实测最新 Gemini-3.5,对比 DeepSeek-V4、GPT-5.5,结果出人意料!
你好,我是郭震
历经近半年,Gemini 从 3 升级到了 3.5,
并且这次只发布 了 3.5 Flash,号称已超越自家 3.1 Pro,
今天对比实测下,感兴趣可以看看。
1 Gemini 3.5 Flash
先看Card报告评分:
在 Coding 上,它的 Terminal-bench 2.1 达到 76.2%,已经接近 GPT-5.5 的 78.2%,明显超过 Gemini 3 Flash 和 Gemini 3.1 Pro。
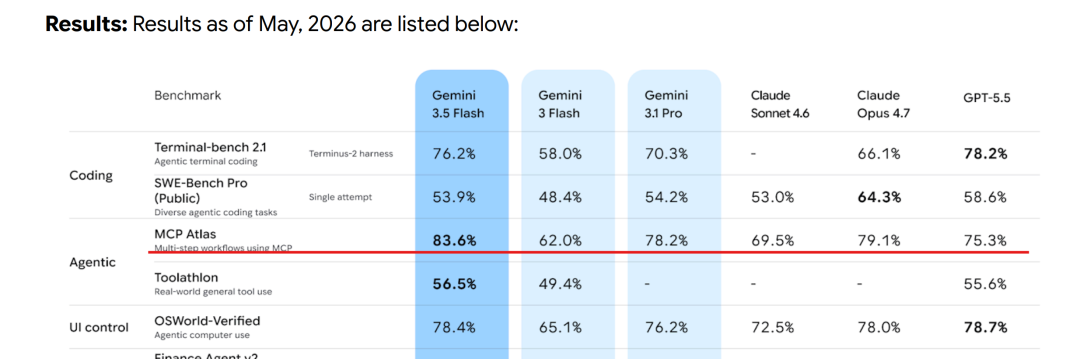
更关键的是 Agent 能力。
