实测DeepSeek-V4,GLM-5.1,GPT-5.5谁更强?结果出人意料!
你好,我是郭震!
DeepSeek-V4 正式发布,这篇文章是我的实测笔记,感兴趣的可以看下。
我的测试思路:测试V4其中最重要的两大升级维度:1M上下文处理能力,Agent能力。同样问题提问V4,GLM-5.1和最新GPT 5.5,选择Gemini 3.1 Pro为裁判,然后把各自答案输入给裁判,并从三个最重要评估维度给出打分及最终结论。
限于篇幅和时间,主要测试两大升级维度,测试结论只供参考。
1 DeepSeek-V4
按照官方介绍,这次 DeepSeek-V4 分成两个版本,一个是 DeepSeek-V4-Pro,主打更强的推理、代码和 Agent 能力;另一个是DeepSeek-V4-Flash,主打更快、更经济,适合日常问答和轻量任务:
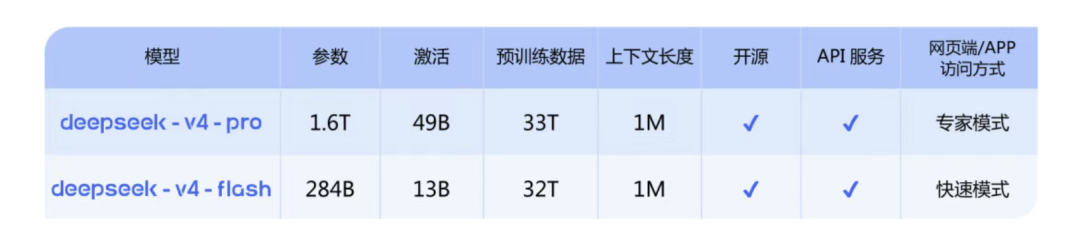
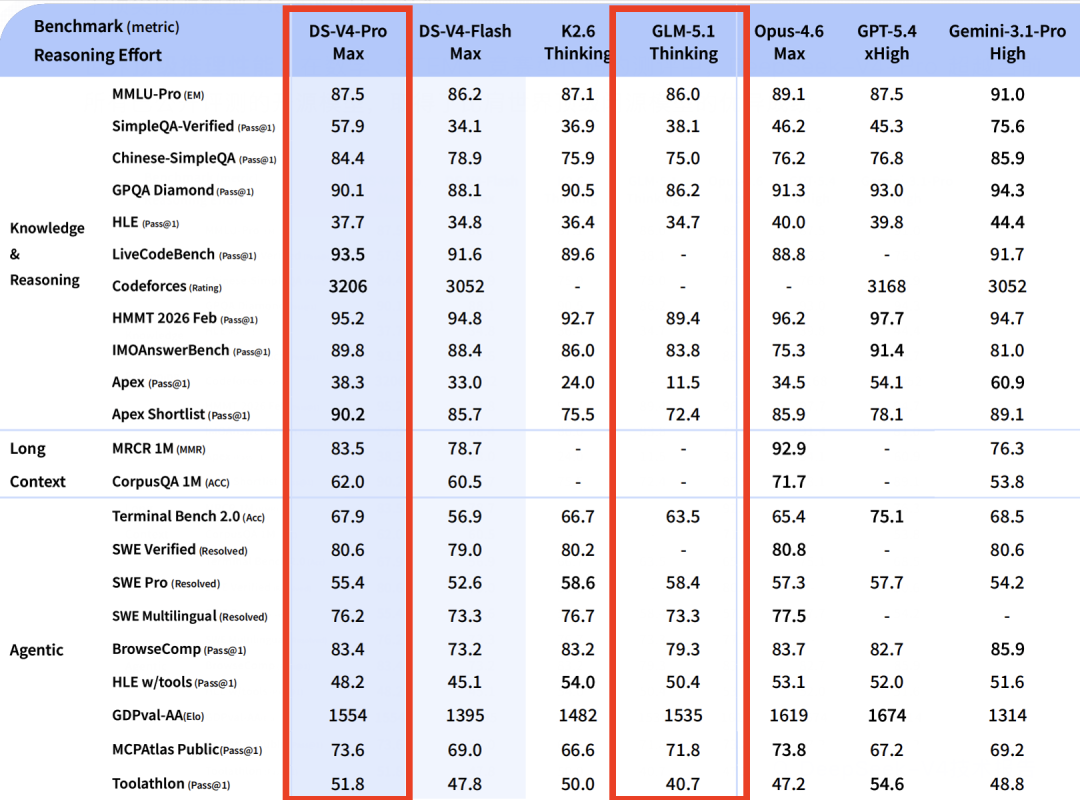
V4推理性能比肩顶级开源模型,DeepSeek官方给出的评估表格中还有GLM-5.1,K2.6这两大国产大模型:
2 1M上下文对比测试
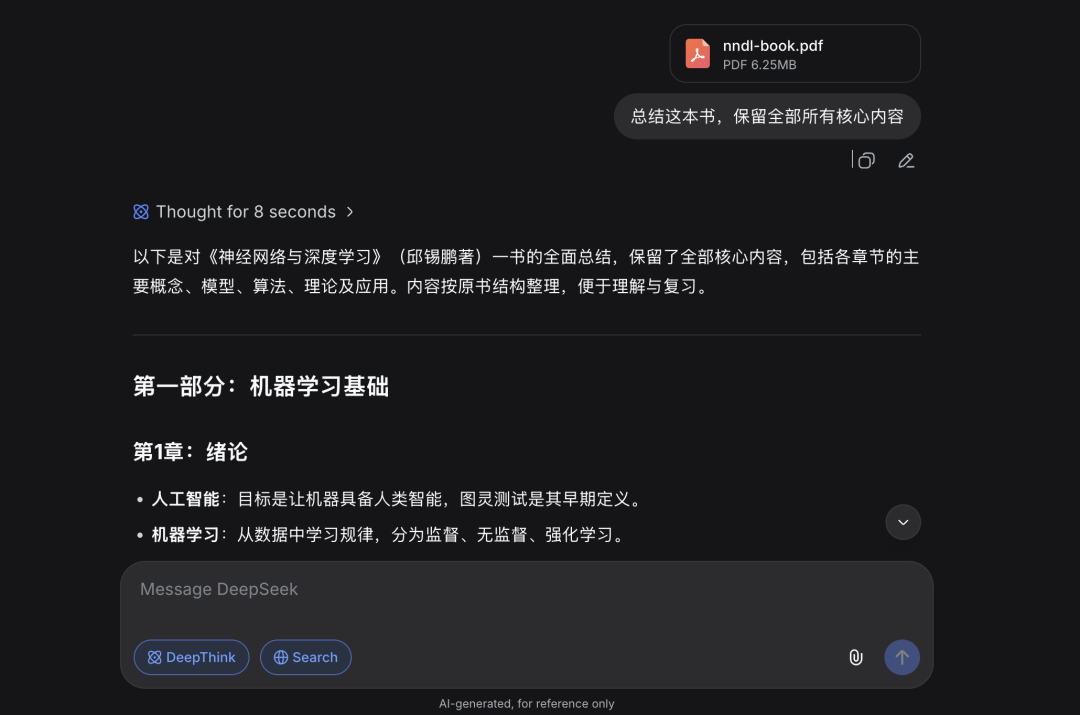
第一个实测,我把一本400页+的,邱老师编写的神经网络这本书丢给 DeepSeek-V4:

如下提问,以下是回复首屏:
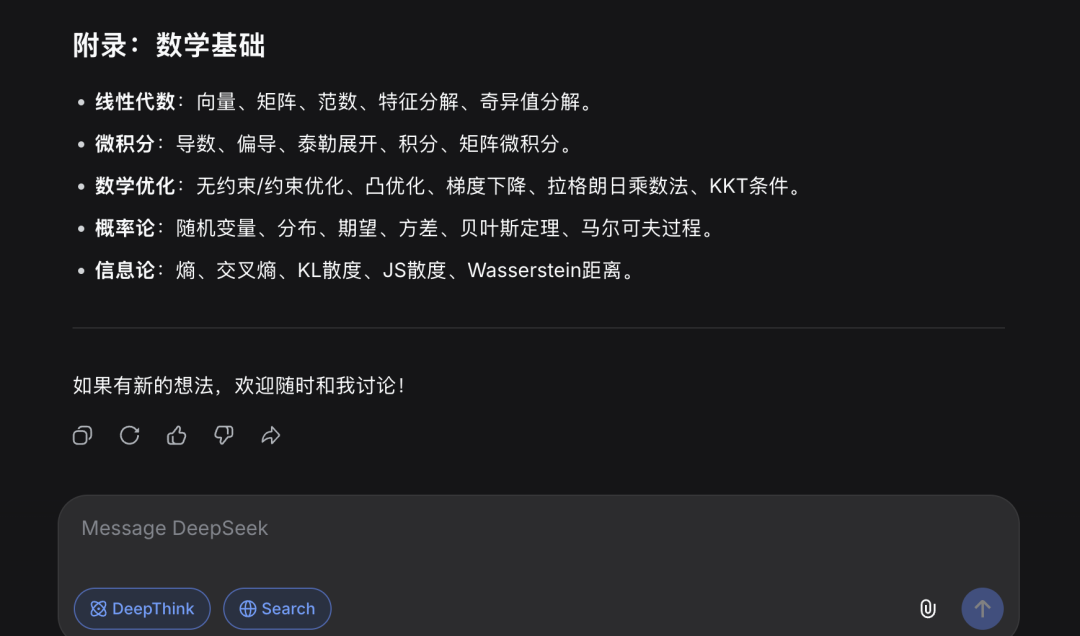
回复最后截图:
同样问题,提问GLM-5.1,如下:

回复最后截图:

