermes、OpenHuman 这几个名字很容易混在一起。我先把它们的定位放在一起看:
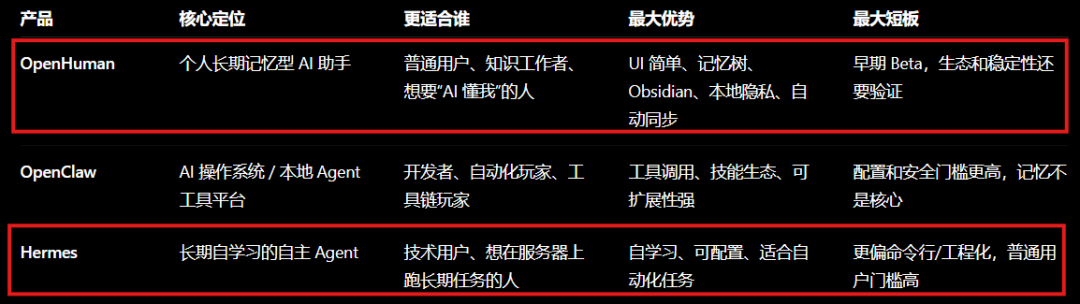
我的理解是,Hermes 更像一个可以长期积累经验的智能体。它不只是执行一次命令,而是希望把任务过程里的知识、偏好和操作经验慢慢沉淀下来。
这点很适合个人电脑上的自动化场景:整理资料、抓取网页、生成文件、保存结果。只要流程能跑通,后面就可以反复复用。
2 Windows 安装 Hermes
Mac 上安装 Hermes 相对简单,通常一行命令就能搞定。Windows 用户稍微麻烦一点,需要先准备 WSL2,也就是 Windows 里的 Ubuntu 子系统。
第一步:安装 WSL2
用管理员身份打开 PowerShell,然后运行:
wsl --install
系统会开始下载并安装 Ubuntu:
安装过程比较快,完成后可以进入 Ubuntu 子系统:
进入 Ubuntu 后,先更新一下软件源:
sudo apt update
然后安装基础工具:
sudo apt install -y curl git build-essential
开始安装后,终端会显示类似下面的输出:
