绝了!让AI手搓了一个PDF整书翻译APP,连图片排版都完美保留,直接导出为Word
你好,我是郭震!
整本书的翻译若直接交给大模型,后面页的翻译就会变为总结,而不是逐句翻译,这是因为大模型上下文窗口限制决定的。
除了这个问题外,还有一个致命痛点:** 文字是翻译出来了,但原书里那些重要的架构图、配图没有出现翻译中,只有干巴巴的文字。**
这篇文章我尝试探索解决这两个挑战性的问题,做出了一个网站app,直接解决了逐句+图片不丢问题,感兴趣的可以看看。
1 效果展示
说实话,开发这样一个包含PDF底层解析、图文剥离与重组的 Web App,传统方式至少需要一个前后端团队干上几天。但今天,我决定探索一种玩法:** 把这个复杂的长程开发任务,全权交给能力强的编程大模型,并在Claude Code这样编程神器解决翻译后图片排版问题。**
** 我选择的** 大模型** 是最近行业内热度很高的 GLM-5.1,看看它能不能像个“资深工程师”一样,从零帮我把这个系统敲出来。今天这篇文章我来记录这次实测过程,感兴趣的读者可以继续看看效果。**
如下所示,我只需要在本地浏览器打开它写好的 Web 界面:
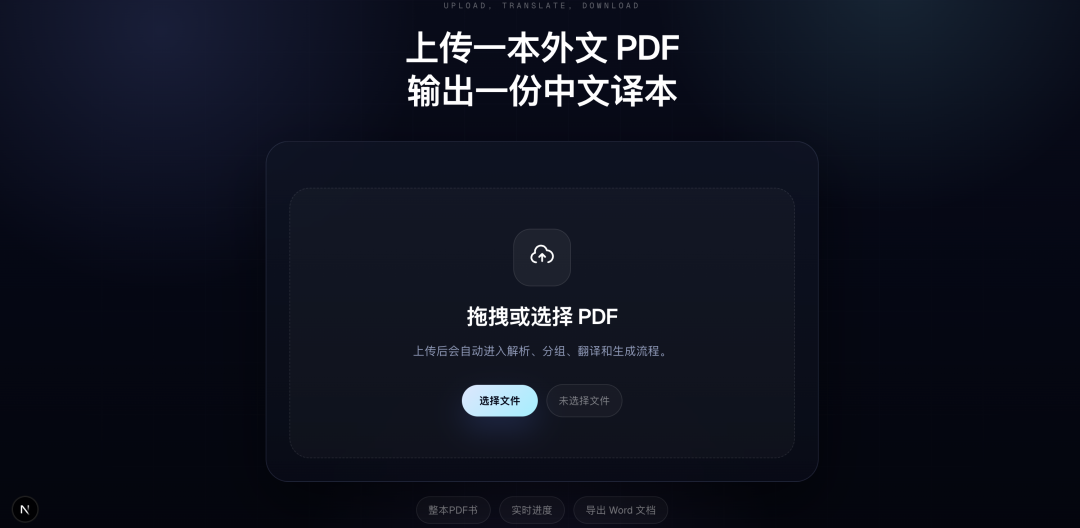
把一本67页的英文PDF论文,拖拽进去,点击开始翻译:
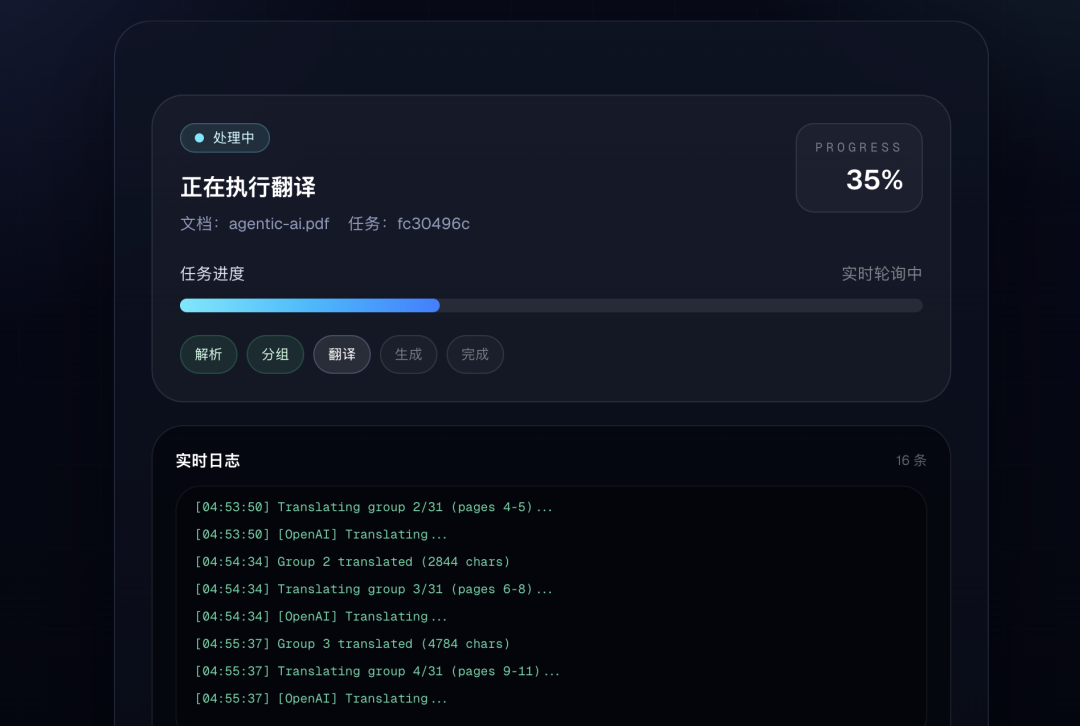
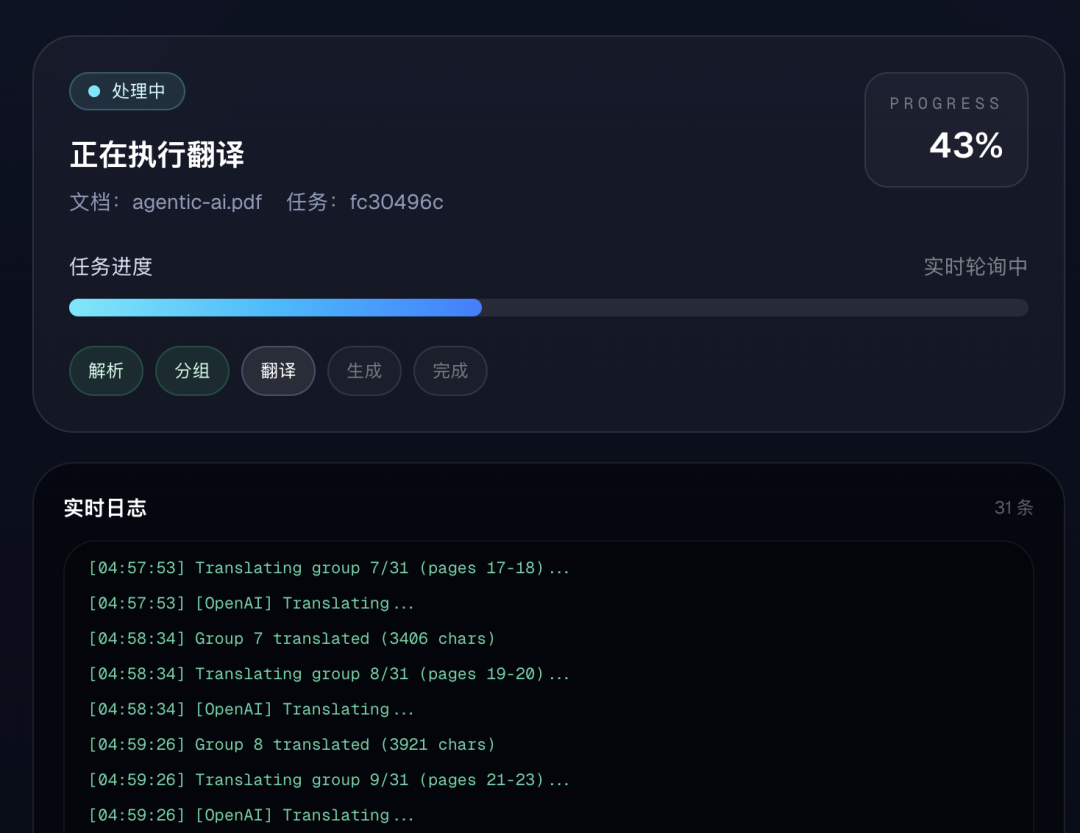
翻译进度到35%截图如下:
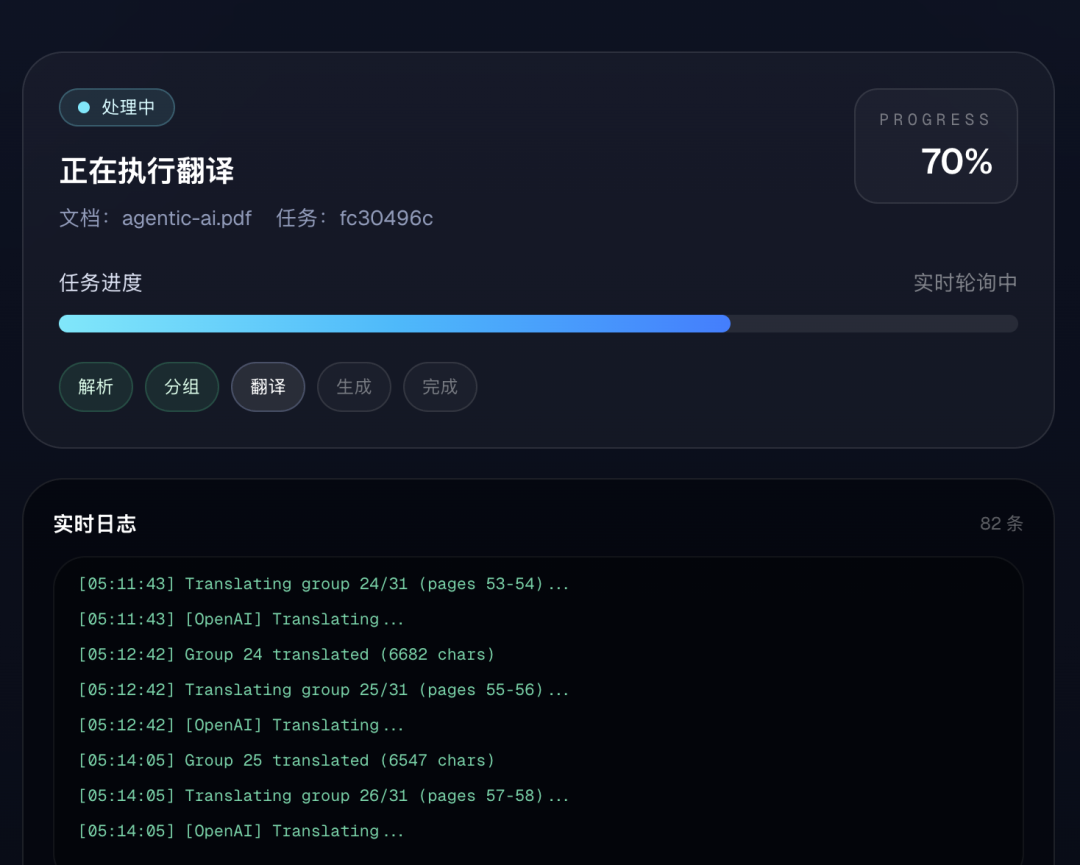
翻译到70%截图:
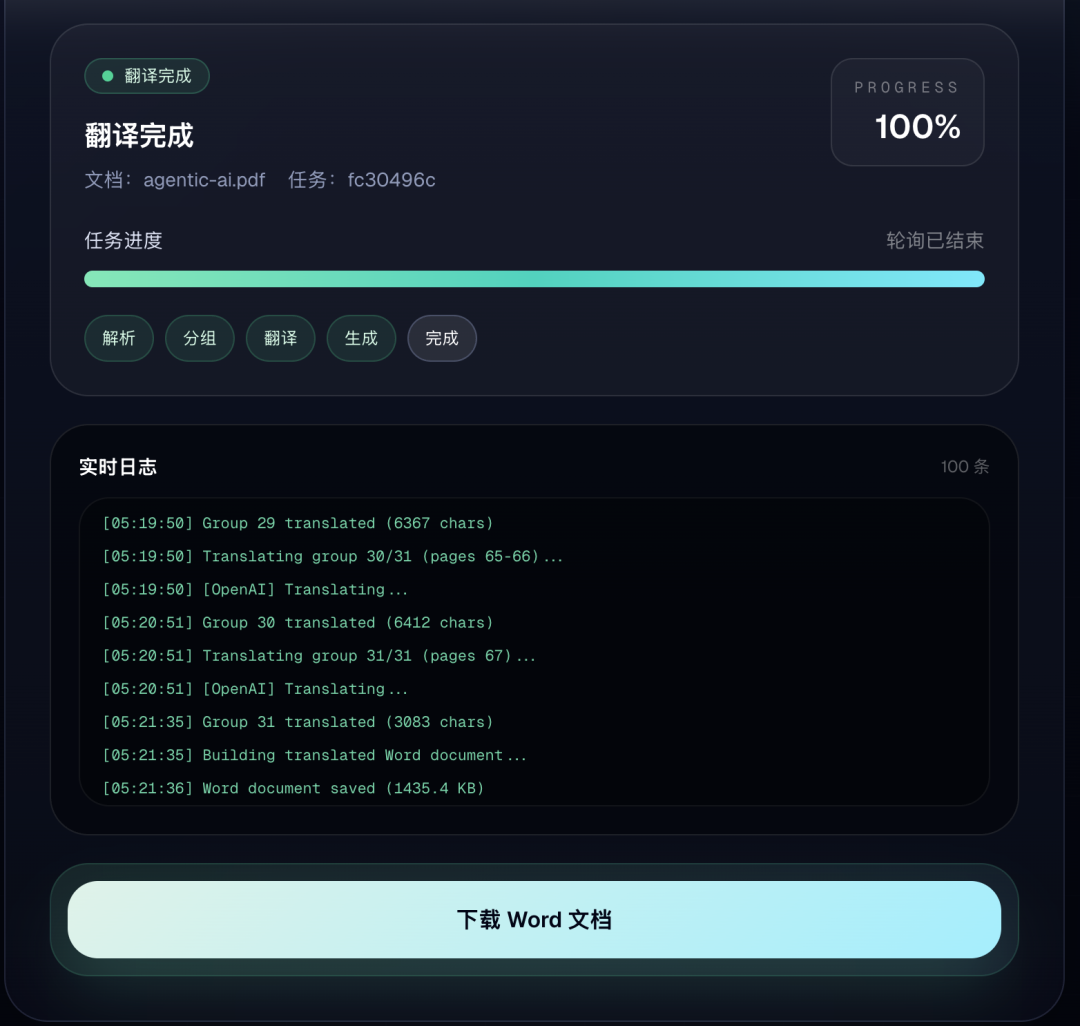
翻译完成截图:
点击下载Word文档按钮,它直接给我生成了一份全新的中文Word文档,如下所示为输出的文档对比,左边是全英文的原版 PDF,右边是系统翻译后的中文 PDF:

大家仔细看,不仅专业的长文本翻译得流畅,最关键的是,** 原书的配图被完美地按照先后顺序,穿插保留在了翻译好的中文里。**
整个操作在本地一键运行,使用比较方便。接下来,我教大家如何配置并做出这个App系统。
2 GLM-5.1接入到Claude Code
要想让 AI 自动帮我们写出这么复杂的系统,普通只会“一问一答”的模型是搞不定的。
这次实测我选用了** GLM-5.1**。根据文档介绍,目前它尤其擅长处理面向“长程任务(Long Horizon)”。
什么是长程任务?就是当你布置一个复杂项目时,它能像资深工程师一样,自己记住上下文、自己调用工具、出错了自己排查并持续执行,直到交付完整结果。
据我了解,它目前在权威的 SWE-bench 等编程榜单上已经夺得开源第一,在海外开发者社区 OpenRouter 上的调用量也是断层领先,非常受极客欢迎。
为了发挥它最强的代码编写能力,我强烈推荐把它接入到目前最火的终端编程神器** Claude Code** 中组合使用。
配置步骤极简:
第一步,确保你的电脑安装了 Node.js,然后在终端运行一行命令安装 Claude Code:
npm install -g @anthropic-ai/claude-code
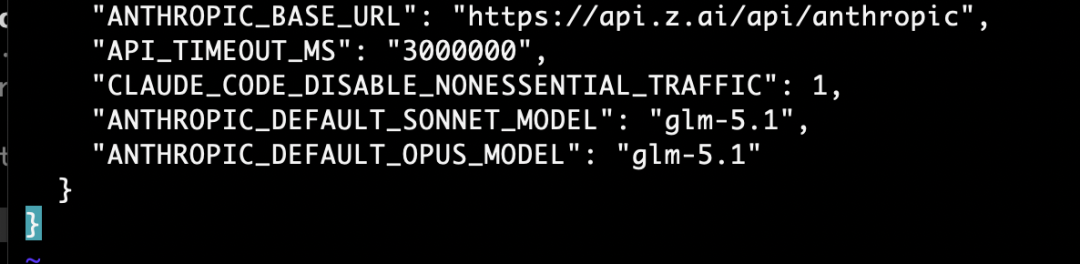
第二步,手动切换模型引擎。我们打开系统中的 Claude Code 配置文件(路径通常为 ~/.claude/settings.json),在里面加上一行配置,将底层调用的模型手动指定为 "glm-5.1":
配置保存后,你在终端里就拥有了一个由 GLM-5.1 驱动的、能直接读取你本地文件夹并自动写代码的“全能架构师”了。
3 全书翻译APP开发步骤
环境搭好后,我们直接在终端唤醒它,把“开发一个能逐句翻译整本书且保留图片的Web 网站”这个复杂需求丢给它,提示词如下:
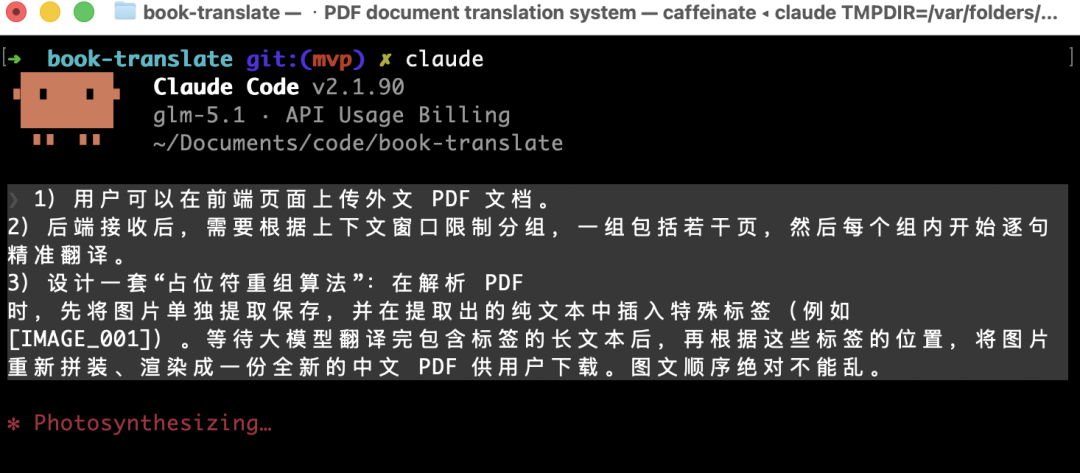