同样问题,提问GPT最新5.5,回复首屏:
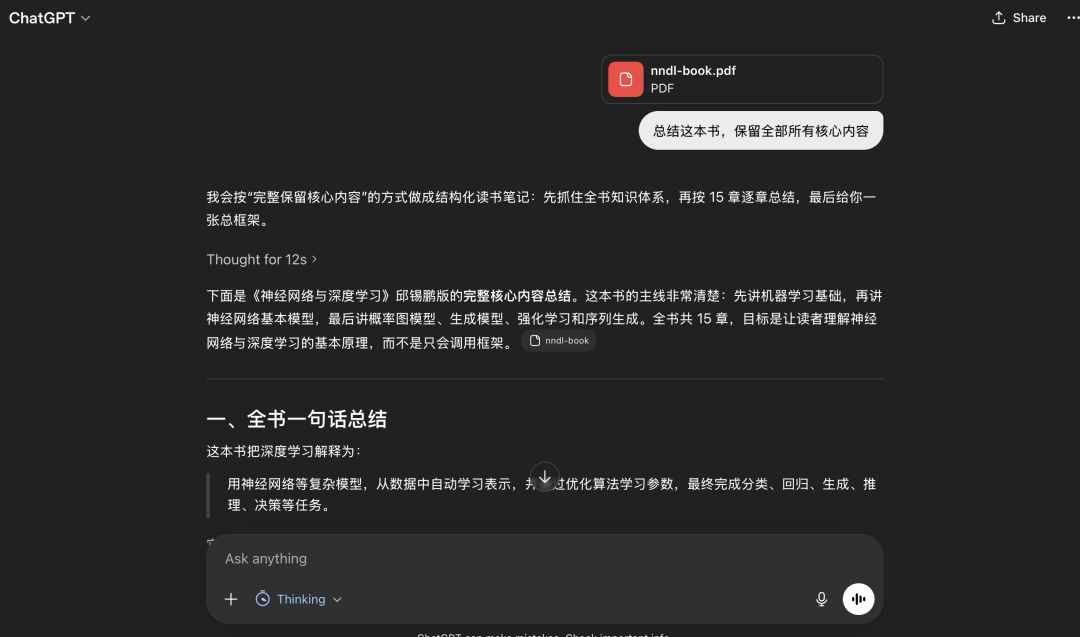
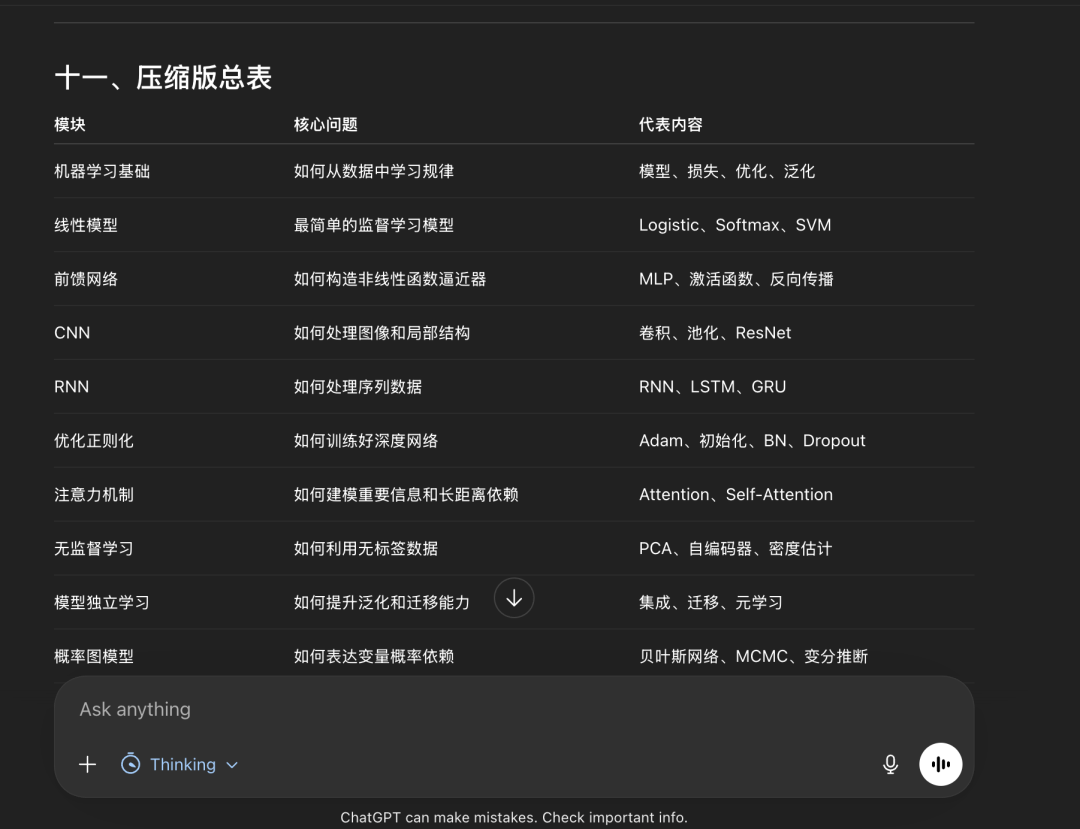
回复最后截图:
然后我把DeepSeek-V4,GLM-5.1和GPT 5.5的回复全部发送给Gemini 3.1 Pro,从三个角度评价,哪个模型胜出:
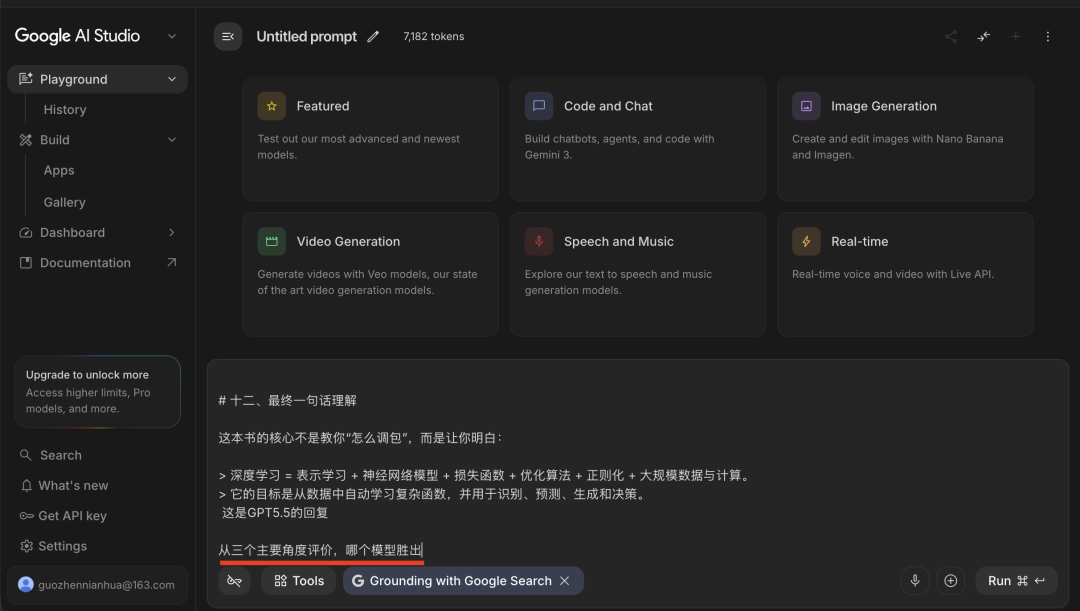
这是Gemini 3.1 Pro给出的答案:第一名,GPT 5.5 ;第二名,GLM-5.1;第三名,DeepSeek-V4:

3 Agent能力对比测试一
第二个实测,我主要看 DeepSeek-V4 ,GLM-5.1和 GPT 5.5 的 Agent 能力。
