Gemma4 12B 本地部署实测:Ollama 笔记本运行与 Agent 能力
你好,我是郭震
最近,谷歌发布Gemma4 12B模型,让人眼前一亮!
12B,中杯尺寸,但也能在16G内存本跑起来。
而且,它是一个多模态全能Agent,支持理解图片、音频、视频文件。
这两天实测了下,感兴趣的可以看看。
1 本地部署
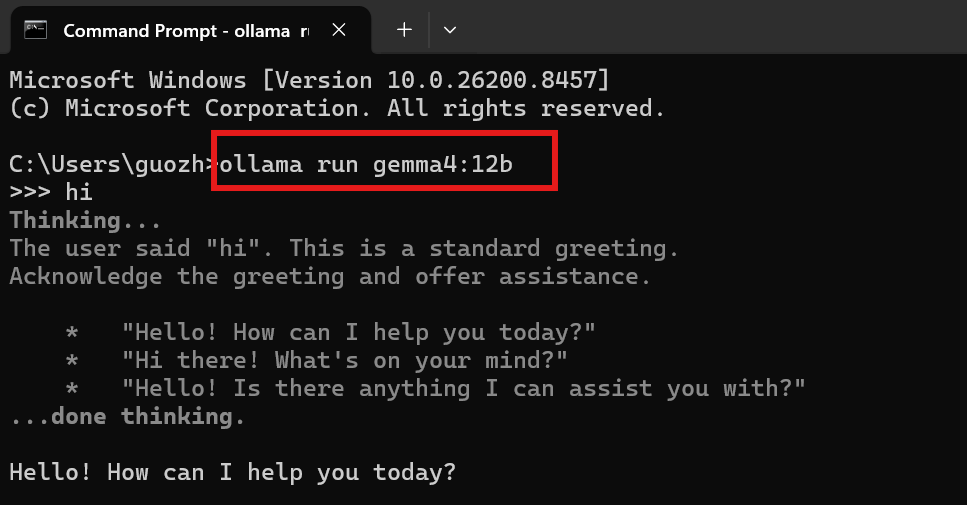
本地跑Gemma4 12B,最简单方法之一,使用ollama
下面一行命令:
看到它是标准4位量化(Q4_K_M)版本:
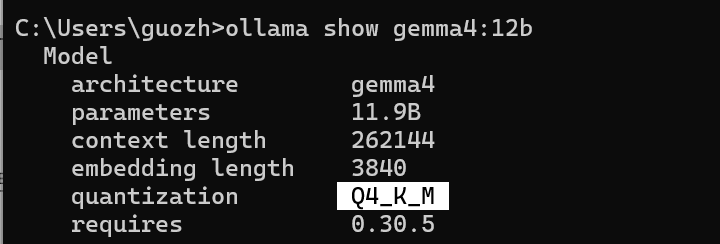
并且上下文可以达到262K,很不错,也为本地长对话能力提供支撑。
