实测最新 Qwen3.7-Max,对比 Claude Opus 4.8,DeepSeek-V4,结果太意外了!
你好,我是郭震!
最近 Qwen3.7-Max,Claude Opus 4.8,两个模型发布,
Claude Opus 4.8,第一,
Qwen3.7-Max,第二,前面只有 Opus 4.8,
到底实际生产表现如何,这两天实测了下,感兴趣的可以看下。
1 新模型介绍
这是 Code Arena WebDev 榜单,Opus 4.8,3.7-Max前两名:
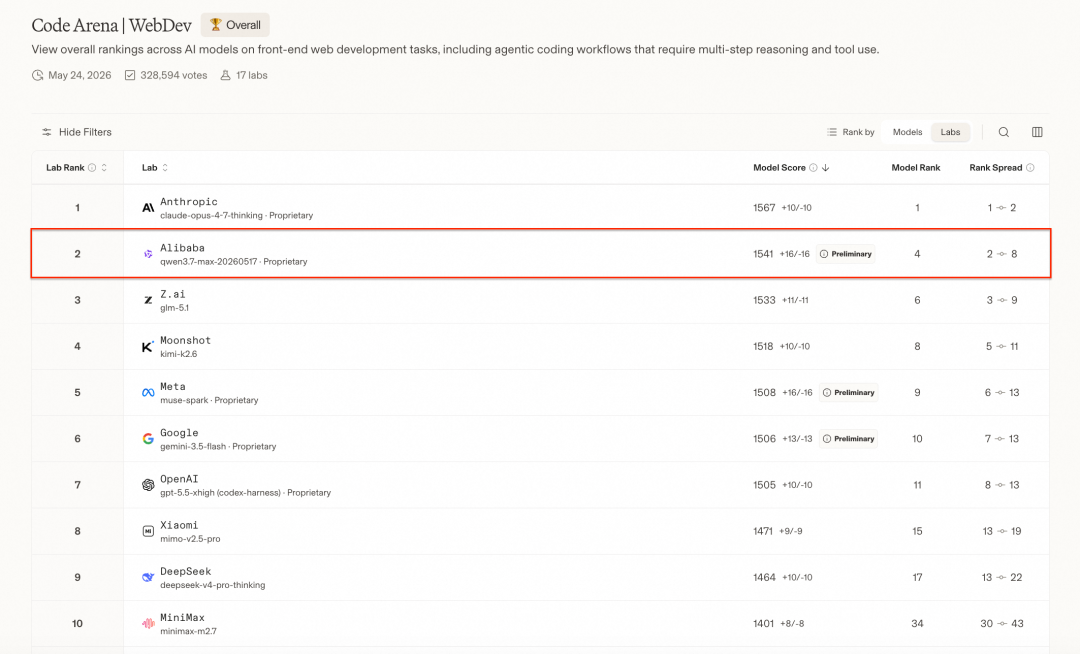
这个榜单专门评测 AI 模型在页面实现、复杂交互、多步骤编码、工具调用等。
值得一提,智谱,Kimi,小米,DeepSeek,MiniMax都在榜单中,看到了国产大模型的崛起。