开发本地网页工具,用户可以上传 txt 文件,然后自动统计字数、段落数、关键词,并生成一段摘要,页面还要支持复制摘要,最好可以直接在浏览器打开运行
我的提示词是:
请你帮我做一个本地网页工具,功能如下:
1. 用户可以上传一个 txt 文件;
2. 自动统计字数、段落数、关键词;
3. 自动生成一段摘要;
4. 页面支持复制摘要;
5. 页面要简洁好看,可以直接在浏览器打开运行。请你给出完整代码、文件结构和运行方法。
这个任务不算特别复杂,但它比单纯写一个函数更接近真实需求。因为它需要同时考虑页面、交互、文件读取、文本分析、复制按钮和运行方式。
如下先提问V4:
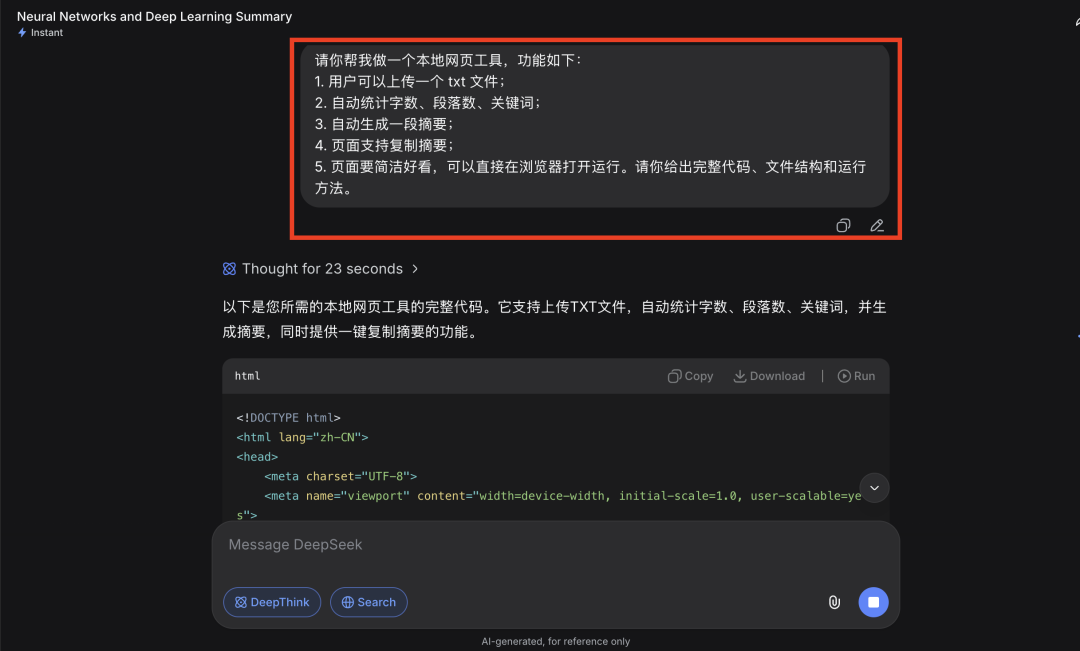
V4 生成结果如下所示,右侧可以直接操作:
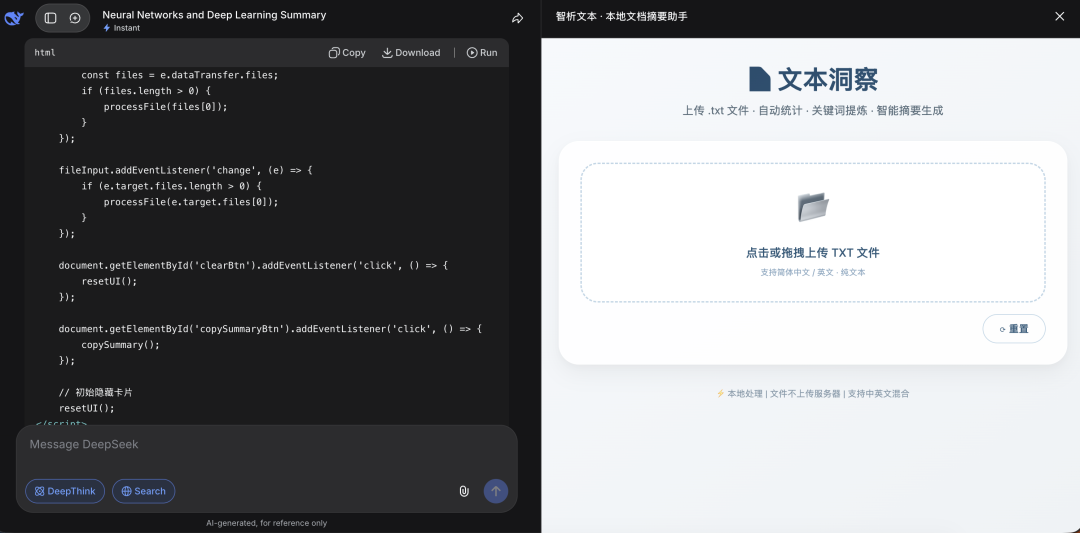
同样提示词发给 GLM 5.1,生成结果如下:
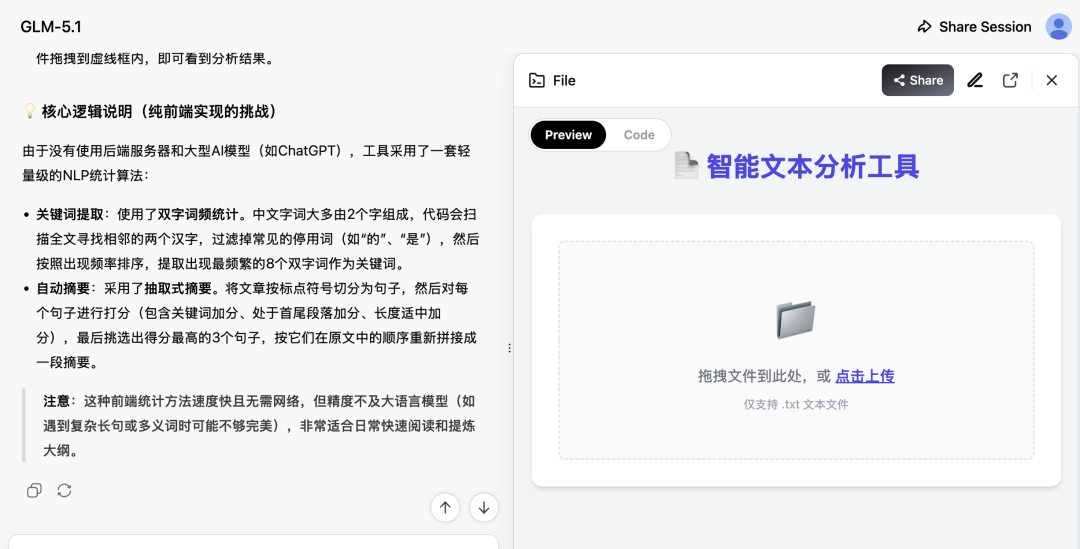
GPT 5.5 生成结果如下所示:
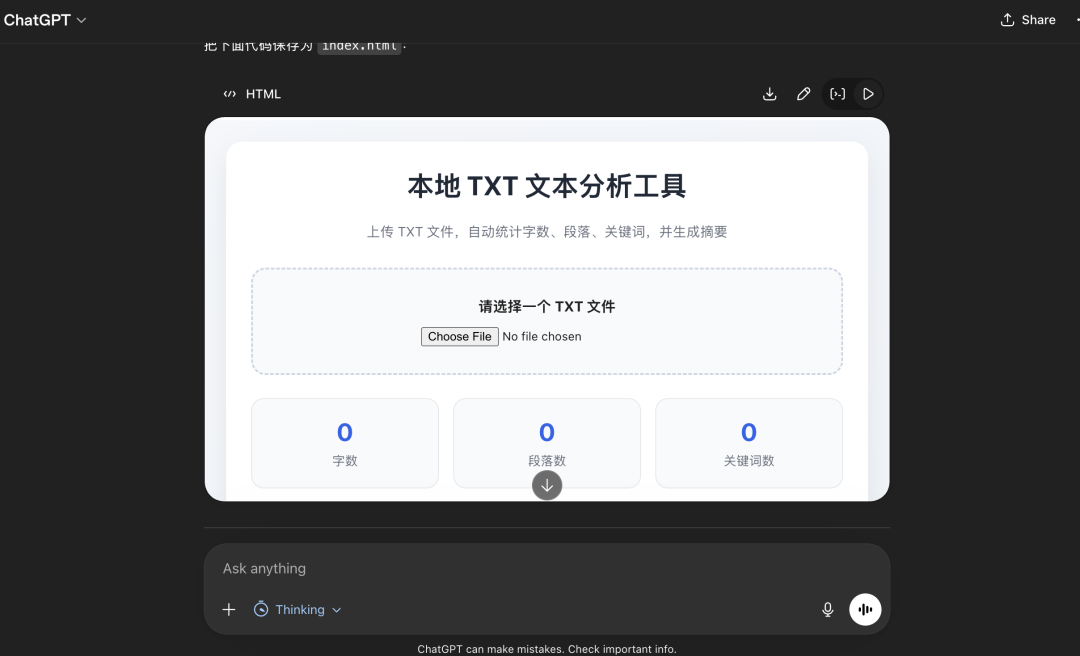
我还是把三个网页直接发给Gemini 3.1 Pro,让它从三个最重要角度评价Agent能力,如下是结果:
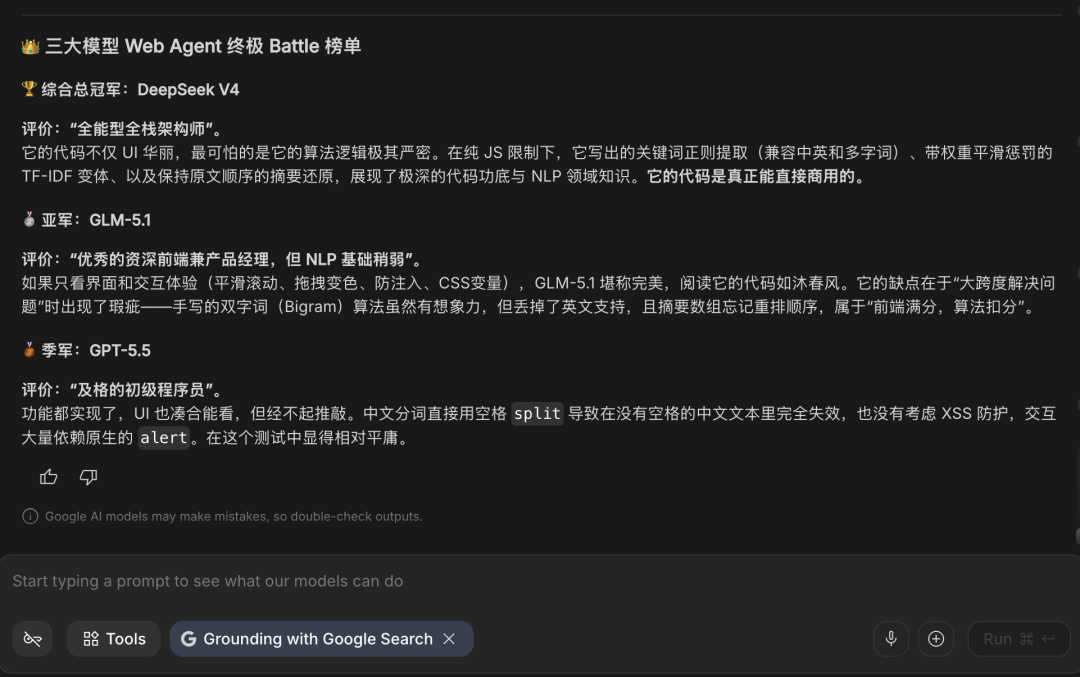
关于Agent能力第一个测试用例,Gemini 3.1 Pro给出答案:第一名,DeepSeek-V4 ;第二名,GLM-5.1;第三名:GPT 5.5
4 Agent能力对比测试二 同样思路,这次测试侧重:交互应用能力 + 状态管理能力,例子如下所示:
请开发本地“英语单词复习卡片”网页工具,可以直接双击 index.html 运行。用户可以添加单词、释义和例句,支持随机抽卡、标记掌握/未掌握,并自动统计学习进度。
DeepSeek-V4,结果如下:
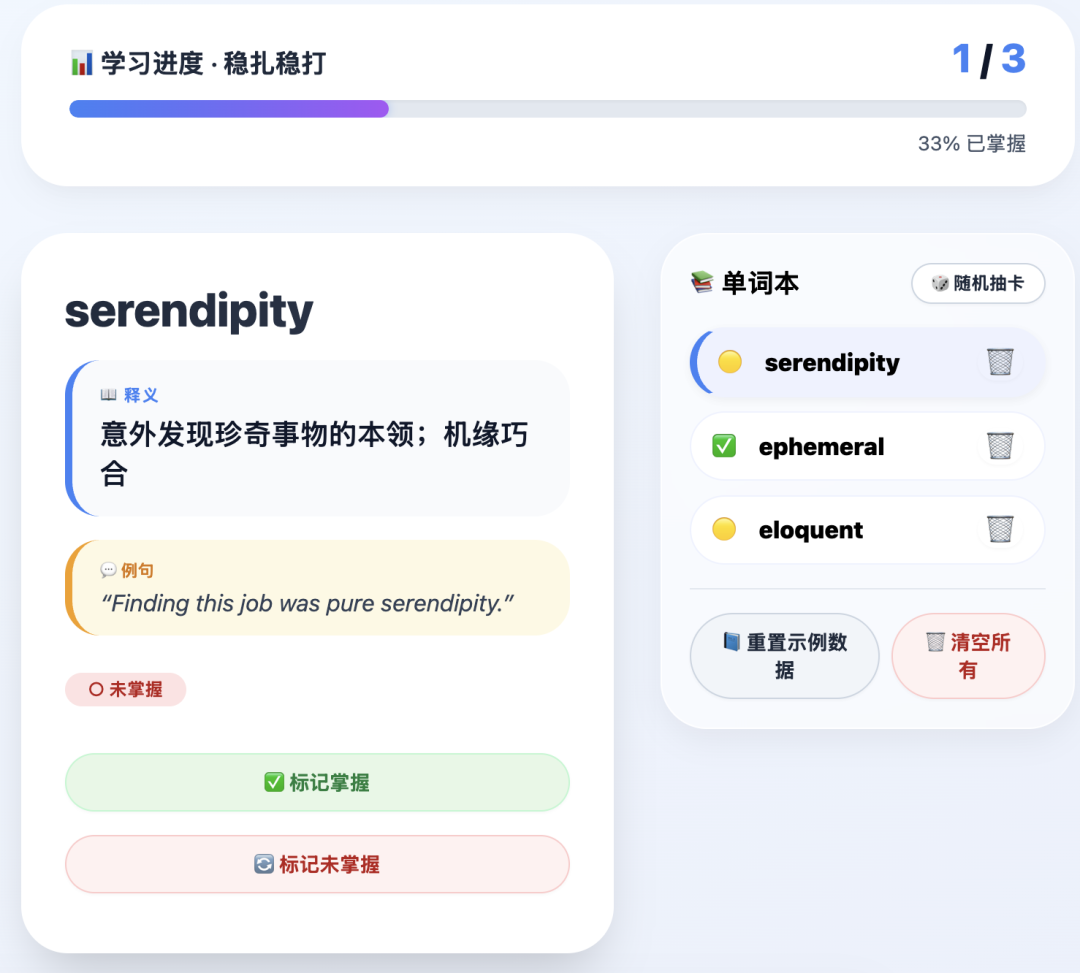
GLM-5.1,结果如下:
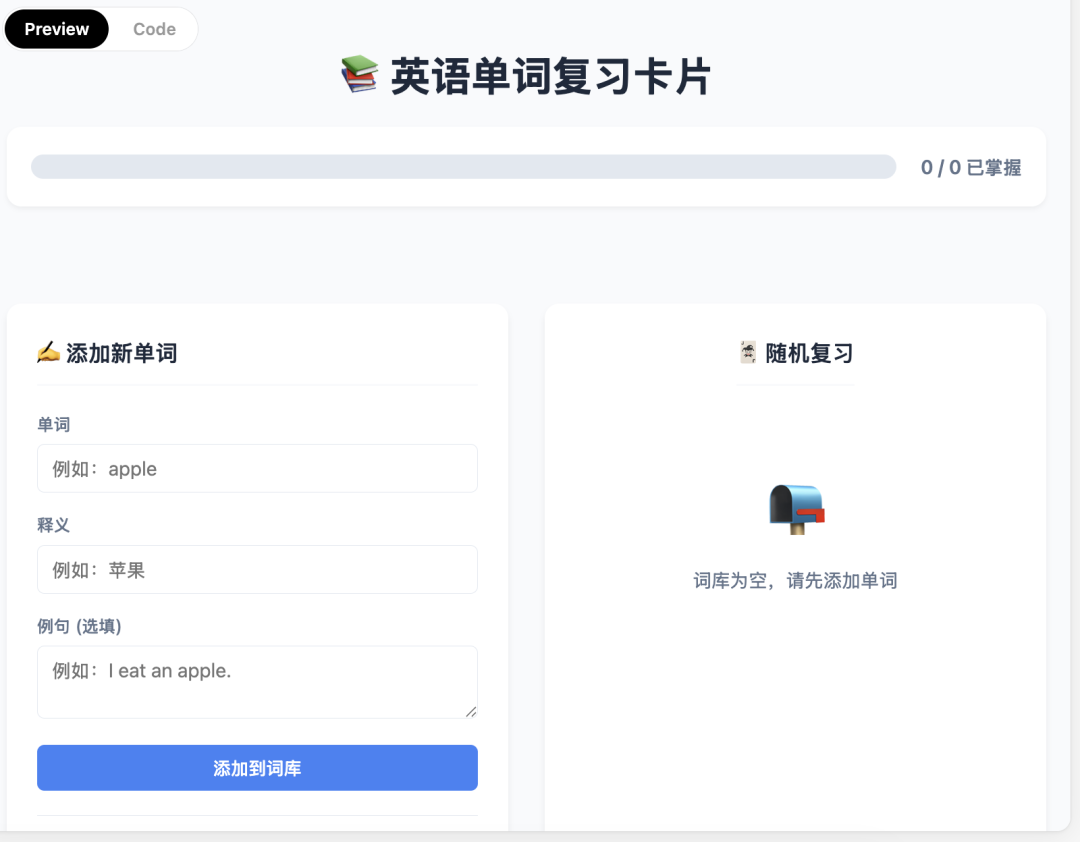
GPT-5.5,结果如下:
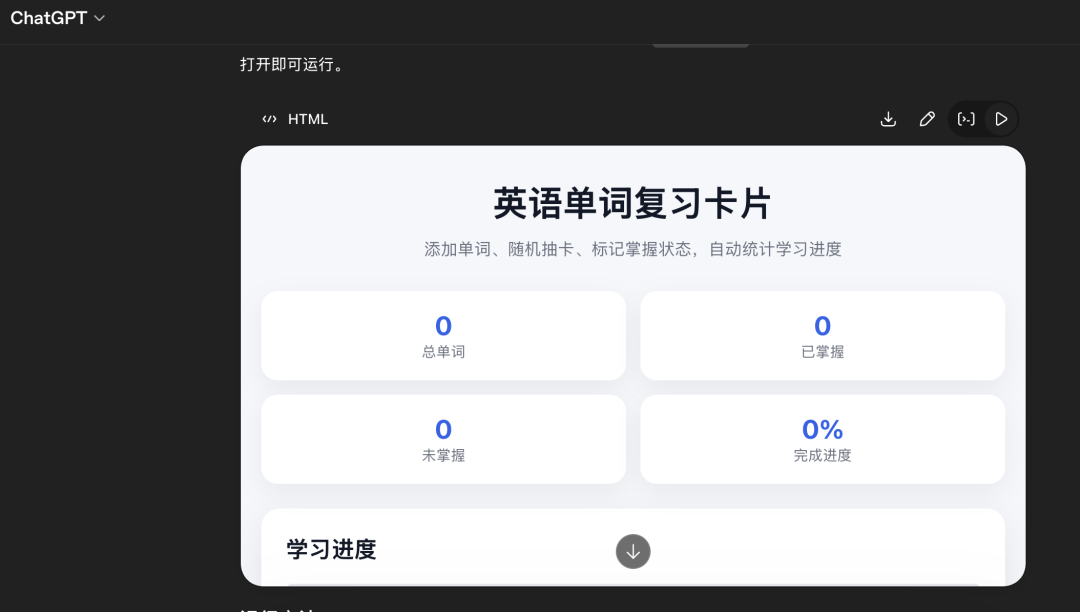
把以上三个html发给Gemini-3.1-pro中评判下:
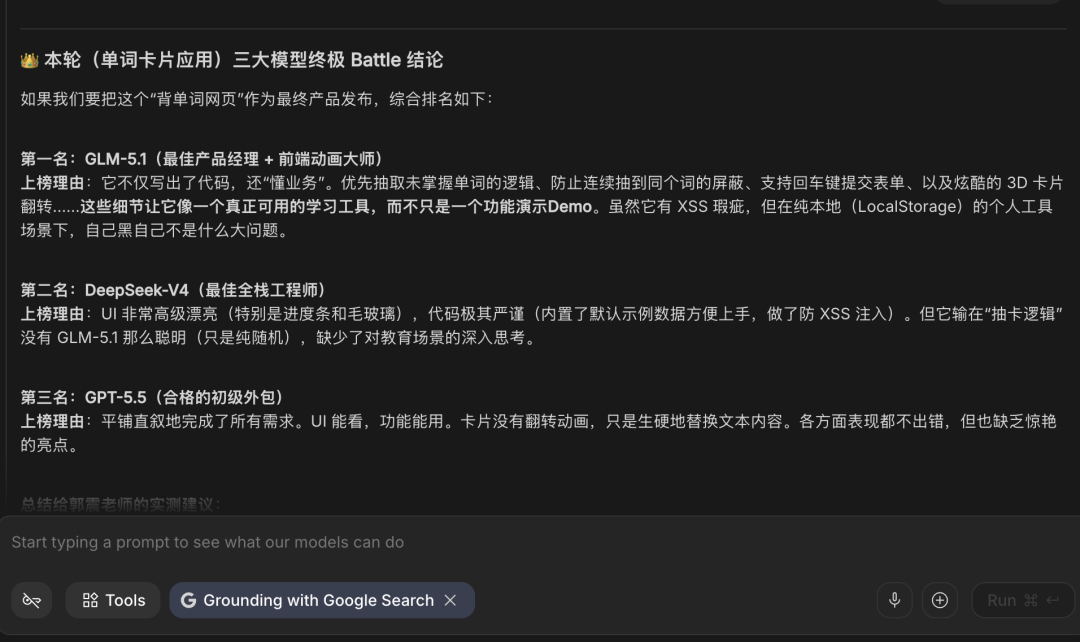