第二步:安装 Hermes
在 Ubuntu 终端里运行:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
运行后会开始拉取并安装 Hermes:
安装完成后,会出现下面这个界面:
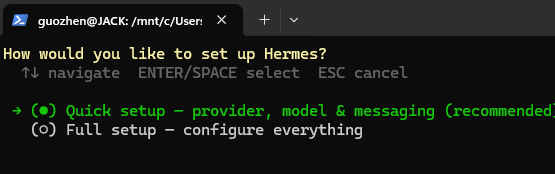
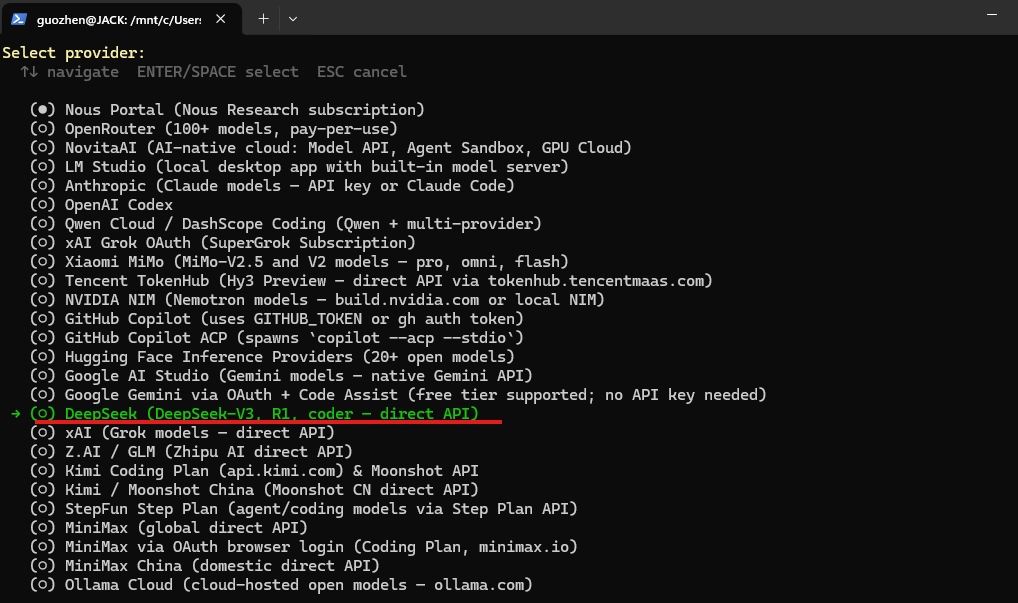
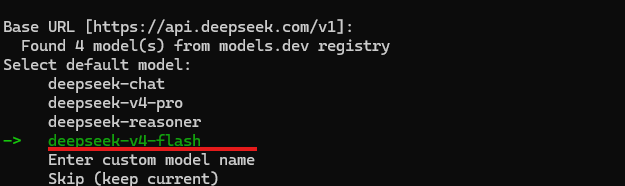
按下回车后,开始配置大模型 API。这里我接入的是性价比较高的 DeepSeek-V4 Flash:
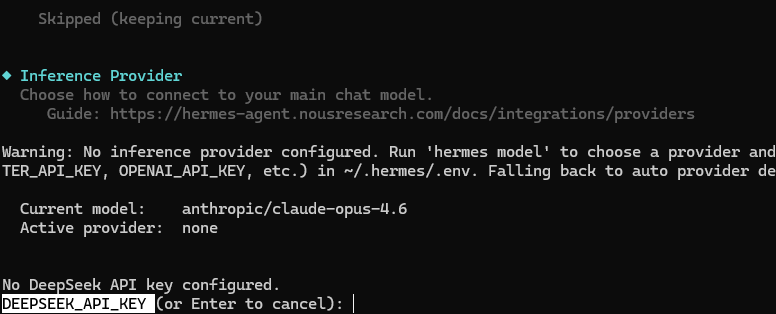
继续回车,填入 API Key。这个 Key 可以从 DeepSeek 官网生成后复制过来,注意不要公开暴露:
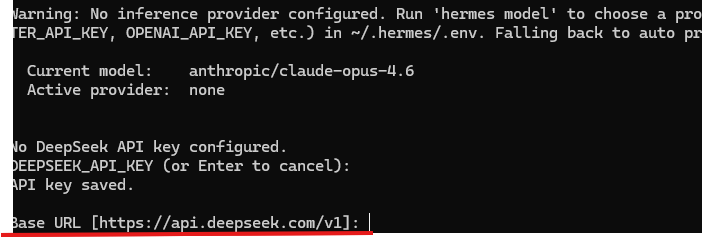
Base URL 默认即可,直接回车:
模型选择 Flash:
看到下面这个界面,就说明 Hermes 已经安装并配置成功:
3 实测:一句话抓取多个网页