这个榜单比较有参考意义,因为接近真实开发场景。
接下来直接开始测评
2 对比实测
测评思路:使用一个典型的中小型Agent任务,测评大家普遍关心的智能体能力。
然后选择Gemini-3.5-Flash和GPT-5.5为裁判,根据两个裁判的打分,给出客观的结果评估。
Agent任务,提示词如下:
开发一个单文件 HTML 网页,实现 Excel 数据分析与可视化工具。 支持上传 .xlsx/.xls,使用 SheetJS 解析 Excel,读取多 Sheet,并展示可搜索、分页、横向滚动的数据表格。 自动识别字段类型、统计行列数、缺失值、唯一值、最大/最小/平均/求和,并生成中文数据分析报告。 使用 ECharts 自动生成柱状图、折线图、饼图、散点图等可视化,并支持用户选择 X/Y 字段和图表类型自定义生成。 只输出完整可运行的单文件 HTML 代码,不要解释,不要 Markdown,不依赖后端。
先发给Qwen3.7-Max:
保存为html文件,并打开:

导入一个Excel文件,自动分页展示:
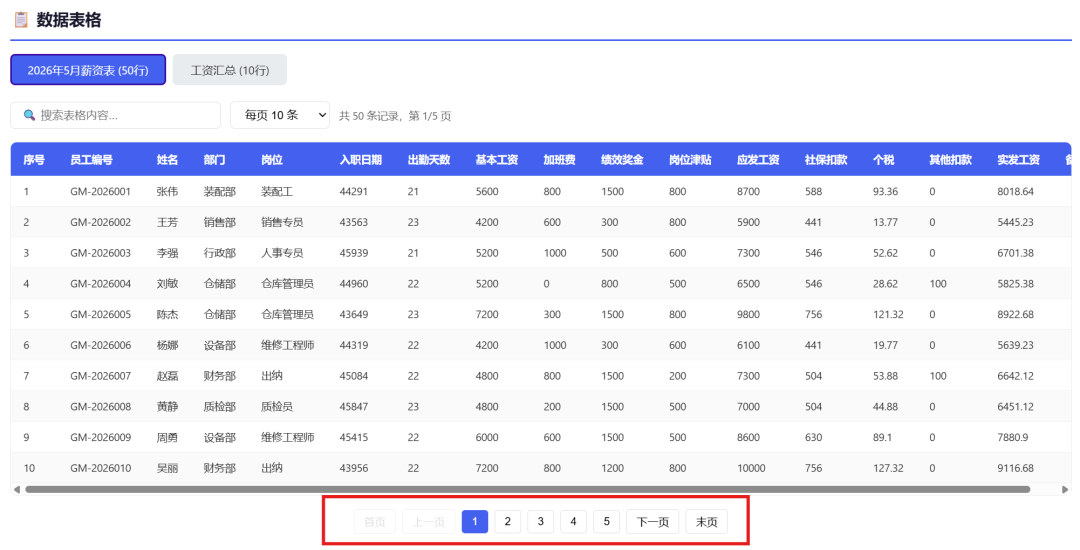
下面是数据统计预览:
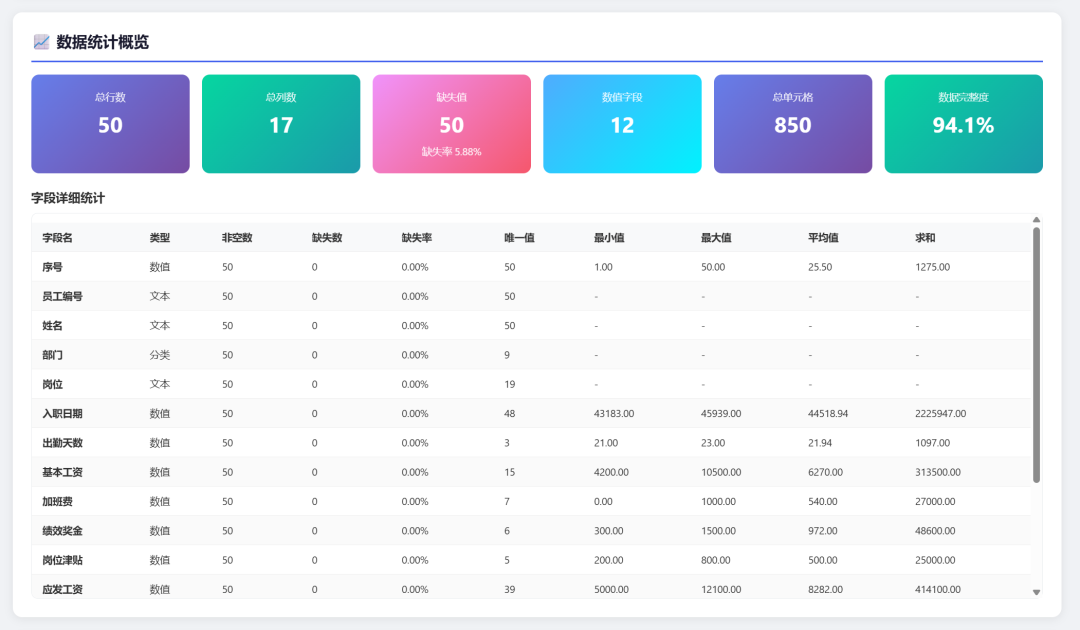
生成的图表:
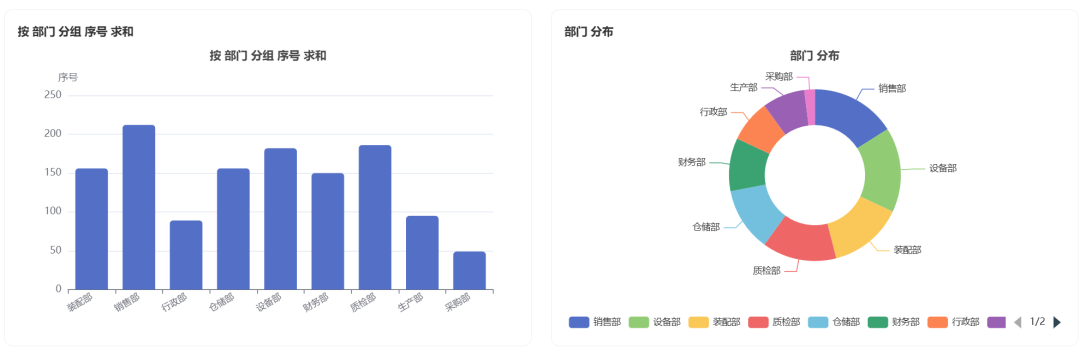
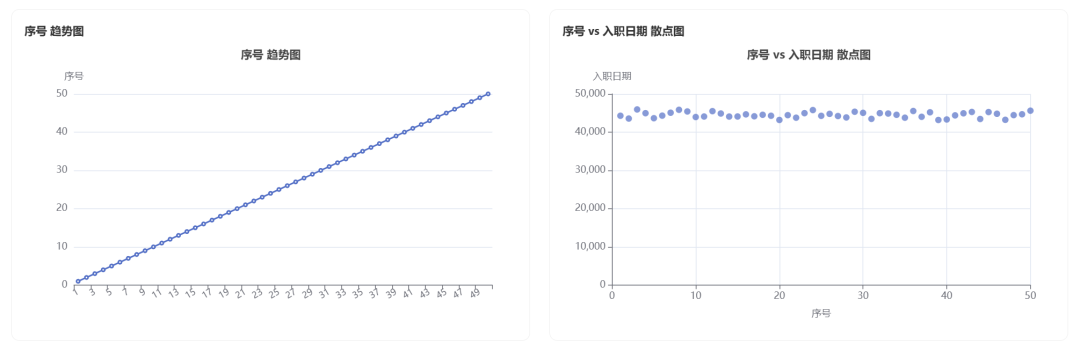
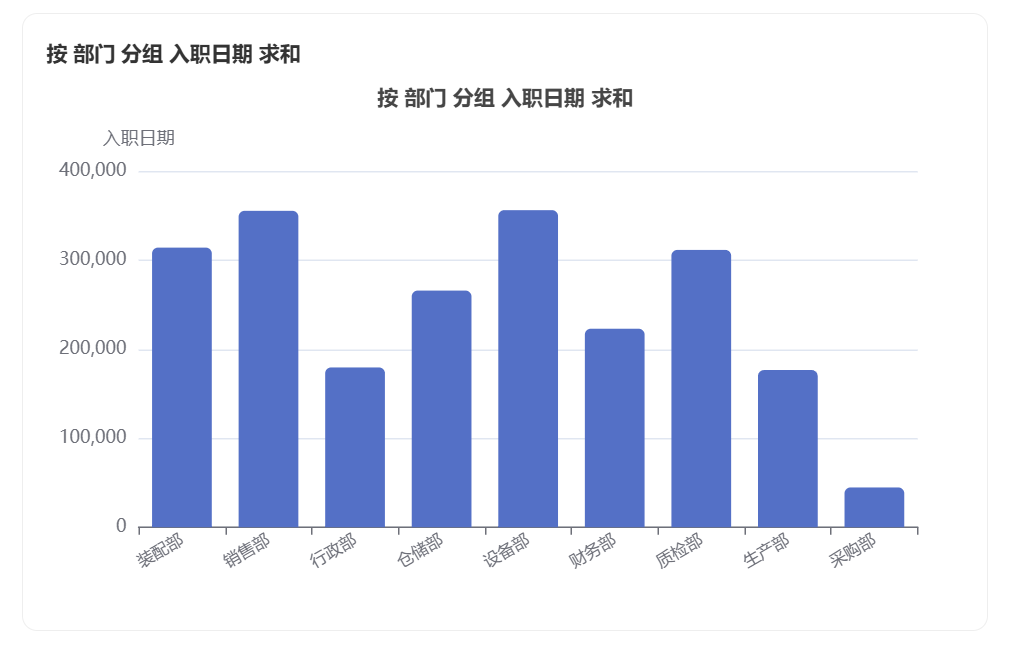
部分数据报告:
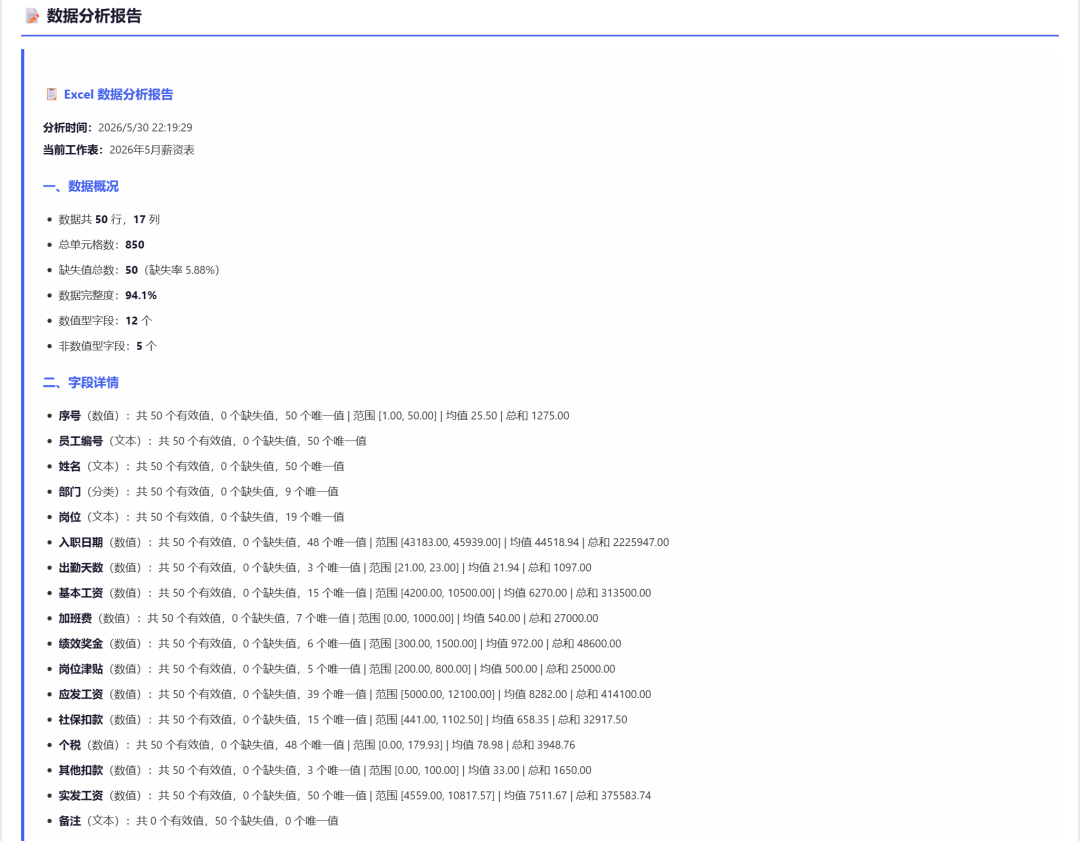
同样任务发给 Opus 4.8,打开html文件:

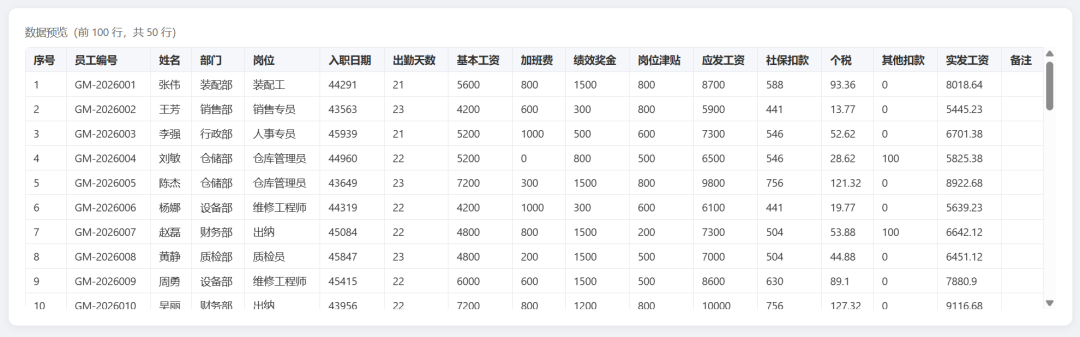
数据预览:
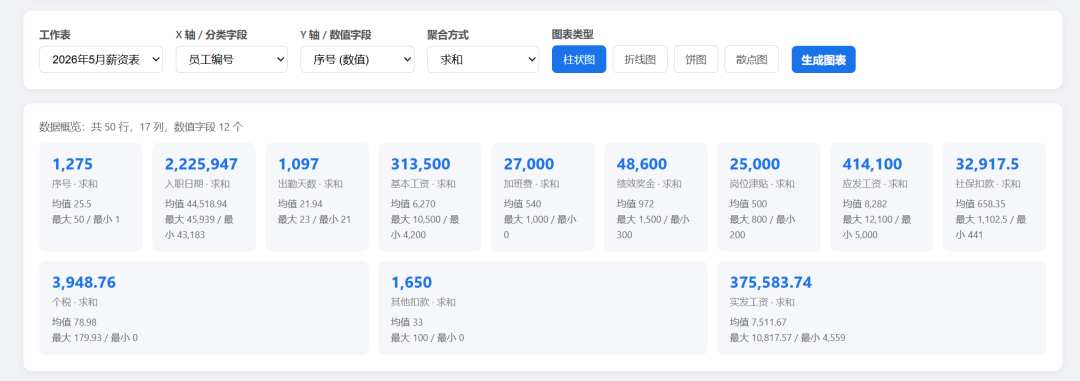
数据概览:
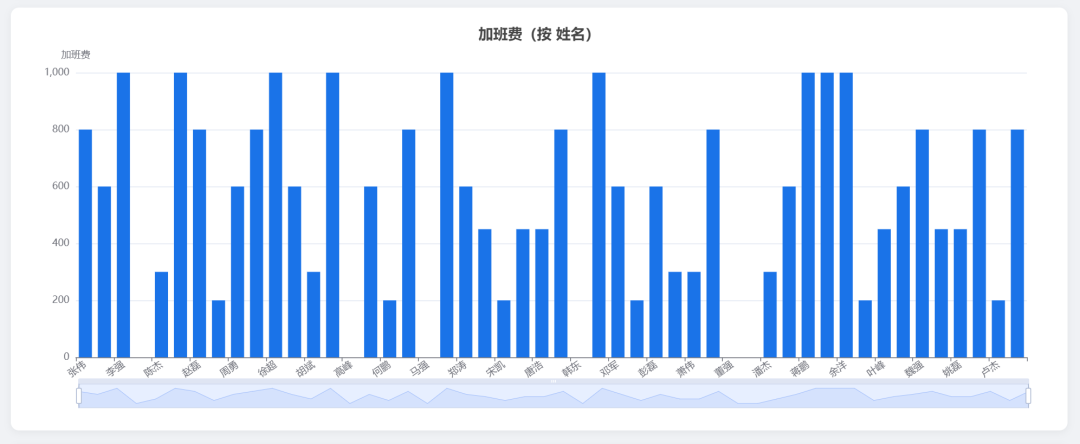
柱状图:
折线图:
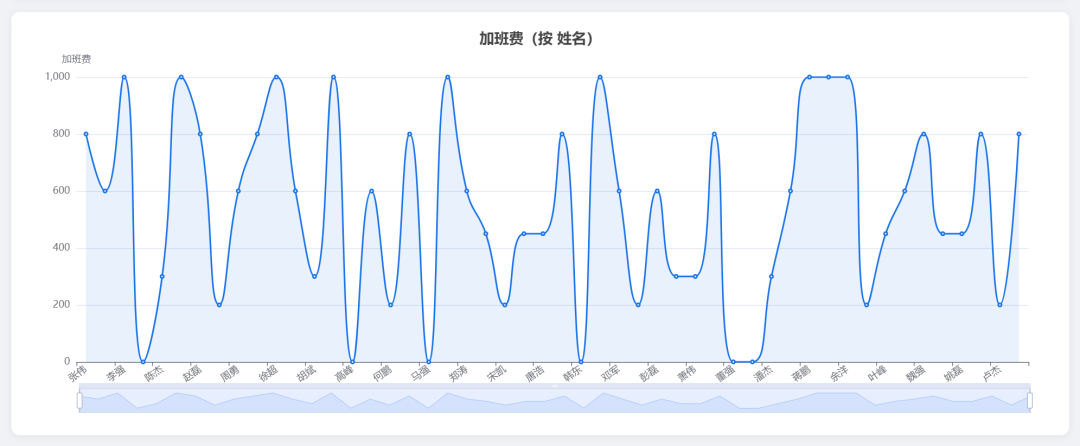
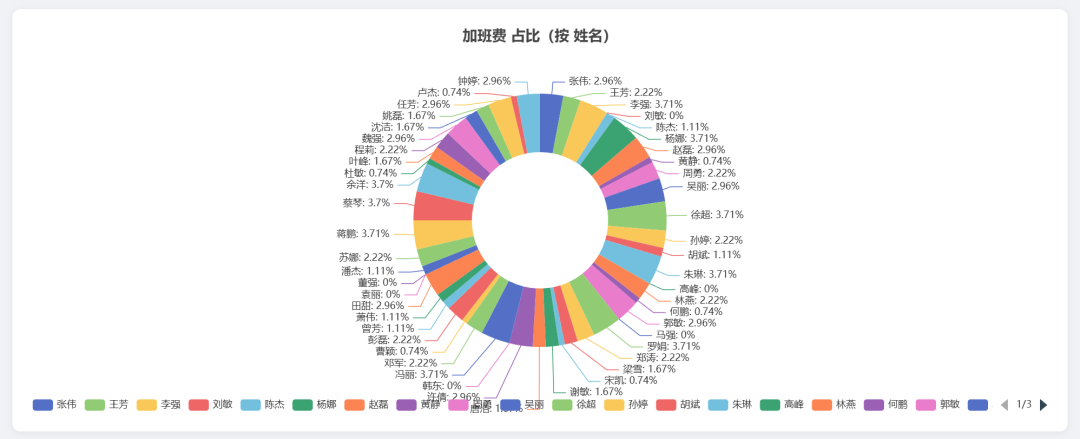
饼图:
同样任务发给:DeepSeek-V4-Pro,如下图所示:

双击打开html,显示如下:
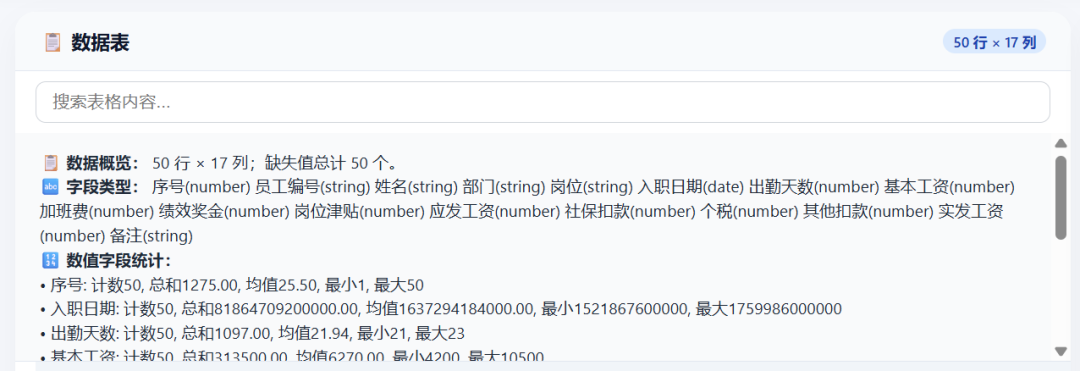
加载Excel后,数据预览,字段类型,统计:
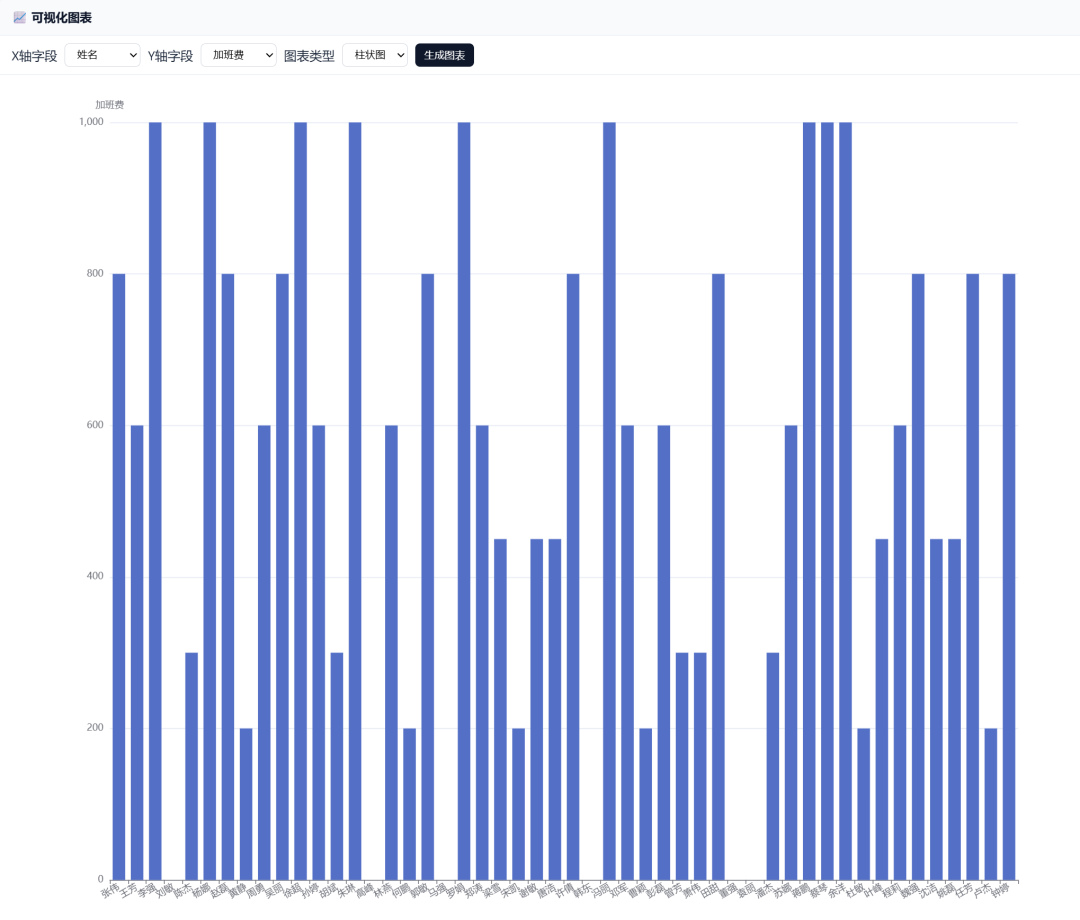
柱状图:
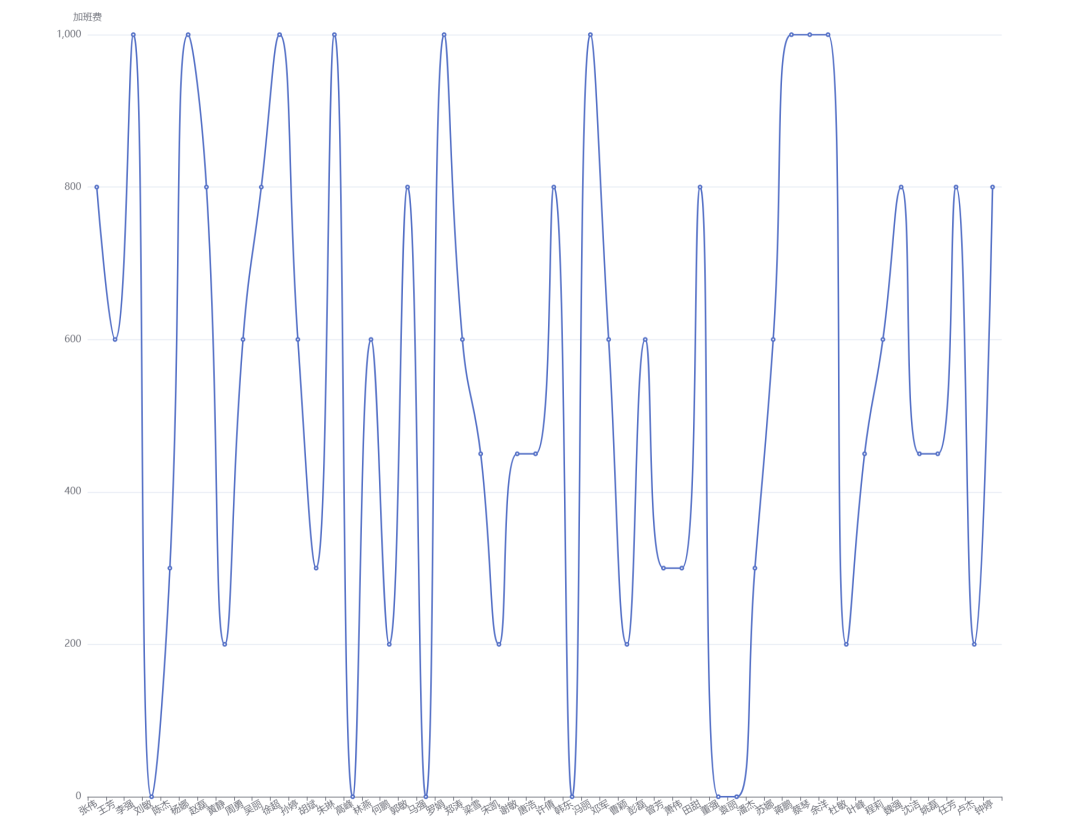
折线图:
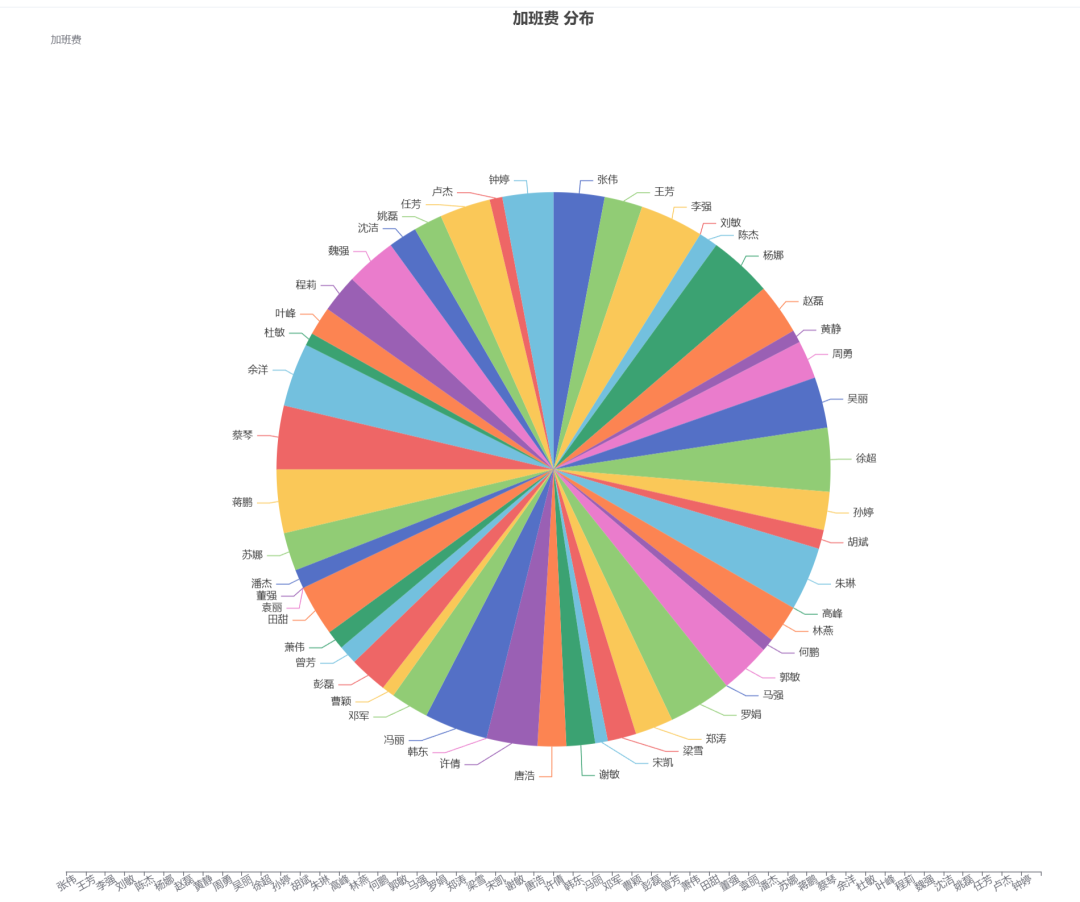
饼图:
3 裁判打分
为了更加客观,交给裁判Gemini-3.5-flash模型,评估如下图所示:
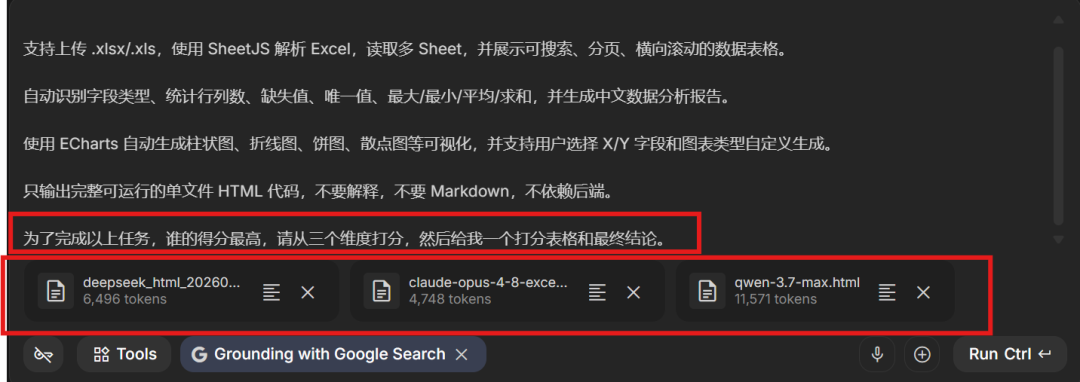
这是Gemini-3.5-Flash使用的三个打分维度:
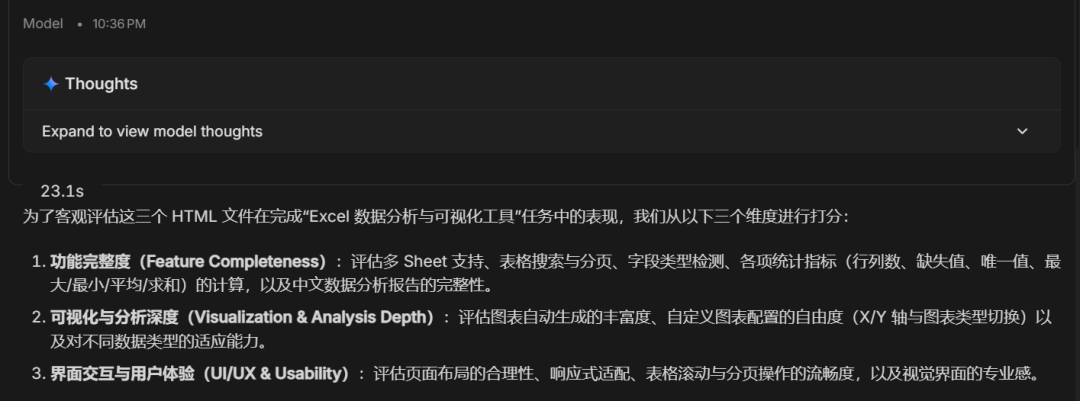
最终打分:
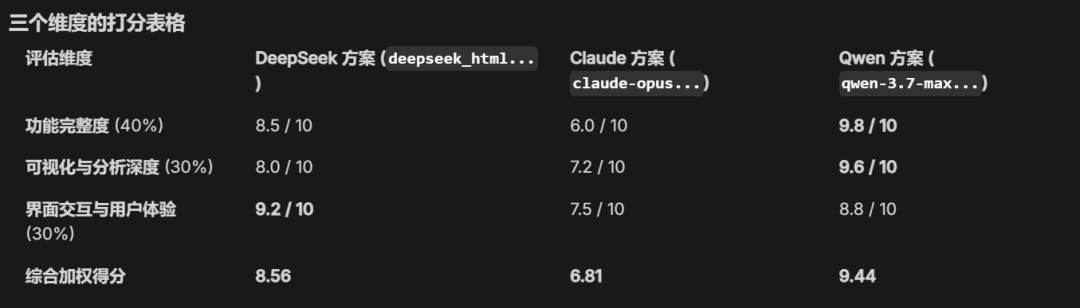
Claude Opus 4.8,竟然得分只有6.8,位于最后一名,
而Qwen3.7-Max排到第一,得分高达9.44分,
让我相当意外,因为按照文章开头的排名,Opus 4.8应该是第一才对, 结果竟然没有Deep-V4-Pro得分高。
这是为什么?再让裁判点评下:
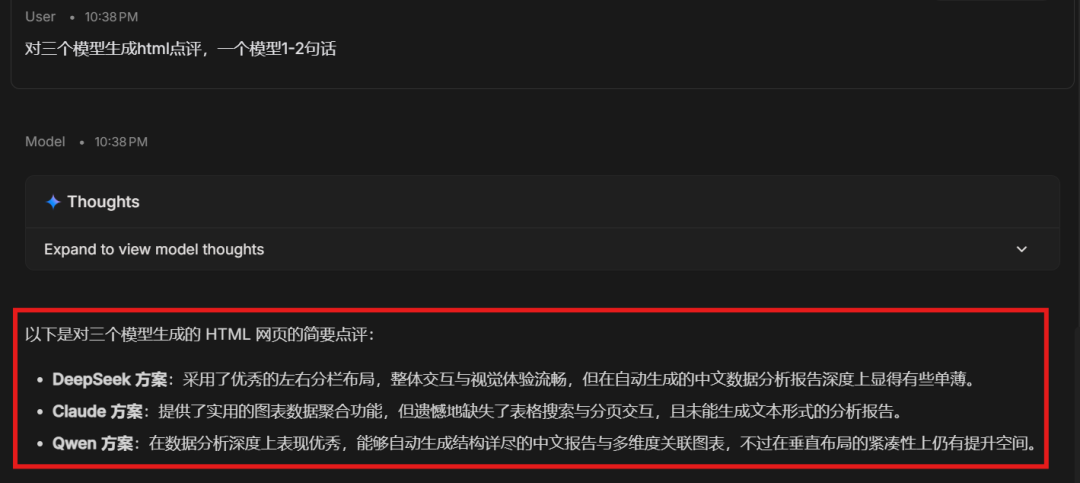
DeepSeek 方案采用了优秀的左右分栏布局,整体交互与视觉体验流畅,但在自动生成的中文数据分析报告深度上显得有些单薄。
Claude 方案:提供了实用的图表数据聚合功能,但遗憾地缺失了表格搜索与分页交互,且未能生成文本形式的分析报告。