按照开发文档,16G内存就可以跑,比如Mac电脑M1,到M5都可以跑。
接下来,实测推理速度。
5090单卡,从提问到看到首Token(也就是TTFT),20轮下来,平均2.33秒:
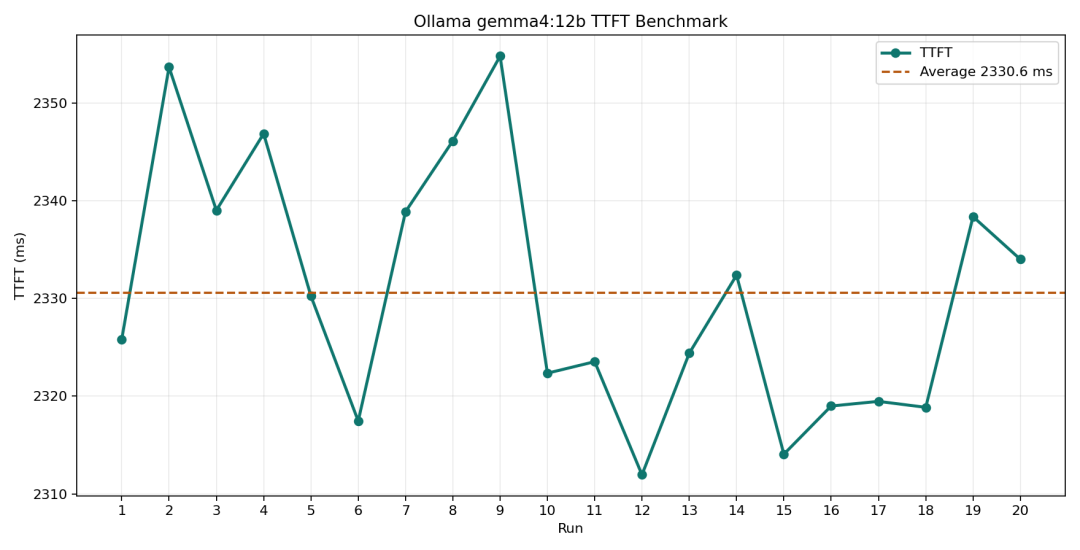
2.33秒,属于良好的水平,而且非常稳定。
平均每秒钟输出107.7 tokens,录制了一个GIF,感受下推理速度:

这对 12B级别,Ollama 本地推理来说,107.7 tokens/s,已经属于很流畅的水平。
因此不管从TTFT,而且每秒tokens速度,都是不错的。
2 Agent 实测
接下来把它接入到知识库中,看看本地干活好用吗。