关于Agent能力第二个测试用例,Gemini 3.1 Pro给出答案:第一名,
GLM-5.1;第二名,DeepSeek-V4;第三名:GPT 5.5
最后总结一下
本篇实测从两个最重要的大模型评估维度:上下文处理能力,Agent能力
使用Gemini 3.1 Pro当裁判,篇幅关系,每个维度采取一局定胜负。
Gemini 3.1 Pro报告显示:
1)上下文处理能力,GPT 5.5 第一,GLM-5.1 第二, DeepSeek-V4 第三;
2)Agent能力,DeepSeek-V4 和GLM-5.1各有一次第一,GPT 5.5两次都是第三。
根据以上测试,多少还是出乎我的意料,本以为GPT-5.5的Agent能力很猛,但V4和GLM-5.1都超越它了。
DeepSeek-V4是开源的,而GPT 5.5还闭源,能够比肩顶级闭源模型:
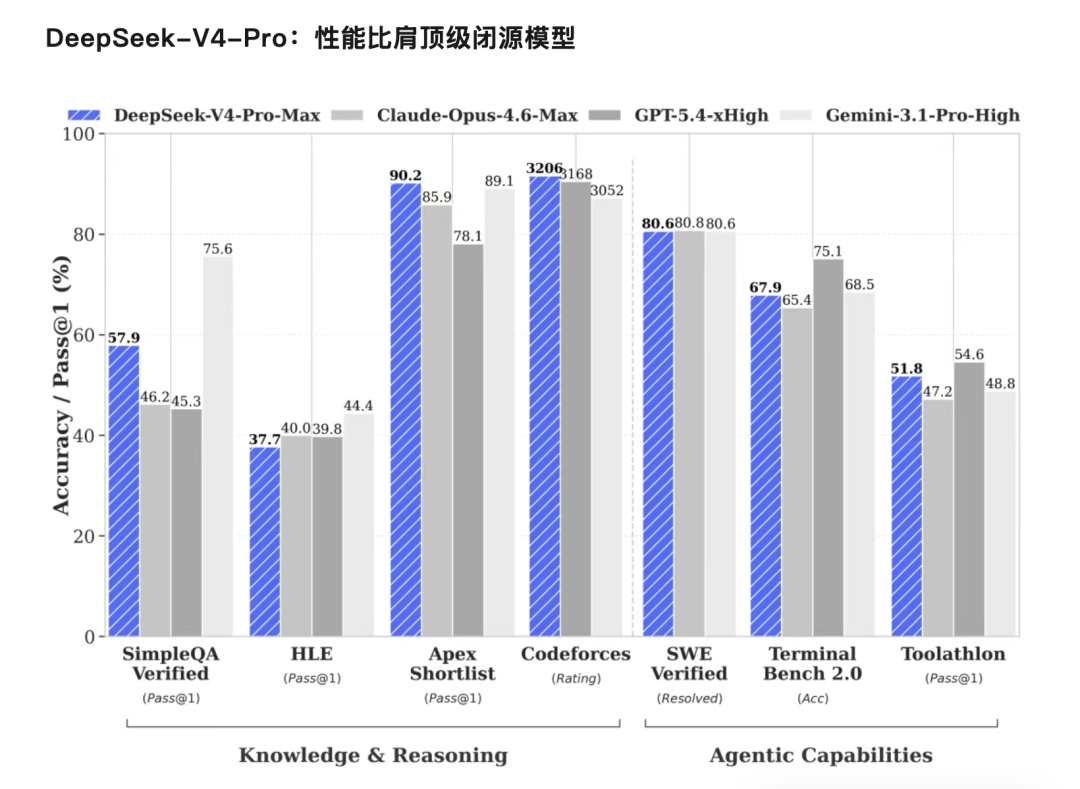
已经非常让人尊重!
正如DeepSeek团队所说:不诱于誉,不恐于诽,面对赞赏和诽谤,还能泰然自若,做到这点不易。
常见问题
实测DeepSeek-V4,GLM-5.1,GPT-5.…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
实测DeepSeek-V4,GLM-5.1,GPT-5.…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
实测DeepSeek-V4,GLM-5.1,GPT-5.…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容