Qwen 方案:在数据分析深度上表现优秀,能够自动生成结构详尽的中文报告与多维度关联图表,不过在垂直布局的紧凑性上仍有提升空间。
原来Claude缺失了很多项内容,完成度很差。
这太让人意外了,是不是裁判有问题,再请GPT-5.5当裁判:
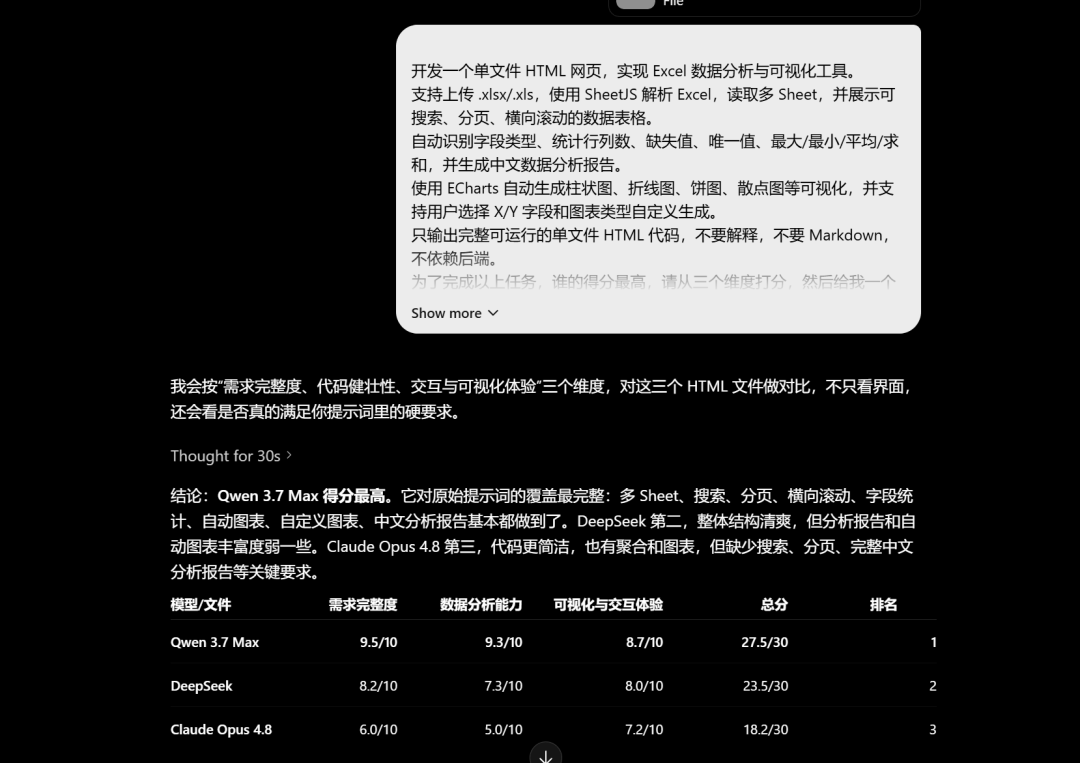
排名,依然没变,还是Qwen3.7-Max第一,DeepSeek第二,Claude Opus 4.8第三
以下是GPT-5.5给出的具体解释:

至此,可以下结论:就这个Agent任务,Opus 4.8确实表现很拉
总结一下
模型好不好,不能只看排名,更不能只看名气,而是要看它在实际生产中的表现。
本文实测的任务,GPT-5.5也明确这是一个比较典型的中小型Agent任务:

就本次中小型Agent任务,Qwen3.7-Max第一,DeepSeek-V4-Pro第二,Claude Opus 4.8第三。
这还是比较出乎我的意料!虽然只是一个测试,但也有一定代表性,再复杂的Agent任务测试,我后面尝试再验证下。
常见问题
实测最新 Qwen3.7-Max,对比 Claude O…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
实测最新 Qwen3.7-Max,对比 Claude O…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
实测最新 Qwen3.7-Max,对比 Claude O…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容