1)用户可以在前端页面上传外文 PDF 文档。
2)后端接收后,需要根据上下文窗口限制分组,一组包括若干页,然后每个组内开始逐句精准翻译。
3)设计一套“占位符重组算法”:在解析 PDF 时,先将图片单独提取保存,并在提取出的纯文本中插入特殊标签(例如 [IMAGE_001])。等待大模型翻译完包含标签的长文本后,再根据这些标签的位置,将图片重新拼装、渲染成一份全新的中文 PDF 供用户下载。图文顺序绝对不能乱。
如下发给Claude Code:
接下来的过程,逐步给大家展示下。
** 首先是架构规划。** 它没有急着瞎写代码,而是迅速给我输出了三套完整的开发大纲,比如第一套前端用 Vue,后端用 FastAPI:
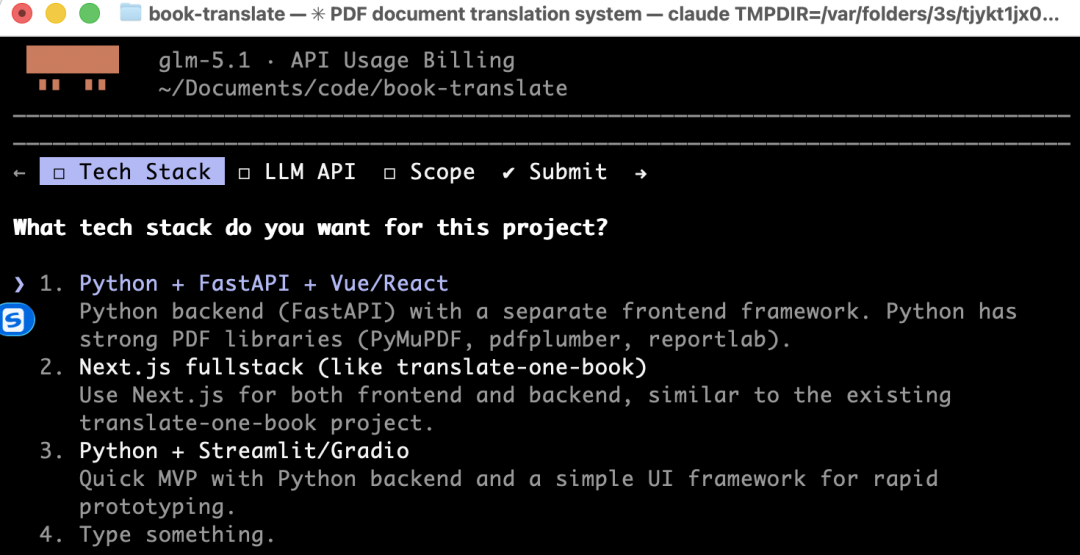
这种先定架构再干活的素养,比较符合SWE开发规范。根据个人喜好,大家自行选择,我比较喜欢方案2,所以选择2。然后选择翻译大模型,选择4,如下图所示:

接着它会问开发项目的完整度,是做一个最小可行项目,先跑通,还是做一个标准的项目,还是所有feature全包括:

根据个人喜好,我建议选择1,先跑通是最重要的,MVP方案。
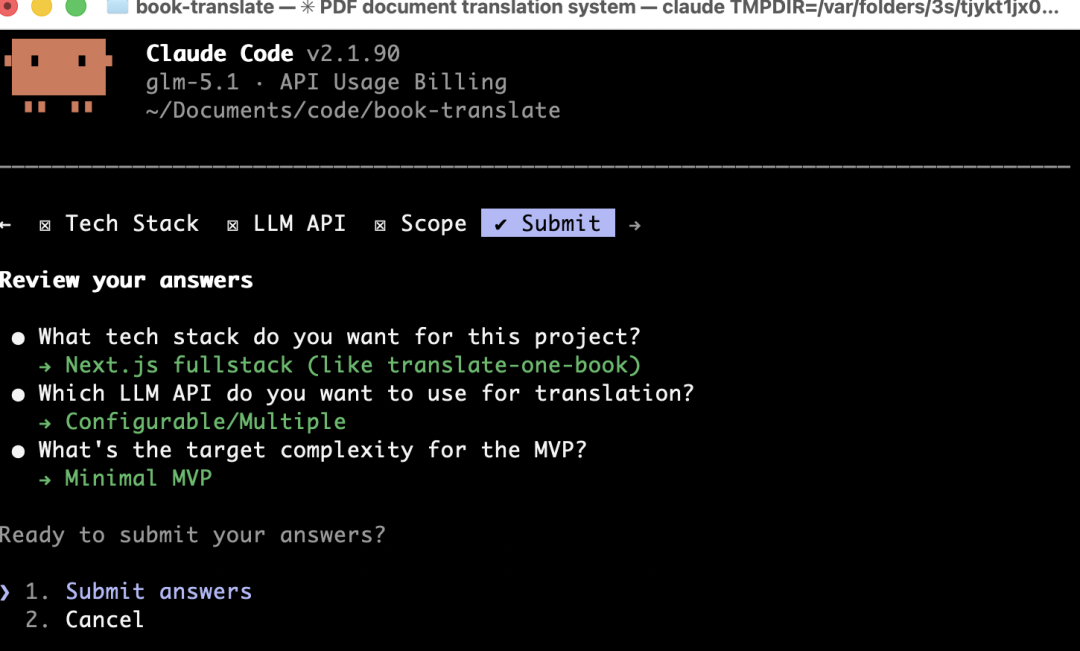
所有选择后,会给我们一个预览,然后告诉我们是否提交,选择提交回车:
第二步,接下来根据我们的要求,开始自动干活:
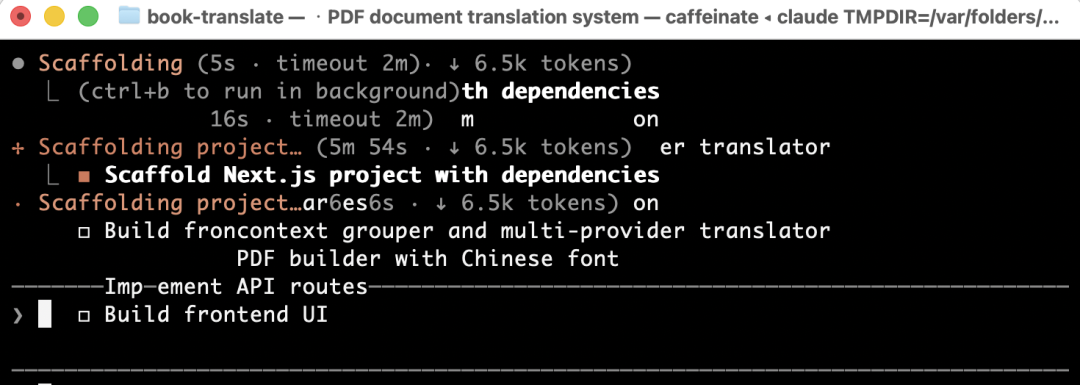
敲定方案后,它就像一个不知疲倦的打工机器,开始构建项目代码:
自动安装了146个第三方包,如下图所示:
甚至字体都会自动下载到本地,如下图所示:
已完成PDF读取,以及图片提取,如下图所示:
大概12分钟后,后端代码全部自动开发完成,如下图所示,开始自动编写前端代码:
编写前端部分代码,截图如下所示:
** 它在中间会“自我纠错与算法设计”。** 在进入深水区写核心代码时,中途遇到一个PDF解析器的报错,它没有停下来等我,而是自己查看本地错误日志,定位并修改了配置:
** 它又自动发现了一个进度条面板的错误,如下自动修复了错误使用useState问题:**
整个项目前后端代码+自动修复错误,完成后截图如下图所示:
并且列出实现的关键项目文件:

运行方法都告诉我了,如下图所示:
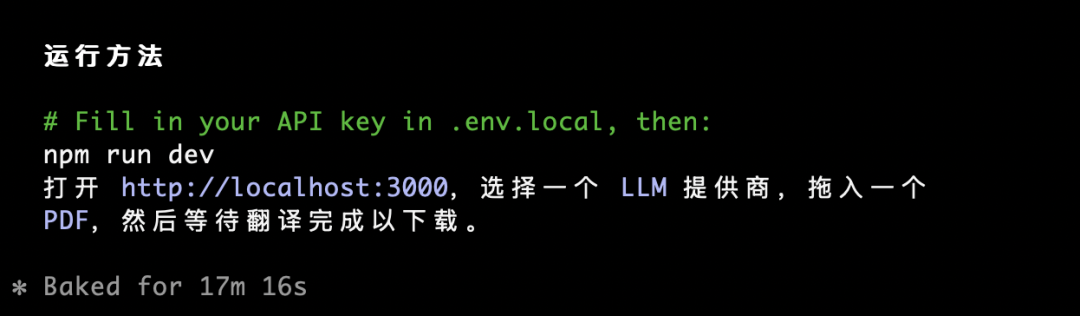
** 最终,它凭一己之力,高效率地给我交付了这个直接能跑的完整 Web 项目,完成全部任务用时17分钟16秒,首页截图如下所示:**
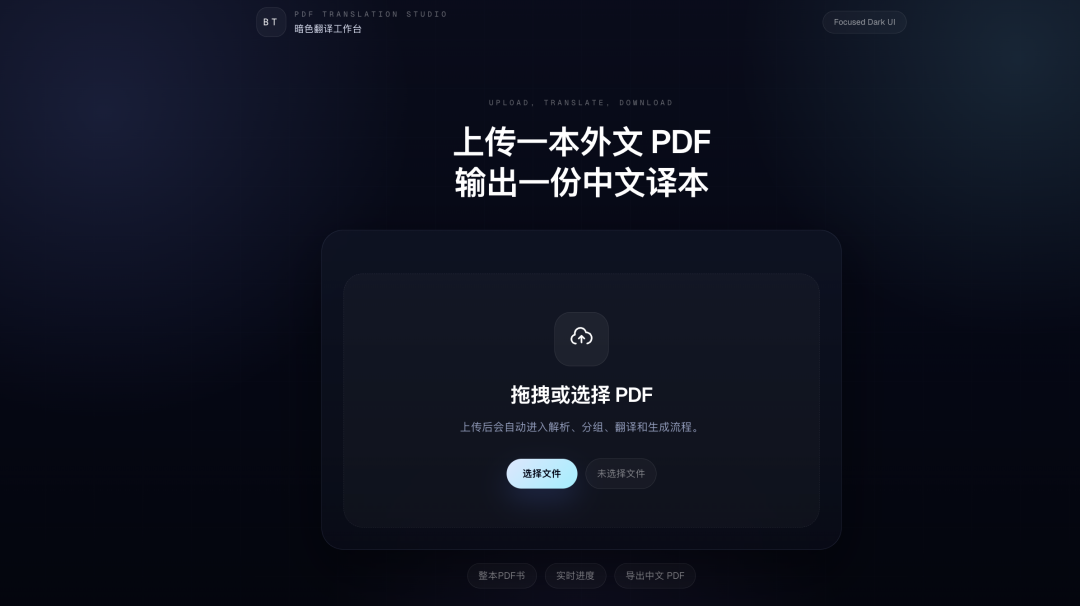
直接支持翻译一本PDF书,能做到逐句翻译,如下图所示:
最后总结一下
本文借助开发一个复杂的【整书图文翻译APP】,探索了目前大模型在实际生产中的能力边界。
今天实测的 GLM-5.1 让我看到,面对长时间跨度、多文件协同的复杂工程,它已经具备了自主规划、纠错并完整交付的“长程任务能力”。学会利用这种级别的 AI,无疑是我们普通人零门槛打造个人工具库的最佳时机。
虽然智谱的 Coding Plan 是最难抢的,而且价格也更贵,但是综合下来,它的模型能力确实是国内最强的。慢是慢点,但是输出的质量最好。很多时候,其他厂商的 Coding Plan 里面提供的智谱模型,好像都有一些能力问题或者是量化的感觉。
常见问题
绝了!让AI手搓了一个PDF整书翻译APP,连图片排版都…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
绝了!让AI手搓了一个PDF整书翻译APP,连图片排版都…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
绝了!让AI手搓了一个PDF整书翻译APP,连图片排版都…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容