首先安装DeepLocals,获取地址:
https://deeplocals.com/download
安装后,开箱即用!
DeepLocals支持本地大模型的丝滑接入,配置为:Gemma4:12b
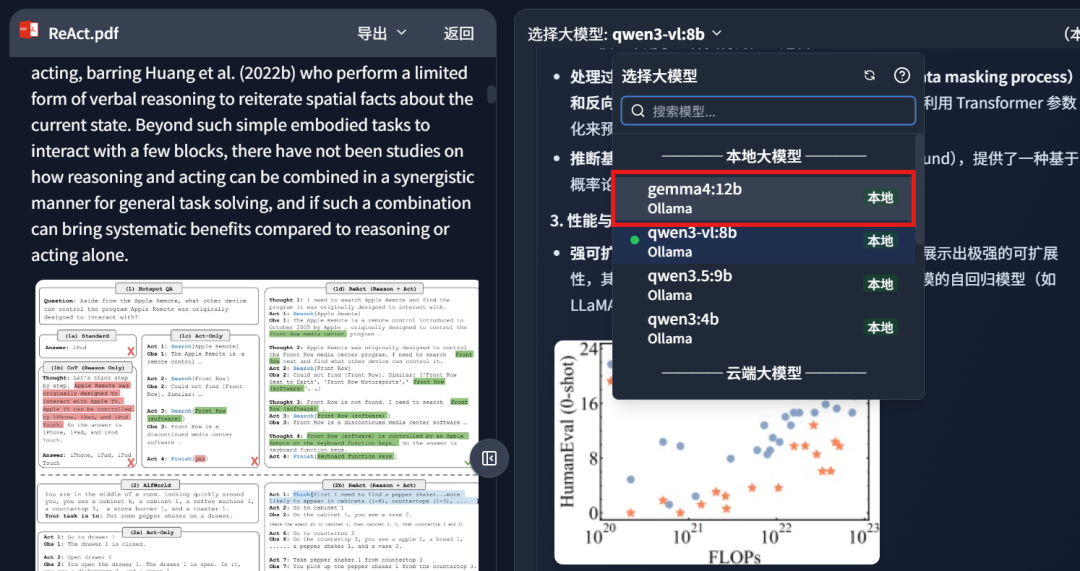
配置后,直接就可以在本地对我们的文件,如论文,合同,文书,做本地检索增强问题,更懂我们的AI
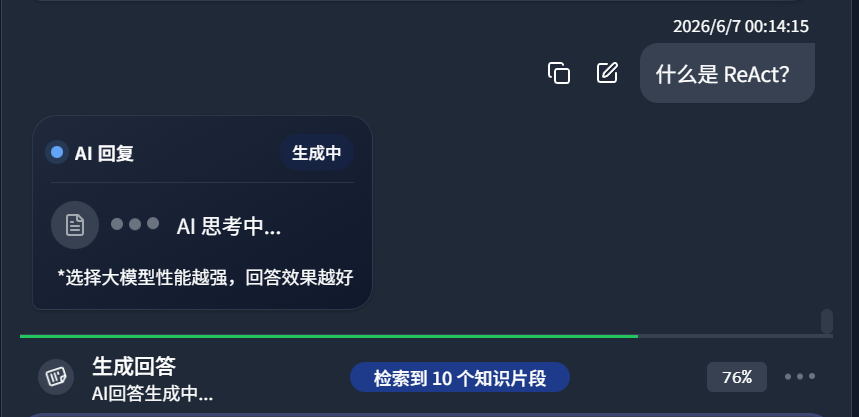
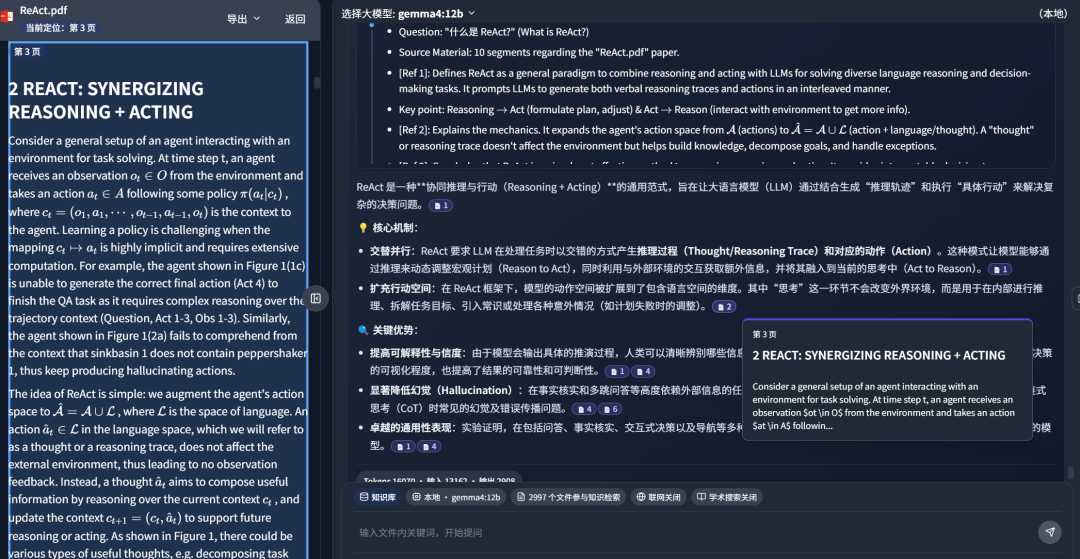
如下图所示,DeepLocals会从左侧学习到的海量本地文件中,检索到了10个知识片段:
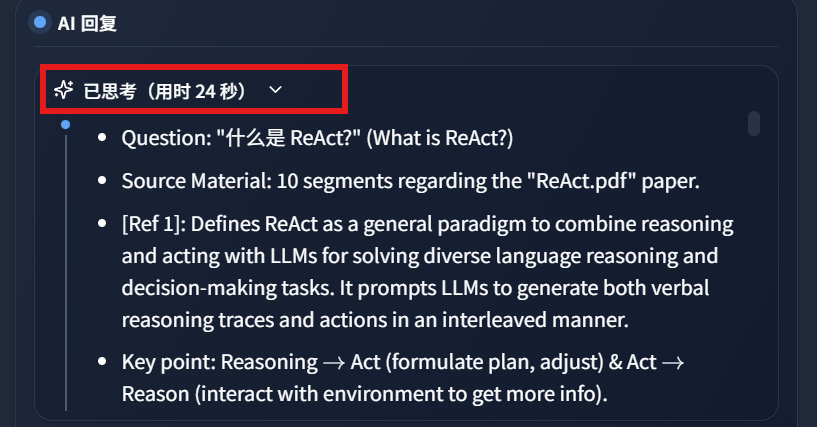
Gemma4:12B 如下思考24秒:
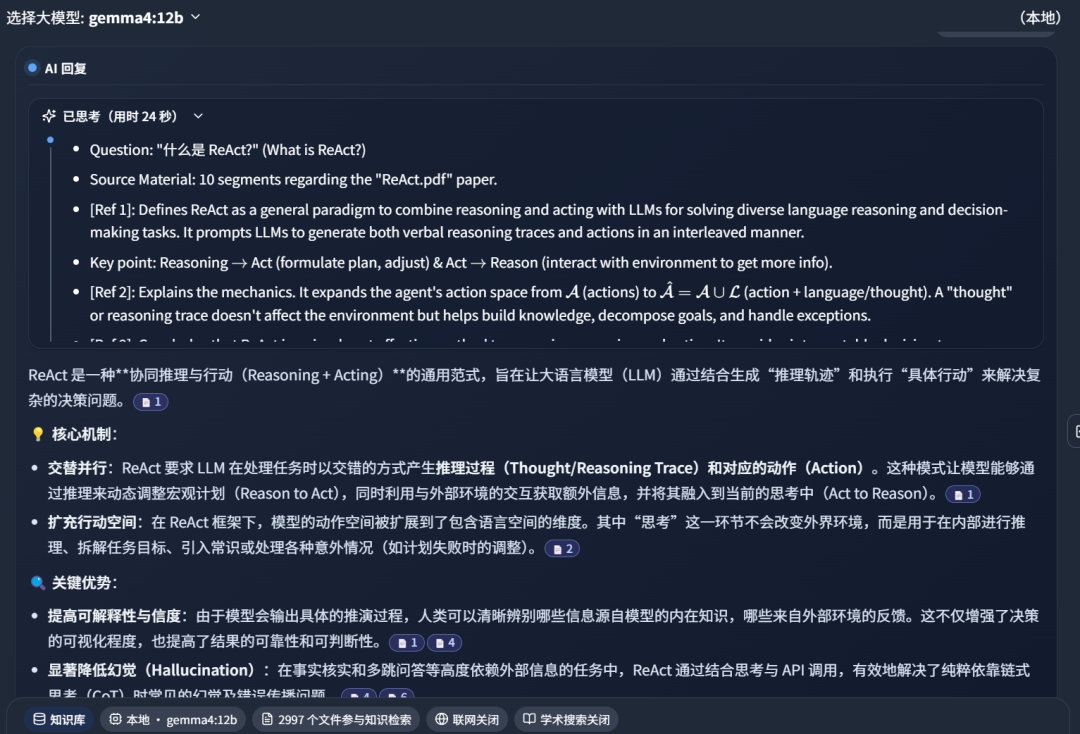
回答结果如下所示:
点击参考源,直接定位到相关论文片段:
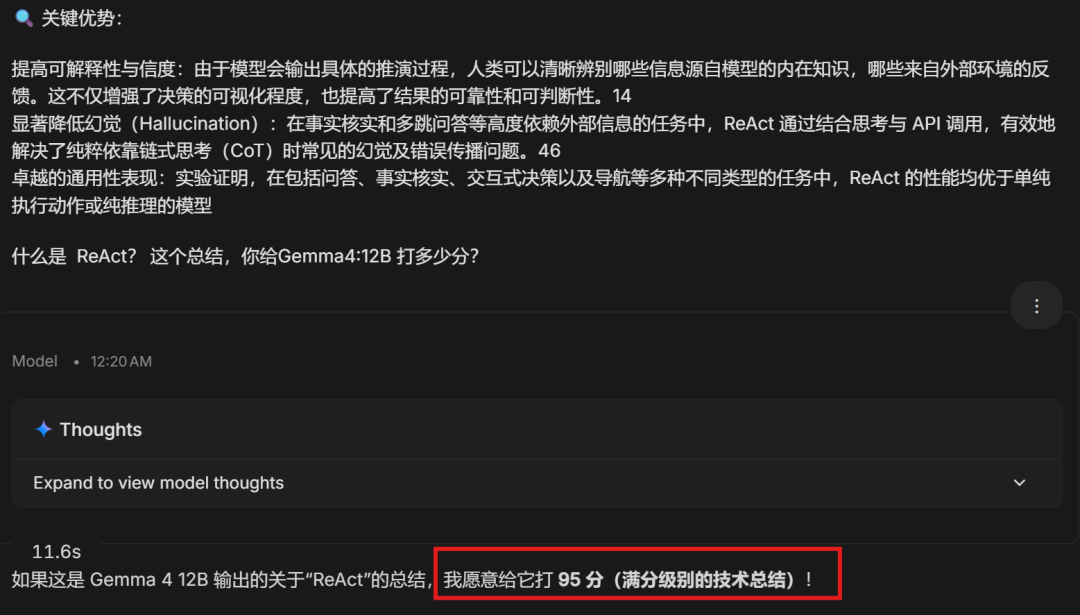
这个总结Gemini-3.1-Pro给出了95分的高分:
点击导出Word,含引用版:
导出Word文档:
3 多模态能力
Gemma4:12B是一个统一的多模态模型,无视觉编码器,显存使用更好。
接下来测试它的图片理解能力如何,如下点击箭头所示,上传本地文件:
上传这篇Transformer这篇论文:
DeepLocals 开始生成论文总结:
如下部分截图:
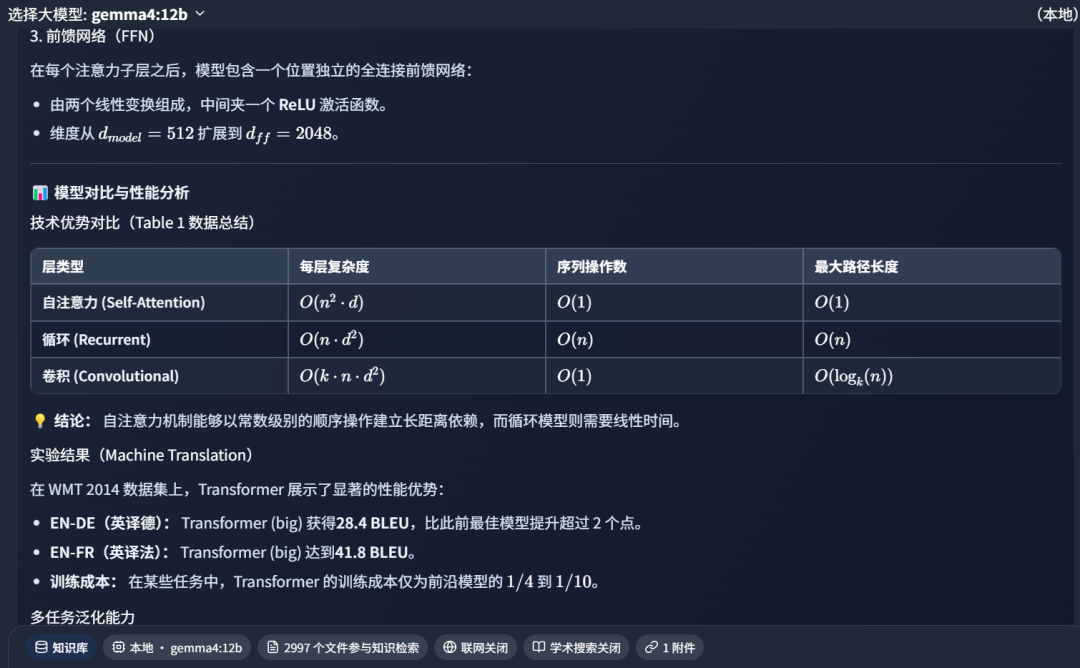
上面总结发给Gemini3.1-Pro,它给出了98分:
发送这样一张图片给Gemma4:12B,看看它的多模态能力:
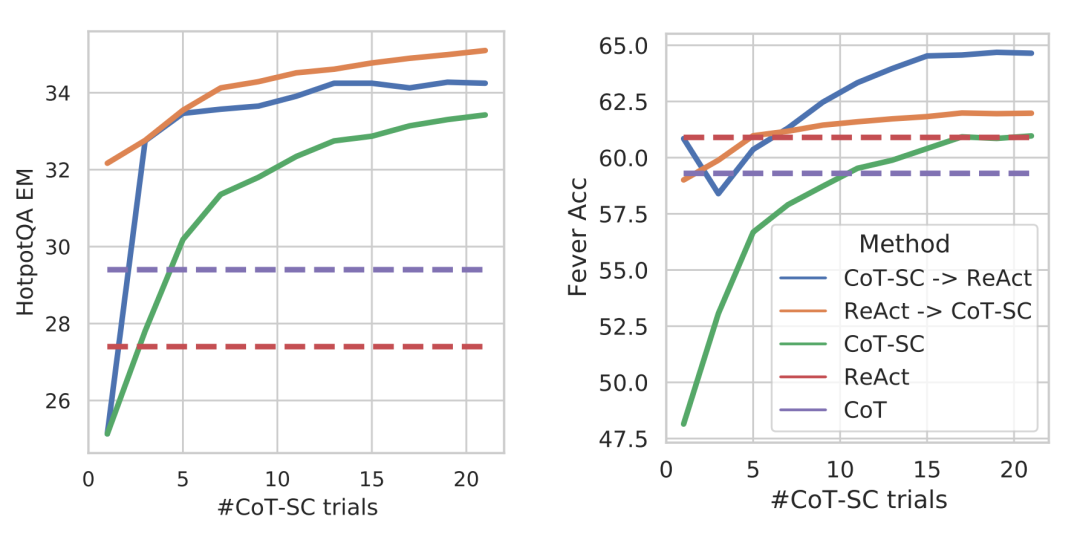
发给DeepLocals:
Gemma4:12B 的回答:

Gemini3.1-Pro给出90-95分:
这个测试证明了,它能看懂学术论文里最难搞的** 复杂数据对比。**
最后总结一下
** 本篇实测下来,感觉Gemma4 12B 这次确实把本地 AI 的体验拉到了一个新高度。**
** 12B 这个体量,刚好卡在 16G 内存的舒适区。**
** 最实在的是,原生的多模态让它真能帮你干脏活累活。就算拔了网线,那些晦涩的英文 PDF 和复杂的实验折线图,它也能给你扒得明明白白。**
** 对于咱们这种看重数据隐私,又想在本地白嫖一个“全能助理”的人来说,没啥好纠结的,直接折腾起来就对了。**
常见问题
Gemma4 12B 本地部署实测:Ollama 笔记本…测了什么?
看 AI消息 的实际效果、使用门槛和结果表现。
Gemma4 12B 本地部署实测:Ollama 笔记本…适合谁看?
适合正在选工具、做本地部署或验证 AI 工作流的人。
Gemma4 12B 本地部署实测:Ollama 笔记本…要注意什么?
重点看配置成本、失败点、数据边界和可替代方案。
相关内容