MCP Atlas 直接冲到 83.6%,比 GPT-5.5、Claude Opus 4.7 都高;
Toolathlon 也有 56.5%,说明它在 MCP、多工具调用、真实任务流里表现很强。
UI 操作也不弱,OSWorld-Verified 是 78.4%,几乎贴着 GPT-5.5 的 78.7%。
以上评分看到,Gemini 3.5 Flash 已成为在 Agent、MCP、真实工具使用场景里非常能打的主力模型。
2 对比实测
测试思路:确定测试环境,确定对比测试使用的大模型,把各自结果发给裁判Gemini-3.1-Pro
测试环境配置如下:
我构思了一个小型Agent任务,如下所示:
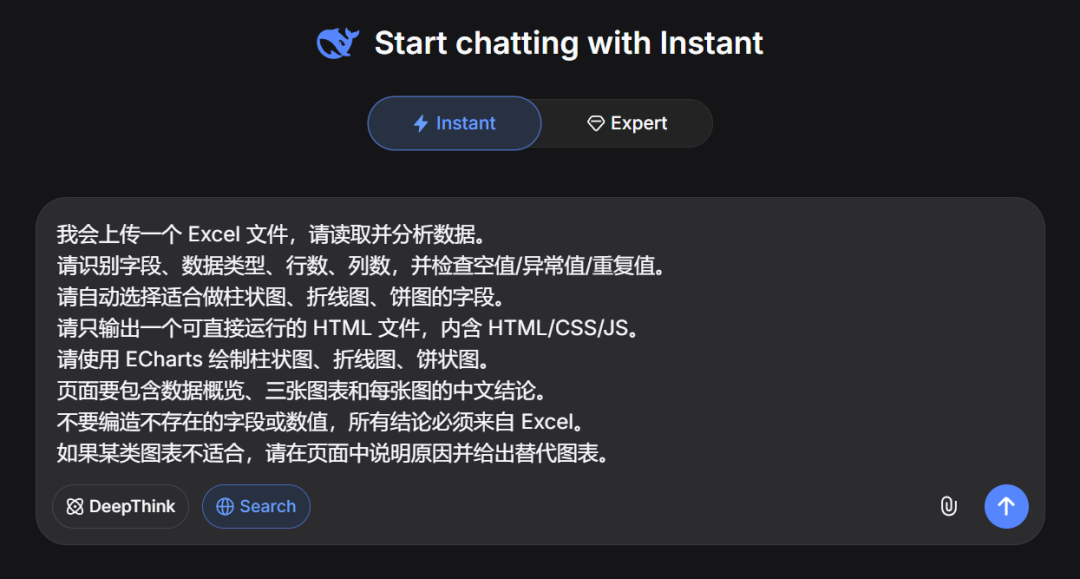
我会上传一个 Excel 文件,请读取并分析数据。