Windows 进入 Ubuntu 子系统后,输入 hermes 启动:
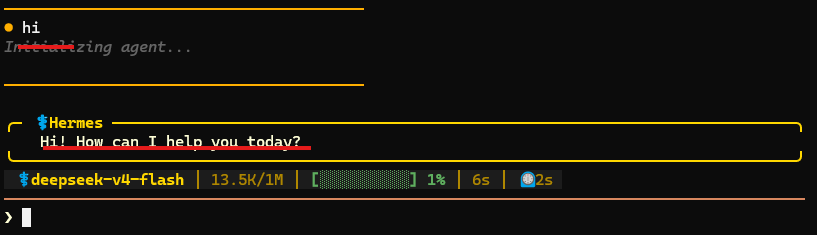
输入 hi,如果能得到正常回复,就说明 Key 和 Base URL 配置没问题。如果回复异常,可以输入 hermes setup 重新检查配置。
接下来做一个更真实的任务。我以自己的网站 zglg.work 为例,目标页面是:
这个页面里有很多文章链接:
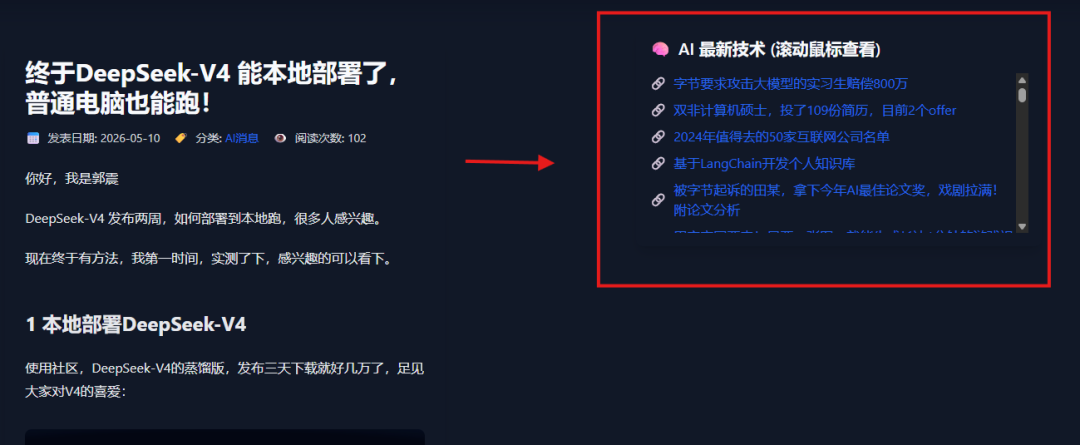
我让 Hermes 先帮我抓取前 20 篇文章的标题和链接:

很快,这 20 篇文章的标题和链接就被整理出来了:
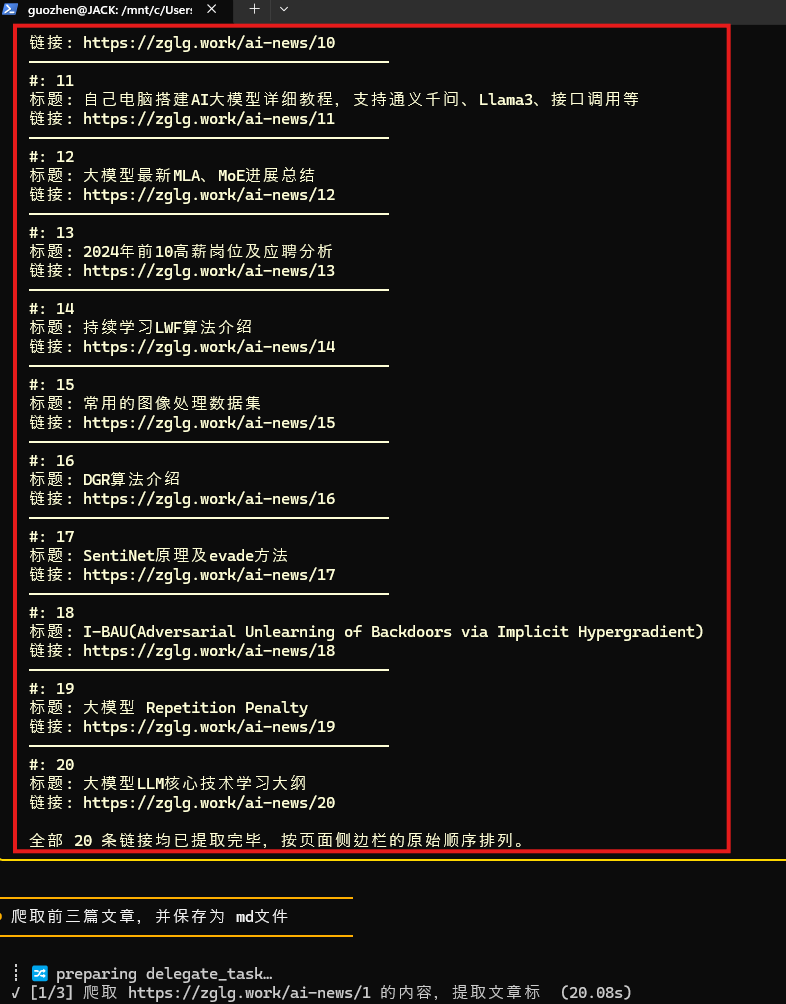
为了节省篇幅,我继续让它只抓取前三篇文章,并保存为 Markdown 文件:
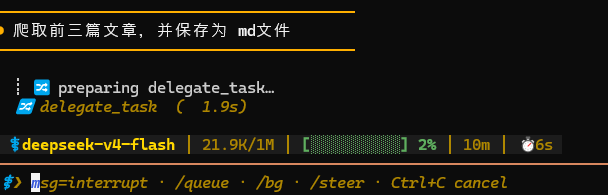
实测下来,48 秒左右,前三篇文章全部抓取完成:
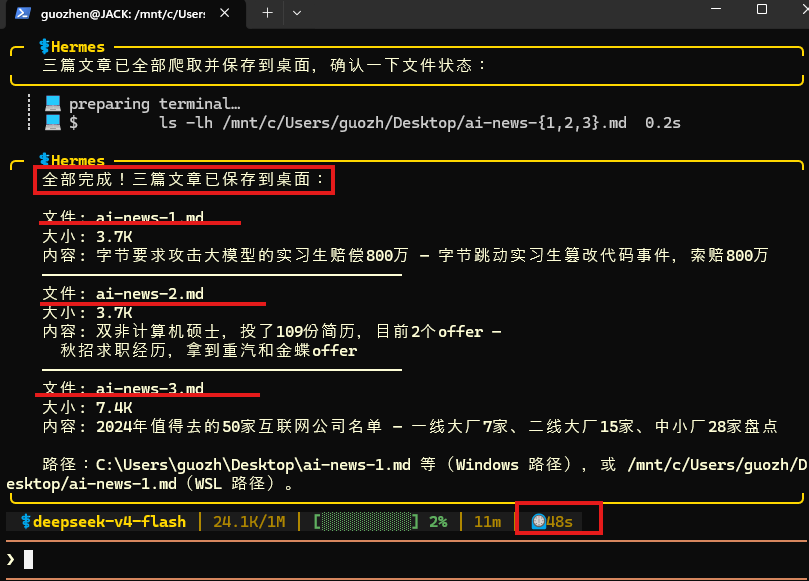
保存路径也写得很清楚:
打开文件检查,图文内容也都保存下来了:

这个结果基本达到了我的预期:不用自己写爬虫,也不用来回复制网页链接,只用自然语言描述任务,Hermes 就能读取网页、整理资料、保存文件。
4 最后总结
这次实测下来,Hermes 给我的感觉是:轻量、顺手,适合做资料收集和本地自动化。
如果你的需求是让 AI 帮你批量读网页、整理链接、生成 Markdown、保存到本地,那么 Hermes 这类智能体工具已经有比较实用的价值。
当然,它还不是万能的。遇到复杂网站、登录页面、反爬机制、动态加载内容时,仍然需要人工检查结果。但对个人日常资料整理来说,它已经能明显减少重复劳动。
常见问题
实测 DeepSeek-V4 接入 Hermes:一句话…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
实测 DeepSeek-V4 接入 Hermes:一句话…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
实测 DeepSeek-V4 接入 Hermes:一句话…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容