请识别字段、数据类型、行数、列数,并检查空值/异常值/重复值。
请自动选择适合做柱状图、折线图、饼图的字段。
请只输出一个可直接运行的 HTML 文件,内含 HTML/CSS/JS。
请使用 ECharts 绘制柱状图、折线图、饼状图。
页面要包含数据概览、三张图表和每张图的中文结论。
不要编造不存在的字段或数值,所有结论必须来自 Excel。
如果某类图表不适合,请在页面中说明原因并给出替代图表。
分别使用大模型:Gemini-3.5-Flash,DeepSeek-V4-Flash,DeepSeek-V4-Pro,GPT-5.5
选择Gemini-3.5-Flash:
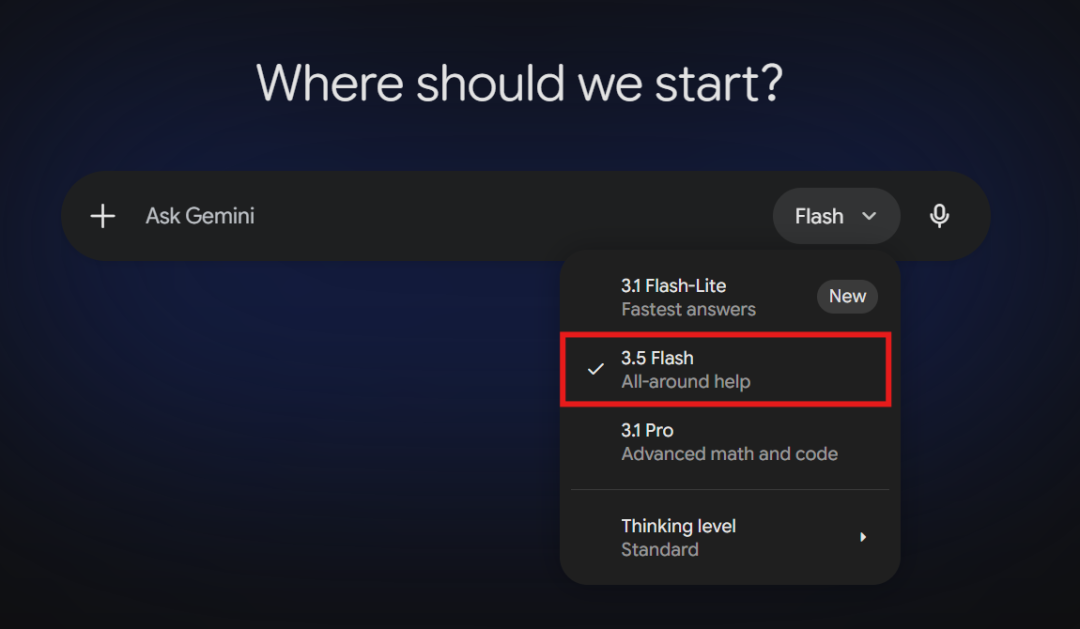
发送这个小型Agent任务给它:

保存生成的HTML文件:
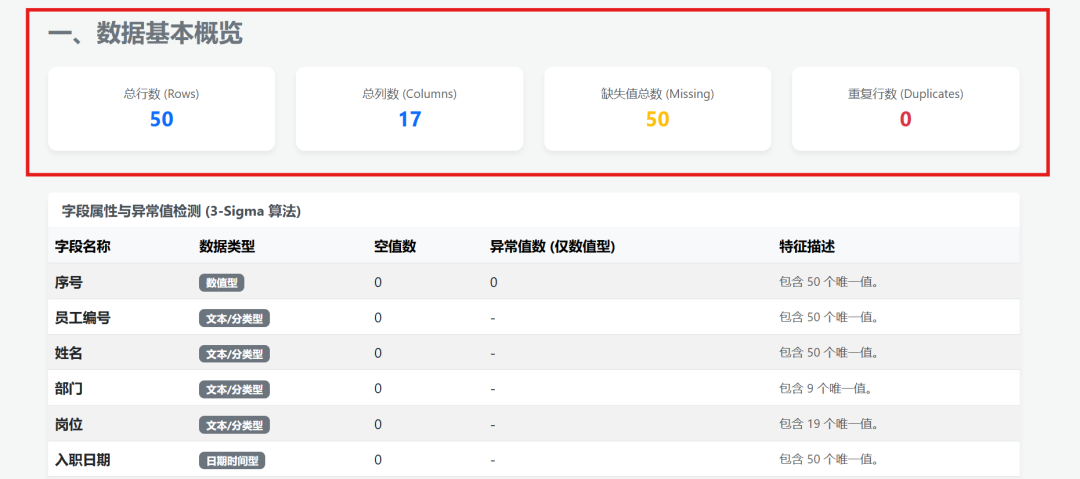
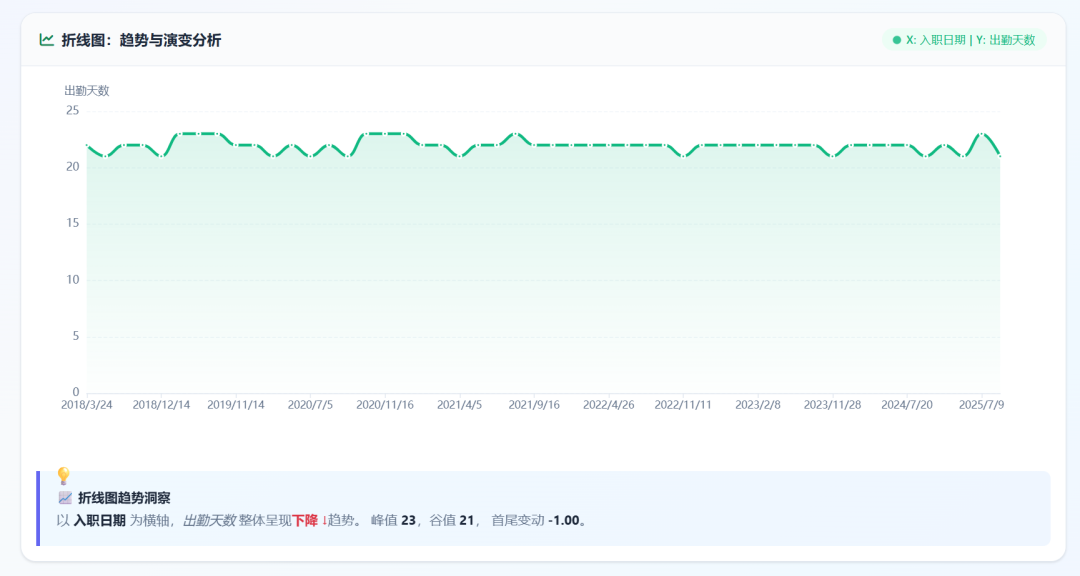
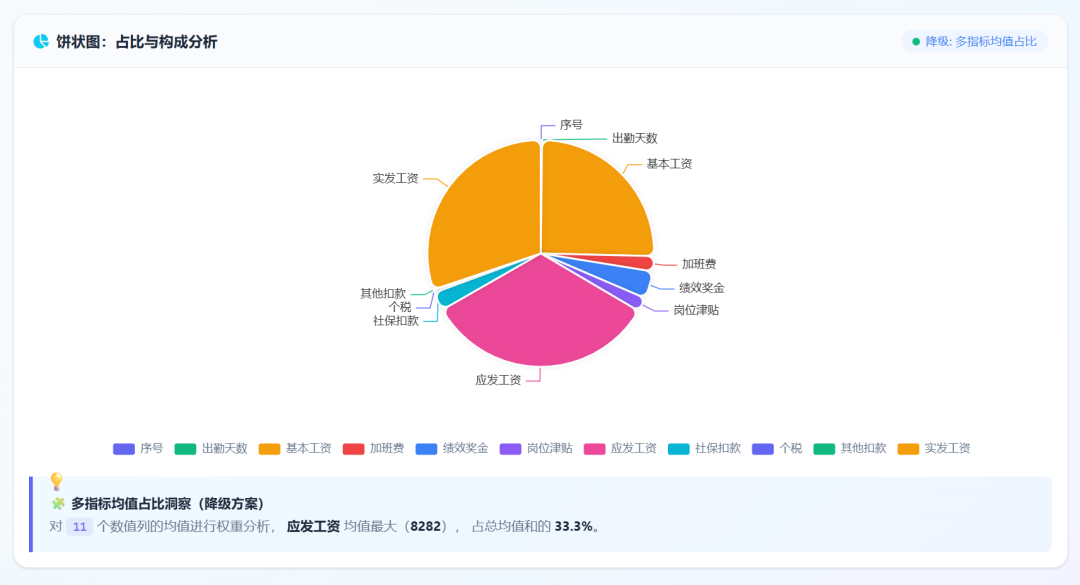
Gemini-3.5-Flash 结果展示:
上传一个Excel文件后数据展示:
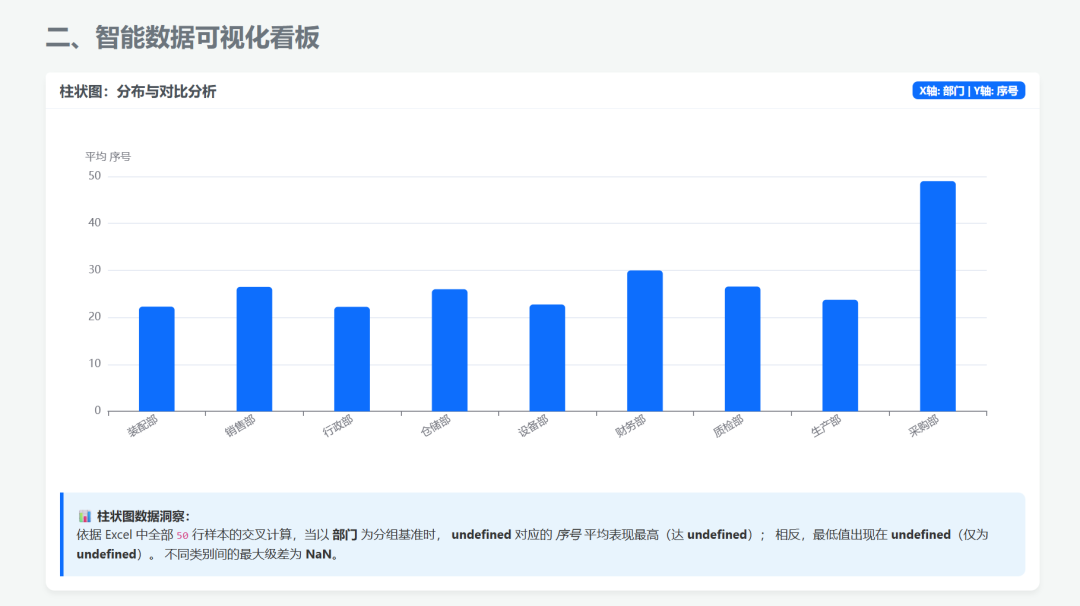
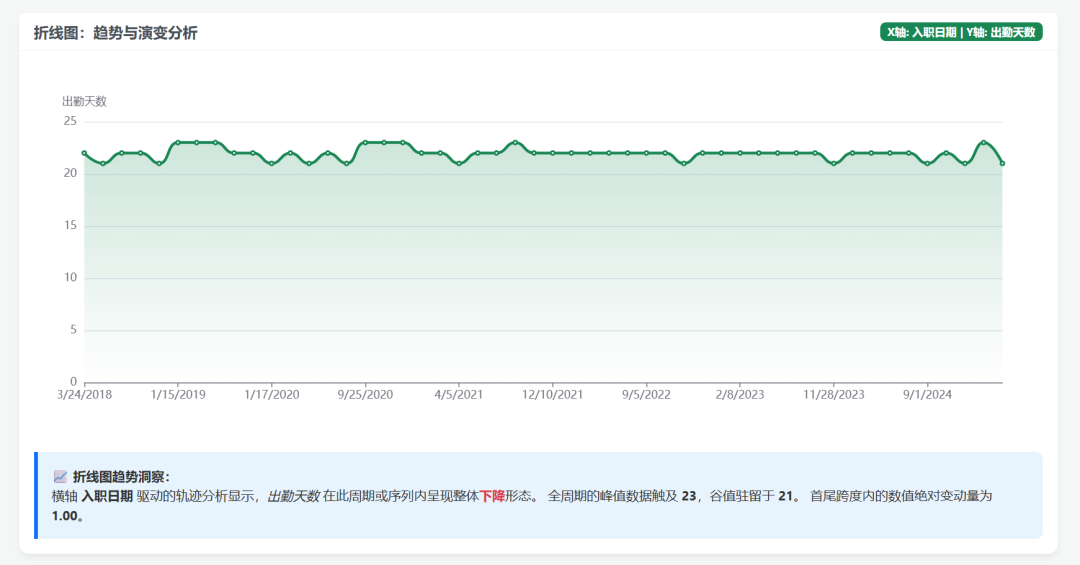
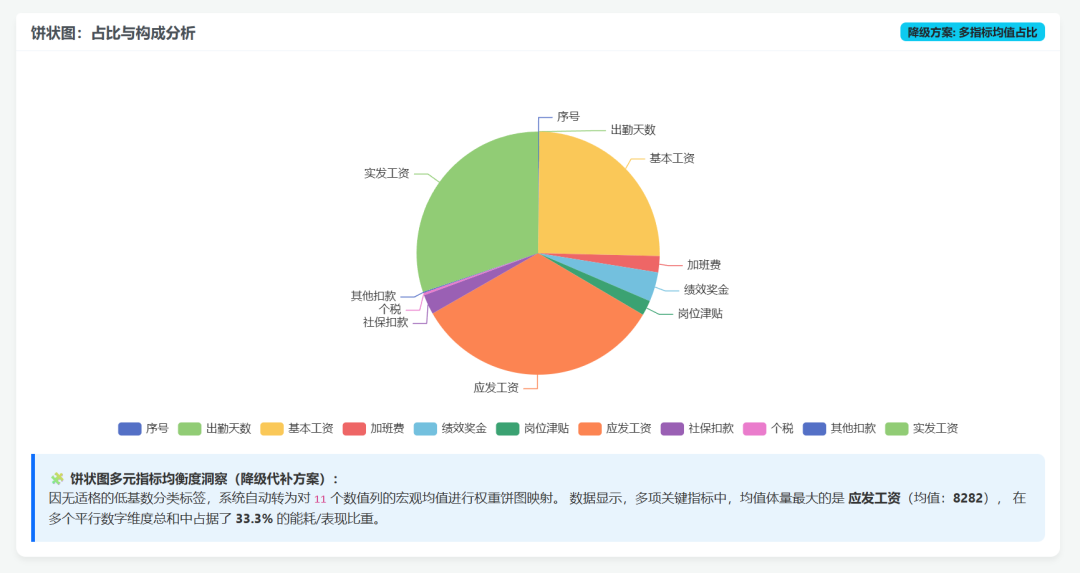
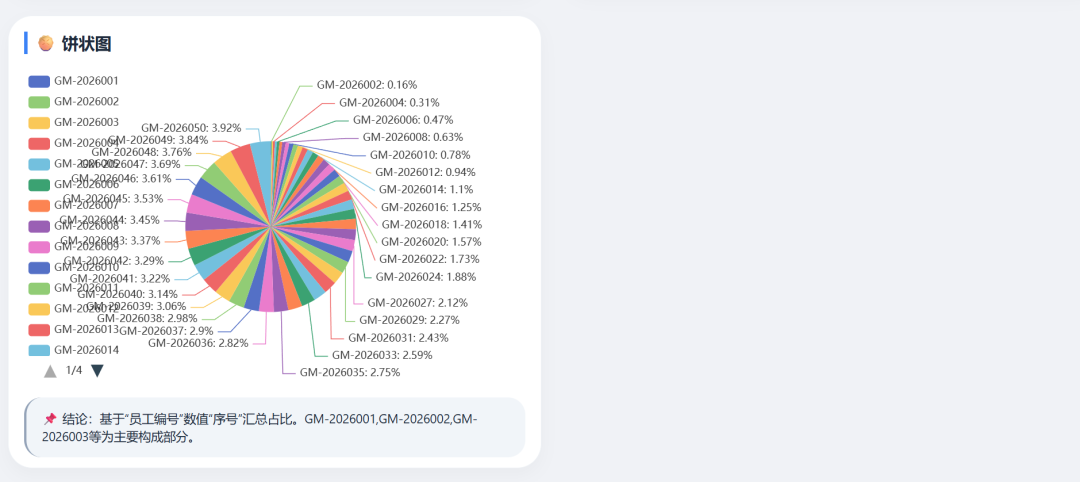
可视化图展示:
同样小型Agent任务,提问:DeepSeek-V4 Flash
同样Excel上传DeepSeek-V4 Flash后展示:
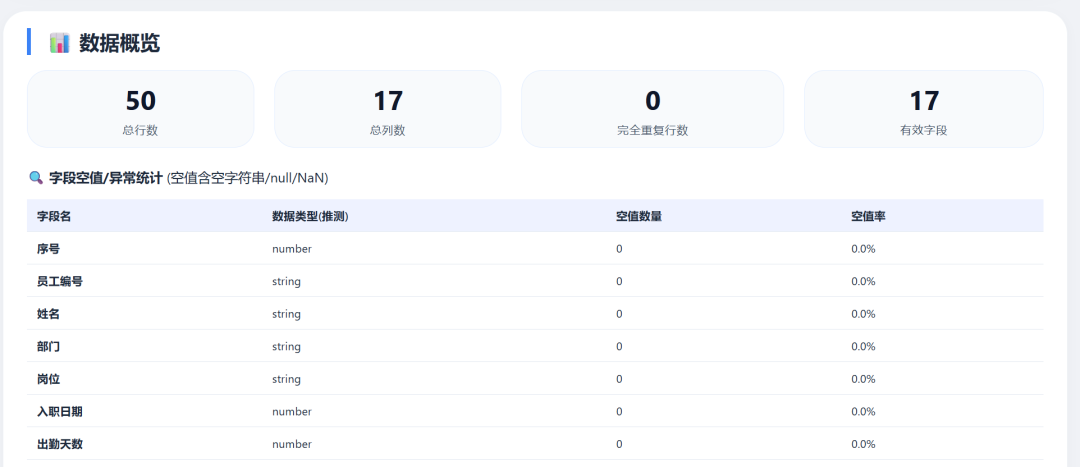
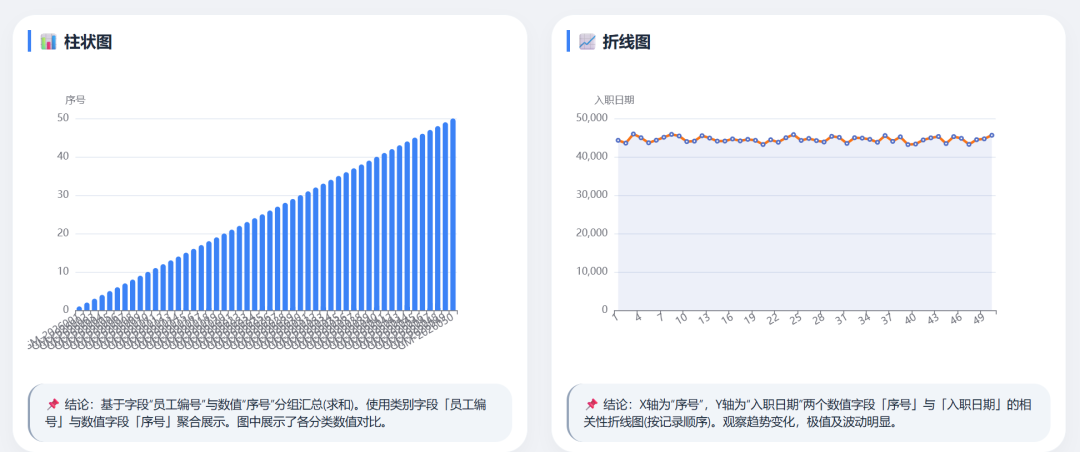
DeepSeek-V4 Flash 数据可视化图:
同样问题,提问给DeepSeek-V4-Pro:
DeepSeek-V4-Pro数据分析可视化图:

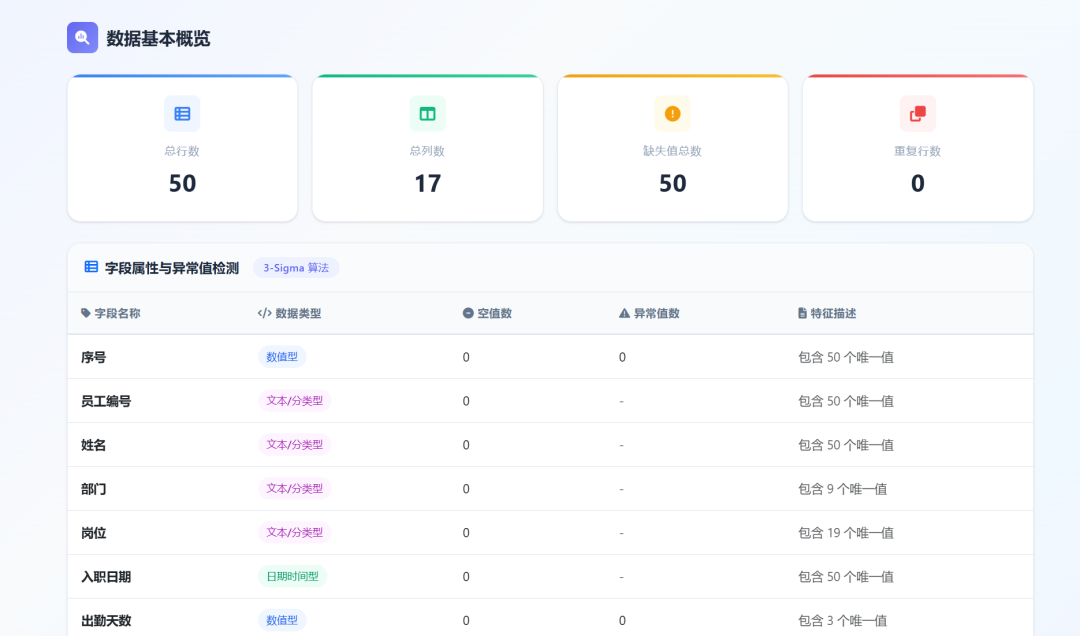
DeepSeek-V4-Pro 数据展示:
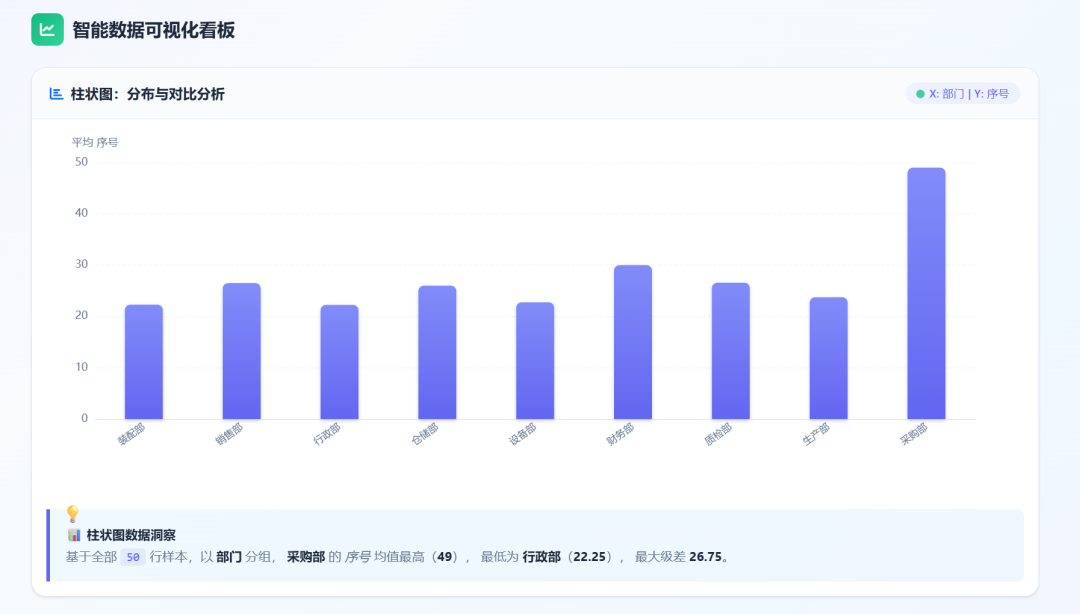
DeepSeek-V4-Pro 可视化图:
同样问题,提问GPT-5.5:
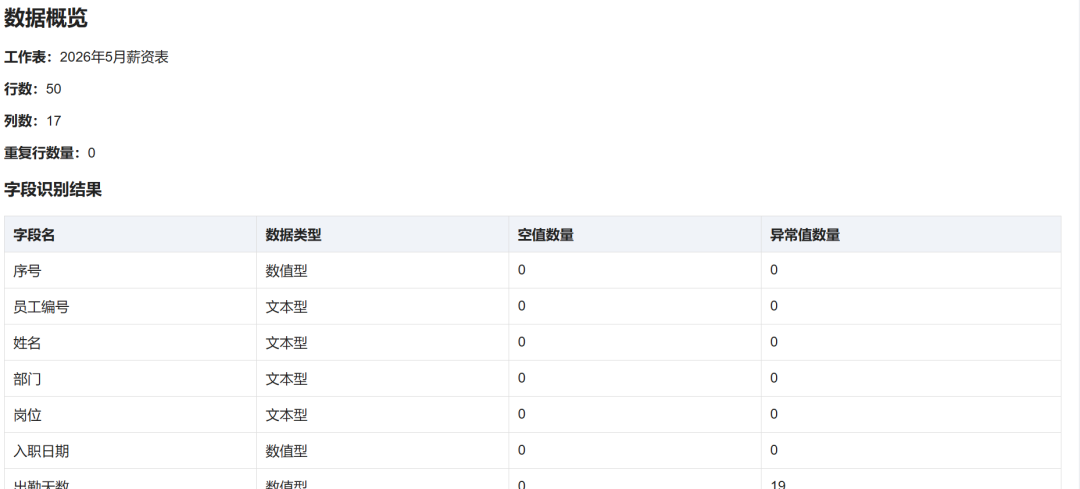
GPT-5.5数据展示:
可视化图:
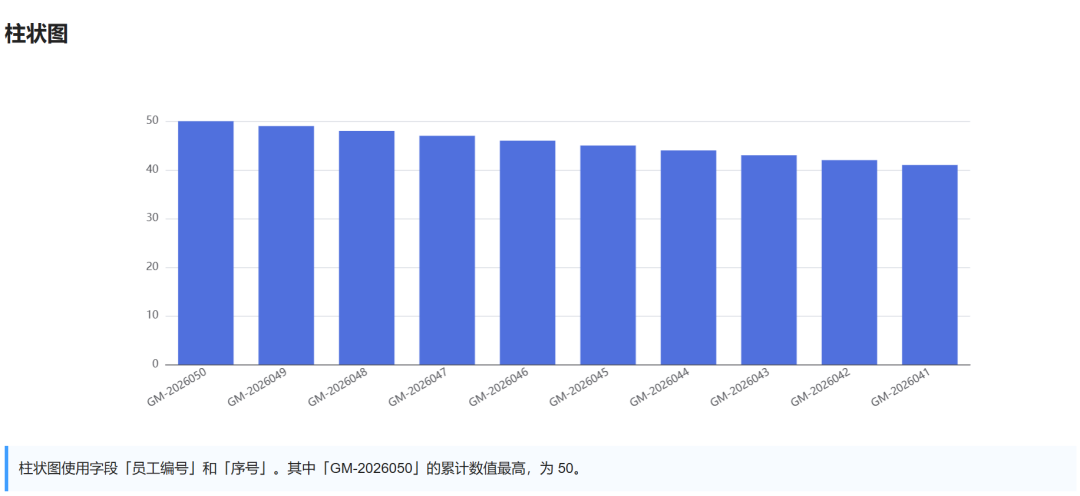
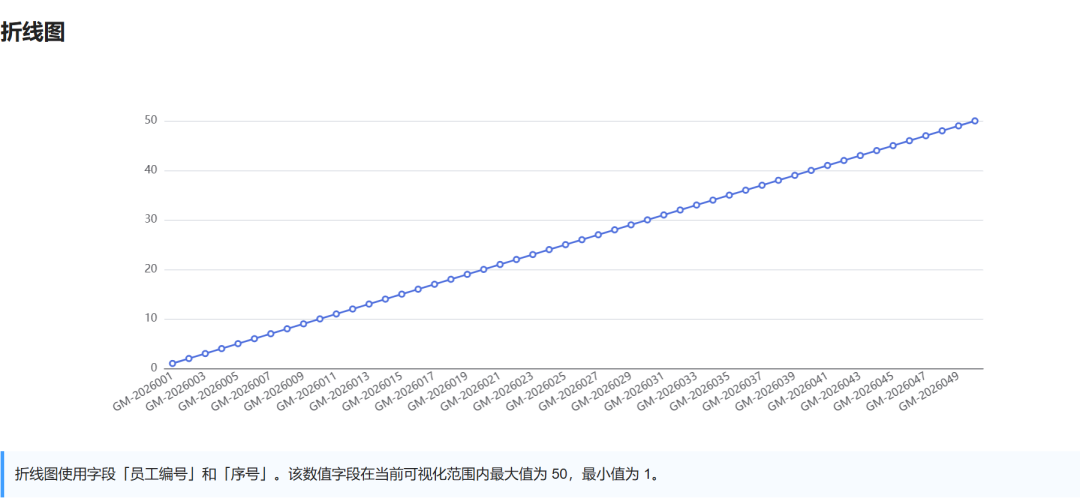
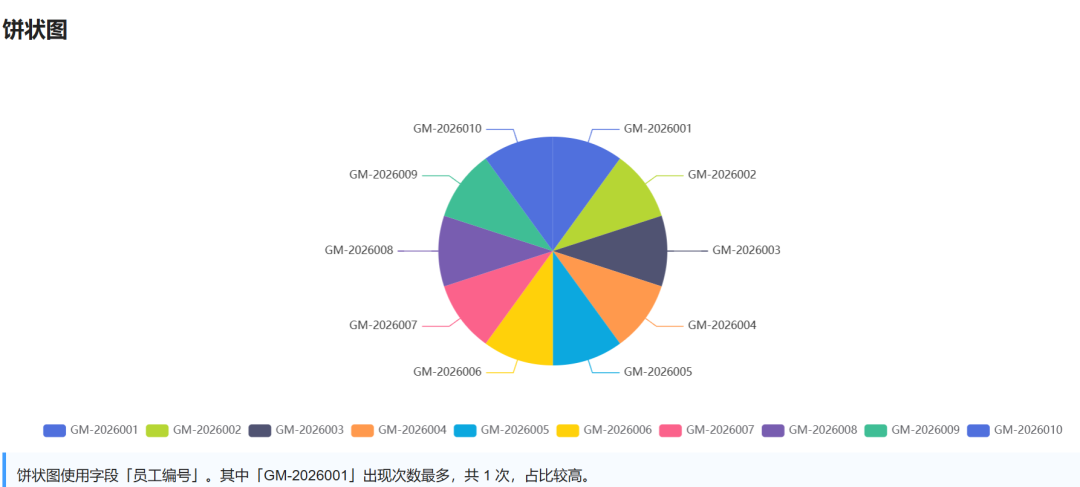
3 裁判打分
大概凭感觉也能看出来,谁会更好一些。但是为了更加客观,交给裁判Gemini-3.1-Pro模型,评估如下图所示:
裁判给出得分:
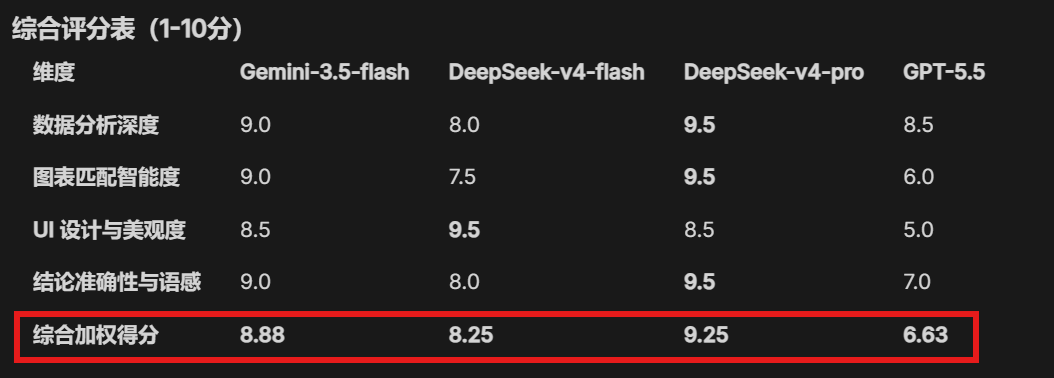
裁判给出详细解释:

再叫裁判总结为三句话,如下图所示:
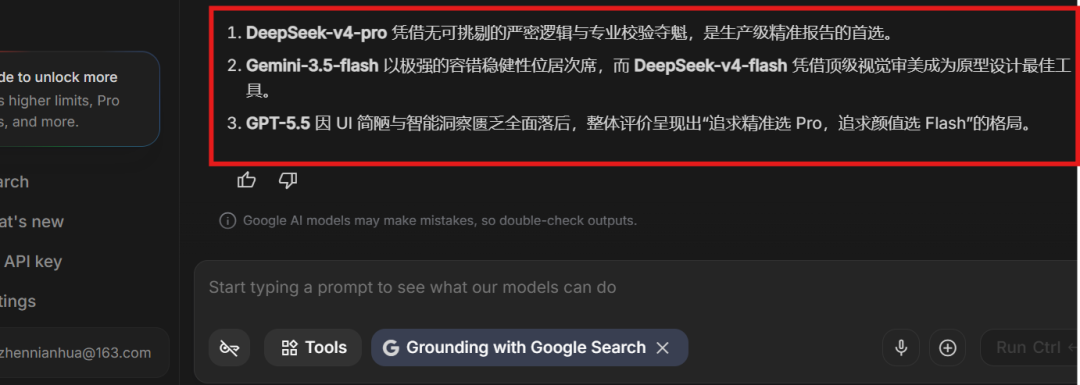
DeepSeek-v4-pro 凭借无可挑剔的严密逻辑与专业校验夺魁,是生产级精准报告的首选。
Gemini-3.5-flash 以极强的容错稳健性位居次席,而 DeepSeek-v4-flash 凭借顶级视觉审美成为原型设计最佳工具。
GPT-5.5 因 UI 简陋与智能洞察匮乏全面落后,整体评价呈现出“追求精准选 Pro,追求颜值选 Flash”的格局。
为啥GPT-5.5排到最后,我还特意多试了几次,都是这样,还是挺出乎我的意料!
最后总结一下
篇幅关系,这次只用一个小型 Agent 任务,初步实测 Gemini 3.5 Flash 的真实表现,整体完成度比较稳。
如果追求严谨报告,DeepSeek-V4-Pro 更强,而 Gemini 3.5 Flash 的优势是均衡、稳定、适合真实办公自动化场景。
GPT-5.5为啥这个任务表现不好,挺出乎我的意料!当然这只是小样本测试,后面再用更多更复杂任务继续实测。
常见问题
实测最新 Gemini-3.5,对比 DeepSeek-…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
实测最新 Gemini-3.5,对比 DeepSeek-…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
实测最新 Gemini-3.5,对比 DeepSeek-…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容